






















































Before diving into learning about maximum likelihood estimation (MLE) in HMMs, let's try to understand the basic concepts of MLE in generic cases. As the name suggests, MLE tries to select the parameters of the model that maximizes the likelihood of observed data. The likelihood for any model with given parameters is defined as the probability of getting the observed data, and can be written as follows:
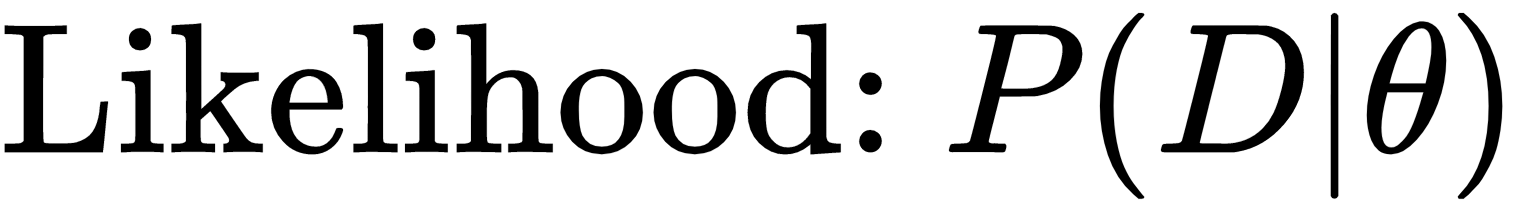
Here, D={D1, D2, D3, …, Dn} is the observed data, and θ is the set of parameters governing our model. In most cases, for simplicity, we assume that the datapoints are independent and identically distributed (IID). With that assumption, we can simplify the definition of our likelihood function as follows:
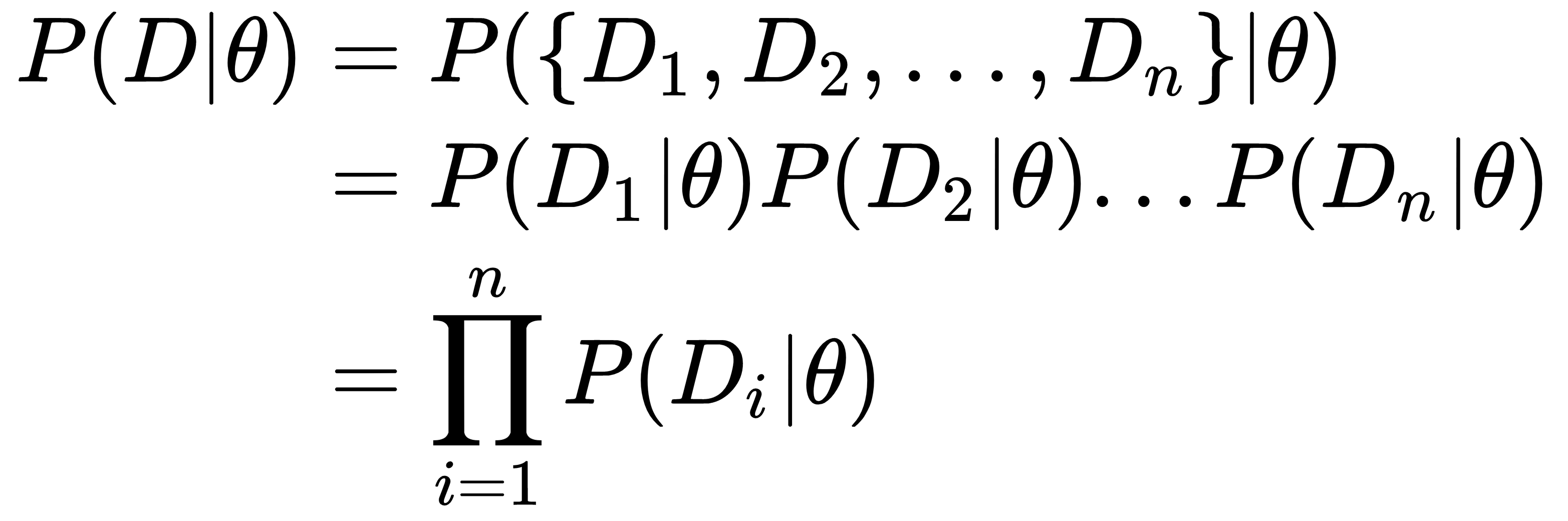
Here, we have used the multiplication rule for independent random variables to decompose the joint distribution into product...














