






















































Linux namespaces – the foundation of LXC
Namespaces are the foundation of lightweight process virtualization. They enable a process and its children to have different views of the underlying system. This is achieved by the addition of the unshare() and setns() system calls, and the inclusion of six new constant flags passed to the clone(), unshare(), and setns() system calls:
clone(): This creates a new process and attaches it to a new specified namespaceunshare(): This attaches the current process to a new specified namespacesetns(): This attaches a process to an already existing namespace
There are six namespaces currently in use by LXC, with more being developed:
- Mount namespaces, specified by the
CLONE_NEWNSflag - UTS namespaces, specified by the
CLONE_NEWUTSflag - IPC namespaces, specified by the
CLONE_NEWIPCflag - PID namespaces, specified by the
CLONE_NEWPIDflag - User namespaces, specified by the
CLONE_NEWUSERflag - Network namespaces, specified by the
CLONE_NEWNETflag
Let's have a look at each in more detail and see some userspace examples, to help us better understand what happens under the hood.
Mount namespaces
Mount namespaces first appeared in kernel 2.4.19 in 2002 and provided a separate view of the filesystem mount points for the process and its children. When mounting or unmounting a filesystem, the change will be noticed by all processes because they all share the same default namespace. When the CLONE_NEWNS flag is passed to the clone() system call, the new process gets a copy of the calling process mount tree that it can then change without affecting the parent process. From that point on, all mounts and unmounts in the default namespace will be visible in the new namespace, but changes in the per-process mount namespaces will not be noticed outside of it.
The clone() prototype is as follows:
#define _GNU_SOURCE
#include <sched.h>
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);
An example call that creates a child process in a new mount namespace looks like this:
child_pid = clone(childFunc, child_stack + STACK_SIZE, CLONE_NEWNS | SIGCHLD, argv[1]);
When the child process is created, it executes the childFunc function, which will perform its work in the new mount namespace.
The util-linux package provides userspace tools that implement the unshare() call, which effectively unshares the indicated namespaces from the parent process.
To illustrate this:
- First open a terminal and create a directory in
/tmpas follows:root@server:~# mkdir /tmp/mount_ns root@server:~#
- Next, move the current
bashprocess to its own mount namespace by passing the mount flag tounshare:root@server:~# unshare -m /bin/bash root@server:~#
- The
bashprocess is now in a separate namespace. Let's check the associated inode number of the namespace:root@server:~# readlink /proc/$$/ns/mnt mnt:[4026532211] root@server:~#
- Next, create a temporary mount point:
root@server:~# mount -n -t tmpfs tmpfs /tmp/mount_ns root@server:~#
- Also, make sure you can see the mount point from the newly created namespace:
root@server:~# df -h | grep mount_ns tmpfs 3.9G 0 3.9G 0% /tmp/mount_ns root@server:~# cat /proc/mounts | grep mount_ns tmpfs /tmp/mount_ns tmpfs rw,relatime 0 0 root@server:~#
As expected, the mount point is visible because it is part of the namespace we created and the current
bashprocess is running from. - Next, start a new terminal session and display the namespace inode ID from it:
root@server:~# readlink /proc/$$/ns/mnt mnt:[4026531840] root@server:~#
Notice how it's different from the mount namespace on the other terminal.
- Finally, check if the mount point is visible in the new terminal:
root@server:~# cat /proc/mounts | grep mount_ns root@server:~# df -h | grep mount_ns root@server:~#
Not surprisingly, the mount point is not visible from the default namespace.
Note
In the context of LXC, mount namespaces are useful because they provide a way for a different filesystem layout to exist inside the container. It's worth mentioning that before the mount namespaces, a similar process confinement could be achieved with the chroot() system call, however chroot does not provide the same per-process isolation as mount namespaces do.
UTS namespaces
Unix Timesharing (UTS) namespaces provide isolation for the hostname and domain name, so that each LXC container can maintain its own identifier as returned by the hostname -f command. This is needed for most applications that rely on a properly set hostname.
To create a bash session in a new UTS namespace, we can use the unshare utility again, which uses the unshare() system call to create the namespace and the execve() system call to execute bash in it:
root@server:~# hostname server root@server:~# unshare -u /bin/bash root@server:~# hostname uts-namespace root@server:~# hostname uts-namespace root@server:~# cat /proc/sys/kernel/hostname uts-namespace root@server:~#
As the preceding output shows, the hostname inside the namespace is now uts-namespace.
Next, from a different terminal, check the hostname again to make sure it has not changed:
root@server:~# hostname server root@server:~#
As expected, the hostname only changed in the new UTS namespace.
To see the actual system calls that the unshare command uses, we can run the strace utility:
root@server:~# strace -s 2000 -f unshare -u /bin/bash ... unshare(CLONE_NEWUTS) = 0 getgid() = 0 setgid(0) = 0 getuid() = 0 setuid(0) = 0 execve("/bin/bash", ["/bin/bash"], [/* 15 vars */]) = 0 ...
From the output we can see that the unshare command is indeed using the unshare() and execve() system calls and the CLONE_NEWUTS flag to specify new UTS namespace.
IPC namespaces
The Interprocess Communication (IPC) namespaces provide isolation for a set of IPC and synchronization facilities. These facilities provide a way of exchanging data and synchronizing the actions between threads and processes. They provide primitives such as semaphores, file locks, and mutexes among others, that are needed to have true process separation in a container.
PID namespaces
The Process ID (PID) namespaces provide the ability for a process to have an ID that already exists in the default namespace, for example an ID of 1. This allows for an init system to run in a container with various other processes, without causing a collision with the rest of the PIDs on the same OS.
To demonstrate this concept, open up pid_namespace.c:
#define _GNU_SOURCE
#include <stdlib.h>
#include <stdio.h>
#include <signal.h>
#include <sched.h>
static int childFunc(void *arg)
{
printf("Process ID in child = %ld\n", (long) getpid());
}
First, we include the headers and define the childFunc function that the clone() system call will use. The function prints out the child PID using the getpid() system call:
static char child_stack[1024*1024];
int main(int argc, char *argv[])
{
pid_t child_pid;
child_pid = clone(childFunc, child_stack +
(1024*1024),
CLONE_NEWPID | SIGCHLD, NULL);
printf("PID of cloned process: %ld\n", (long) child_pid);
waitpid(child_pid, NULL, 0);
exit(EXIT_SUCCESS);
}
In the main() function, we specify the stack size and call clone(), passing the child function childFunc, the stack pointer, the CLONE_NEWPID flag, and the SIGCHLD signal. The CLONE_NEWPID flag instructs clone() to create a new PID namespace and the SIGCHLD flag notifies the parent process when one of its children terminates. The parent process will block on waitpid() if the child process has not terminated.
Compile and then run the program with the following:
root@server:~# gcc pid_namespace.c -o pid_namespace root@server:~# ./pid_namespace PID of cloned process: 17705 Process ID in child = 1 root@server:~#
From the output, we can see that the child process has a PID of 1 inside its namespace and 17705 otherwise.
Note
Note that error handling has been omitted from the code examples for brevity.
User namespaces
The user namespaces allow a process inside a namespace to have a different user and group ID than that in the default namespace. In the context of LXC, this allows for a process to run as root inside the container, while having a non-privileged ID outside. This adds a thin layer of security, because braking out for the container will result in a non-privileged user. This is possible because of kernel 3.8, which introduced the ability for non-privileged processes to create user namespaces.
To create a new user namespace as a non-privileged user and have root inside, we can use the unshare utility. Let's install the latest version from source:
root@ubuntu:~# cd /usr/src/ root@ubuntu:/usr/src# wget https://www.kernel.org/pub/linux/utils/util-linux/v2.28/util-linux-2.28.tar.gz root@ubuntu:/usr/src# tar zxfv util-linux-2.28.tar.gz root@ubuntu:/usr/src# cd util-linux-2.28/ root@ubuntu:/usr/src/util-linux-2.28# ./configure root@ubuntu:/usr/src/util-linux-2.28# make && make install root@ubuntu:/usr/src/util-linux-2.28# unshare --map-root-user --user sh -c whoami root root@ubuntu:/usr/src/util-linux-2.28#
We can also use the clone() system call with the CLONE_NEWUSER flag to create a process in a user namespace, as demonstrated by the following program:
#define _GNU_SOURCE
#include <stdlib.h>
#include <stdio.h>
#include <signal.h>
#include <sched.h>
static int childFunc(void *arg)
{
printf("UID inside the namespace is %ld\n", (long)
geteuid());
printf("GID inside the namespace is %ld\n", (long)
getegid());
}
static char child_stack[1024*1024];
int main(int argc, char *argv[])
{
pid_t child_pid;
child_pid = clone(childFunc, child_stack +
(1024*1024),
CLONE_NEWUSER | SIGCHLD, NULL);
printf("UID outside the namespace is %ld\n", (long)
geteuid());
printf("GID outside the namespace is %ld\n", (long)
getegid());
waitpid(child_pid, NULL, 0);
exit(EXIT_SUCCESS);
}
After compilation and execution, the output looks similar to this when run as root - UID of 0:
root@server:~# gcc user_namespace.c -o user_namespace root@server:~# ./user_namespace UID outside the namespace is 0 GID outside the namespace is 0 UID inside the namespace is 65534 GID inside the namespace is 65534 root@server:~#
Network namespaces
Network namespaces provide isolation of the networking resources, such as network devices, addresses, routes, and firewall rules. This effectively creates a logical copy of the network stack, allowing multiple processes to listen on the same port from multiple namespaces. This is the foundation of networking in LXC and there are quite a lot of other use cases where this can come in handy.
The iproute2 package provides very useful userspace tools that we can use to experiment with the network namespaces, and is installed by default on almost all Linux systems.
There's always the default network namespace, referred to as the root namespace, where all network interfaces are initially assigned. To list the network interfaces that belong to the default namespace run the following command:
root@server:~# ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 0e:d5:0e:b0:a3:47 brd ff:ff:ff:ff:ff:ff root@server:~#
In this case, there are two interfaces – lo and eth0.
To list their configuration, we can run the following:
root@server:~# ip a s 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc pfifo_fast state UP group default qlen 1000 link/ether 0e:d5:0e:b0:a3:47 brd ff:ff:ff:ff:ff:ff inet 10.1.32.40/24 brd 10.1.32.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::cd5:eff:feb0:a347/64 scope link valid_lft forever preferred_lft forever root@server:~#
Also, to list the routes from the root network namespace, execute the following:
root@server:~# ip r s default via 10.1.32.1 dev eth0 10.1.32.0/24 dev eth0 proto kernel scope link src 10.1.32.40 root@server:~#
Let's create two new network namespaces called ns1 and ns2 and list them:
root@server:~# ip netns add ns1 root@server:~# ip netns add ns2 root@server:~# ip netns ns2 ns1 root@server:~#
Now that we have the new network namespaces, we can execute commands inside them:
root@server:~# ip netns exec ns1 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
root@server:~#
The preceding output shows that in the ns1 namespace, there's only one network interface, the loopback - lo interface, and it's in a DOWN state.
We can also start a new bash session inside the namespace and list the interfaces in a similar way:
root@server:~# ip netns exec ns1 bash root@server:~# ip link 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 root@server:~# exit root@server:~#
This is more convenient for running multiple commands than specifying each, one at a time. The two network namespaces are not of much use if not connected to anything, so let's connect them to each other. To do this we'll use a software bridge called Open vSwitch.
Open vSwitch works just as a regular network bridge and then it forwards frames between virtual ports that we define. Virtual machines such as KVM, Xen, and LXC or Docker containers can then be connected to it.
Most Debian-based distributions such as Ubuntu provide a package, so let's install that:
root@server:~# apt-get install -y openvswitch-switch root@server:~#
This installs and starts the Open vSwitch daemon. Time to create the bridge; we'll name it OVS-1:
root@server:~# ovs-vsctl add-br OVS-1 root@server:~# ovs-vsctl show 0ea38b4f-8943-4d5b-8d80-62ccb73ec9ec Bridge "OVS-1" Port "OVS-1" Interface "OVS-1" type: internal ovs_version: "2.0.2" root@server:~#
Note
If you would like to experiment with the latest version of Open vSwitch, you can download the source code from http://openvswitch.org/download/ and compile it.
The newly created bridge can now be seen in the root namespace:
root@server:~# ip a s OVS-1 4: OVS-1: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default link/ether 9a:4b:56:97:3b:46 brd ff:ff:ff:ff:ff:ff inet6 fe80::f0d9:78ff:fe72:3d77/64 scope link valid_lft forever preferred_lft forever root@server:~#
In order to connect both network namespaces, let's first create a virtual pair of interfaces for each namespace:
root@server:~# ip link add eth1-ns1 type veth peer name veth-ns1 root@server:~# ip link add eth1-ns2 type veth peer name veth-ns2 root@server:~#
The preceding two commands create four virtual interfaces eth1-ns1, eth1-ns2 and veth-ns1, veth-ns2. The names are arbitrary.
To list all interfaces that are part of the root network namespace, run:
root@server:~# ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 0e:d5:0e:b0:a3:47 brd ff:ff:ff:ff:ff:ff 3: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default link/ether 82:bf:52:d3:de:7e brd ff:ff:ff:ff:ff:ff 4: OVS-1: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default link/ether 9a:4b:56:97:3b:46 brd ff:ff:ff:ff:ff:ff 5: veth-ns1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 1a:7c:74:48:73:a9 brd ff:ff:ff:ff:ff:ff 6: eth1-ns1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 8e:99:3f:b8:43:31 brd ff:ff:ff:ff:ff:ff 7: veth-ns2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 5a:0d:34:87:ea:96 brd ff:ff:ff:ff:ff:ff 8: eth1-ns2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether fa:71:b8:a1:7f:85 brd ff:ff:ff:ff:ff:ff root@server:~#
Let's assign the eth1-ns1 and eth1-ns2 interfaces to the ns1 and ns2 namespaces:
root@server:~# ip link set eth1-ns1 netns ns1 root@server:~# ip link set eth1-ns2 netns ns2
Also, confirm they are visible from inside each network namespace:
root@server:~# ip netns exec ns1 ip link 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 6: eth1-ns1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 8e:99:3f:b8:43:31 brd ff:ff:ff:ff:ff:ff root@server:~# root@server:~# ip netns exec ns2 ip link 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 8: eth1-ns2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether fa:71:b8:a1:7f:85 brd ff:ff:ff:ff:ff:ff root@server:~#
Notice, how each network namespace now has two interfaces assigned – loopback and eth1-ns*.
If we list the devices from the root namespace, we should see that the interfaces we just moved to ns1 and ns2 namespaces are no longer visible:
root@server:~# ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 0e:d5:0e:b0:a3:47 brd ff:ff:ff:ff:ff:ff 3: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default link/ether 82:bf:52:d3:de:7e brd ff:ff:ff:ff:ff:ff 4: OVS-1: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default link/ether 9a:4b:56:97:3b:46 brd ff:ff:ff:ff:ff:ff 5: veth-ns1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 1a:7c:74:48:73:a9 brd ff:ff:ff:ff:ff:ff 7: veth-ns2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 5a:0d:34:87:ea:96 brd ff:ff:ff:ff:ff:ff root@server:~#
It's time to connect the other end of the two virtual pipes, the veth-ns1 and veth-ns2 interfaces to the bridge:
root@server:~# ovs-vsctl add-port OVS-1 veth-ns1 root@server:~# ovs-vsctl add-port OVS-1 veth-ns2 root@server:~# ovs-vsctl show 0ea38b4f-8943-4d5b-8d80-62ccb73ec9ec Bridge "OVS-1" Port "OVS-1" Interface "OVS-1" type: internal Port "veth-ns1" Interface "veth-ns1" Port "veth-ns2" Interface "veth-ns2" ovs_version: "2.0.2" root@server:~#
From the preceding output, it's apparent that the bridge now has two ports, veth-ns1 and veth-ns2.
The last thing left to do is bring the network interfaces up and assign IP addresses:
root@server:~# ip link set veth-ns1 up root@server:~# ip link set veth-ns2 up root@server:~# ip netns exec ns1 ip link set dev lo up root@server:~# ip netns exec ns1 ip link set dev eth1-ns1 up root@server:~# ip netns exec ns1 ip address add 192.168.0.1/24 dev eth1-ns1 root@server:~# ip netns exec ns1 ip a s 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 6: eth1-ns1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 8e:99:3f:b8:43:31 brd ff:ff:ff:ff:ff:ff inet 192.168.0.1/24 scope global eth1-ns1 valid_lft forever preferred_lft forever inet6 fe80::8c99:3fff:feb8:4331/64 scope link valid_lft forever preferred_lft forever root@server:~#
Similarly for the ns2 namespace:
root@server:~# ip netns exec ns2 ip link set dev lo up root@server:~# ip netns exec ns2 ip link set dev eth1-ns2 up root@server:~# ip netns exec ns2 ip address add 192.168.0.2/24 dev eth1-ns2 root@server:~# ip netns exec ns2 ip a s 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 8: eth1-ns2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether fa:71:b8:a1:7f:85 brd ff:ff:ff:ff:ff:ff inet 192.168.0.2/24 scope global eth1-ns2 valid_lft forever preferred_lft forever inet6 fe80::f871:b8ff:fea1:7f85/64 scope link valid_lft forever preferred_lft forever root@server:~#

With this, we established a connection between both ns1 and ns2 network namespaces through the Open vSwitch bridge. To confirm, let's use ping:
root@server:~# ip netns exec ns1 ping -c 3 192.168.0.2 PING 192.168.0.2 (192.168.0.2) 56(84) bytes of data. 64 bytes from 192.168.0.2: icmp_seq=1 ttl=64 time=0.414 ms 64 bytes from 192.168.0.2: icmp_seq=2 ttl=64 time=0.027 ms 64 bytes from 192.168.0.2: icmp_seq=3 ttl=64 time=0.030 ms --- 192.168.0.2 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 1998ms rtt min/avg/max/mdev = 0.027/0.157/0.414/0.181 ms root@server:~# root@server:~# ip netns exec ns2 ping -c 3 192.168.0.1 PING 192.168.0.1 (192.168.0.1) 56(84) bytes of data. 64 bytes from 192.168.0.1: icmp_seq=1 ttl=64 time=0.150 ms 64 bytes from 192.168.0.1: icmp_seq=2 ttl=64 time=0.025 ms 64 bytes from 192.168.0.1: icmp_seq=3 ttl=64 time=0.027 ms --- 192.168.0.1 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 1999ms rtt min/avg/max/mdev = 0.025/0.067/0.150/0.058 ms root@server:~#
Open vSwitch allows for assigning VLAN tags to network interfaces, resulting in traffic isolation between namespaces. This can be helpful in a scenario where you have multiple namespaces and you want to have connectivity between some of them.
The following example demonstrates how to tag the virtual interfaces on the ns1 and ns2 namespaces, so that the traffic will not be visible from each of the two network namespaces:
root@server:~# ovs-vsctl set port veth-ns1 tag=100 root@server:~# ovs-vsctl set port veth-ns2 tag=200 root@server:~# ovs-vsctl show 0ea38b4f-8943-4d5b-8d80-62ccb73ec9ec Bridge "OVS-1" Port "OVS-1" Interface "OVS-1" type: internal Port "veth-ns1" tag: 100 Interface "veth-ns1" Port "veth-ns2" tag: 200 Interface "veth-ns2" ovs_version: "2.0.2" root@server:~#
Both the namespaces should now be isolated in their own VLANs and ping should fail:
root@server:~# ip netns exec ns1 ping -c 3 192.168.0.2 PING 192.168.0.2 (192.168.0.2) 56(84) bytes of data. --- 192.168.0.2 ping statistics --- 3 packets transmitted, 0 received, 100% packet loss, time 1999ms root@server:~# ip netns exec ns2 ping -c 3 192.168.0.1 PING 192.168.0.1 (192.168.0.1) 56(84) bytes of data. --- 192.168.0.1 ping statistics --- 3 packets transmitted, 0 received, 100% packet loss, time 1999ms root@server:~#
We can also use the unshare utility that we saw in the mount and UTC namespaces examples to create a new network namespace:
root@server:~# unshare --net /bin/bash root@server:~# ip a s 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 root@server:~# exit root@server
Resource management with cgroups
Cgroups are kernel features that allows fine-grained control over resource allocation for a single process, or a group of processes, called tasks. In the context of LXC this is quite important, because it makes it possible to assign limits to how much memory, CPU time, or I/O, any given container can use.
The cgroups we are most interested in are described in the following table:
|
Subsystem |
Description |
Defined in |
|
|
Allocates CPU time for tasks |
|
|
|
Accounts for CPU usage |
|
|
|
Assigns CPU cores to tasks |
|
|
|
Allocates memory for tasks |
|
|
|
Limits the I/O access to devices |
|
|
|
Allows/denies access to devices |
|
|
|
Suspends/resumes tasks |
|
|
|
Tags network packets |
|
|
|
Prioritizes network traffic |
|
|
|
Limits the HugeTLB |
|
Cgroups are organized in hierarchies, represented as directories in a Virtual File System (VFS). Similar to process hierarchies, where every process is a descendent of the init or systemd process, cgroups inherit some of the properties of their parents. Multiple cgroups hierarchies can exist on the system, each one representing a single or group of resources. It is possible to have hierarchies that combine two or more subsystems, for example, memory and I/O, and tasks assigned to a group will have limits applied on those resources.
Note
If you are interested in how the different subsystems are implemented in the kernel, install the kernel source and have a look at the C files, shown in the third column of the table.
The following diagram helps visualize a single hierarchy that has two subsystems—CPU and I/O—attached to it:

Cgroups can be used in two ways:
- By manually manipulating files and directories on a mounted VFS
- Using userspace tools provided by various packages such as
cgroup-binon Debian/Ubuntu andlibcgroupon RHEL/CentOS
Let's have a look at few practical examples on how to use cgroups to limit resources. This will help us get a better understanding of how containers work.
Limiting I/O throughput
Let's assume we have two applications running on a server that are heavily I/O bound: app1 and app2. We would like to give more bandwidth to app1 during the day and to app2 during the night. This type of I/O throughput prioritization can be accomplished using the blkio subsystem.
First, let's attach the blkio subsystem by mounting the cgroup VFS:
root@server:~# mkdir -p /cgroup/blkio root@server:~# mount -t cgroup -o blkio blkio /cgroup/blkio root@server:~# cat /proc/mounts | grep cgroup blkio /cgroup/blkio cgroup rw, relatime, blkio, crelease_agent=/run/cgmanager/agents/cgm-release-agent.blkio 0 0 root@server:~#
Next, create two priority groups, which will be part of the same blkio hierarchy:
root@server:~# mkdir /cgroup/blkio/high_io root@server:~# mkdir /cgroup/blkio/low_io root@server:~#
We need to acquire the PIDs of the app1 and app2 processes and assign them to the high_io and low_io groups:
root@server:~# pidof app1 | while read PID; do echo $PID >> /cgroup/blkio/high_io/tasks; done root@server:~# pidof app2 | while read PID; do echo $PID >> /cgroup/blkio/low_io/tasks; done root@server:~#
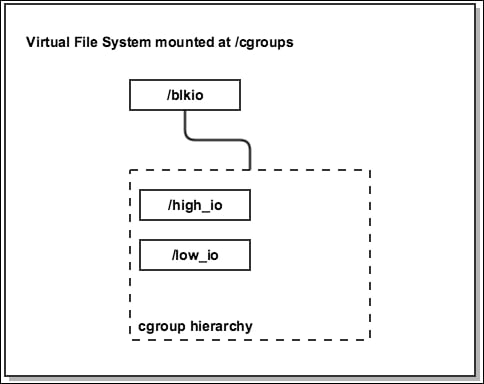
The blkio hierarchy we've created
The tasks file is where we define what processes/tasks the limit should be applied on.
Finally, let's set a ratio of 10:1 for the high_io and low_io cgroups. Tasks in those cgroups will immediately use only the resources made available to them:
root@server:~# echo 1000 > /cgroup/blkio/high_io/blkio.weight root@server:~# echo 100 > /cgroup/blkio/low_io/blkio.weight root@server:~#
The blkio.weight file defines the weight of I/O access available to a process or group of processes, with values ranging from 100 to 1,000. In this example, the values of 1000 and 100 create a ratio of 10:1.
With this, the low priority application, app2 will use only about 10 percent of the I/O operations available, whereas the high priority application, app1, will use about 90 percent.
If you list the contents of the high_io directory on Ubuntu you will see the following files:
root@server:~# ls -la /cgroup/blkio/high_io/ drwxr-xr-x 2 root root 0 Aug 24 16:14 . drwxr-xr-x 4 root root 0 Aug 19 21:14 .. -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_merged -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_merged_recursive -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_queued -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_queued_recursive -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_service_bytes -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_service_bytes_recursive -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_serviced -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_serviced_recursive -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_service_time -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_service_time_recursive -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_wait_time -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_wait_time_recursive -rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.leaf_weight -rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.leaf_weight_device --w------- 1 root root 0 Aug 24 16:14 blkio.reset_stats -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.sectors -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.sectors_recursive -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.io_service_bytes -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.io_serviced -rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.read_bps_device -rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.read_iops_device -rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.write_bps_device -rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.write_iops_device -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.time -r--r--r-- 1 root root 0 Aug 24 16:14 blkio.time_recursive -rw-r--r-- 1 root root 0 Aug 24 16:49 blkio.weight -rw-r--r-- 1 root root 0 Aug 24 17:01 blkio.weight_device -rw-r--r-- 1 root root 0 Aug 24 16:14 cgroup.clone_children --w--w--w- 1 root root 0 Aug 24 16:14 cgroup.event_control -rw-r--r-- 1 root root 0 Aug 24 16:14 cgroup.procs -rw-r--r-- 1 root root 0 Aug 24 16:14 notify_on_release -rw-r--r-- 1 root root 0 Aug 24 16:14 tasks root@server:~#
From the preceding output you can see that only some files are writeable. This depends on various OS settings, such as what I/O scheduler is being used.
We've already seen what the tasks and blkio.weight files are used for. The following is a short description of the most commonly used files in the blkio subsystem:
|
File |
Description |
|
|
Total number of reads/writes, sync, or async merged into requests |
|
|
Total number of read/write, sync, or async requests queued up at any given time |
|
|
The number of bytes transferred to or from the specified device |
|
|
The number of I/O operations issued to the specified device |
|
|
Total amount of time between request dispatch and request completion in nanoseconds for the specified device |
|
|
Total amount of time the I/O operations spent waiting in the scheduler queues for the specified device |
|
|
Similar to |
|
|
Writing an integer to this file will reset all statistics |
|
|
The number of sectors transferred to or from the specified device |
|
|
The number of bytes transferred to or from the disk |
|
|
The number of I/O operations issued to the specified disk |
|
|
The disk time allocated to a device in milliseconds |
|
|
Specifies weight for a cgroup hierarchy |
|
|
Same as |
|
|
Attach tasks to the cgroup |
Tip
One thing to keep in mind is that writing to the files directly to make changes will not persist after the server restarts. Later in this chapter, you will learn how to use the userspace tools to generate persistent configuration files.
Limiting memory usage
The memory subsystem controls how much memory is presented to and available for use by processes. This can be particularly useful in multitenant environments where better control over how much memory a user process can utilize is needed, or to limit memory hungry applications. Containerized solutions like LXC can use the memory subsystem to manage the size of the instances, without needing to restart the entire container.
The memory subsystem performs resource accounting, such as tracking the utilization of anonymous pages, file caches, swap caches, and general hierarchical accounting, all of which presents an overhead. Because of this, the memory cgroup is disabled by default on some Linux distributions. If the following commands below fail you'll need to enable it, by specifying the following GRUB parameter and restarting:
root@server:~# vim /etc/default/grub RUB_CMDLINE_LINUX_DEFAULT="cgroup_enable=memory" root@server:~# grub-update && reboot
First, let's mount the memory cgroup:
root@server:~# mkdir -p /cgroup/memory root@server:~# mount -t cgroup -o memory memory /cgroup/memory root@server:~# cat /proc/mounts | grep memory memory /cgroup/memory cgroup rw, relatime, memory, release_agent=/run/cgmanager/agents/cgm-release-agent.memory 0 0 root@server:~#
Then set the app1 memory to 1 GB:
root@server:~# mkdir /cgroup/memory/app1 root@server:~# echo 1G > /cgroup/memory/app1/memory.limit_in_bytes root@server:~# cat /cgroup/memory/app1/memory.limit_in_bytes 1073741824 root@server:~# pidof app1 | while read PID; do echo $PID >> /cgroup/memory/app1/tasks; done root@server:~#

The memory hierarchy for the app1 process
Similar to the blkio subsystem, the tasks file is used to specify the PID of the processes we are adding to the cgroup hierarchy, and the memory.limit_in_bytes specifies how much memory is to be made available in bytes.
The app1 memory hierarchy contains the following files:
root@server:~# ls -la /cgroup/memory/app1/ drwxr-xr-x 2 root root 0 Aug 24 22:05 . drwxr-xr-x 3 root root 0 Aug 19 21:02 .. -rw-r--r-- 1 root root 0 Aug 24 22:05 cgroup.clone_children --w--w--w- 1 root root 0 Aug 24 22:05 cgroup.event_control -rw-r--r-- 1 root root 0 Aug 24 22:05 cgroup.procs -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.failcnt --w------- 1 root root 0 Aug 24 22:05 memory.force_empty -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.failcnt -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.limit_in_bytes -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.max_usage_in_bytes -r--r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.slabinfo -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.tcp.failcnt -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.tcp.limit_in_bytes -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.tcp.max_usage_in_bytes -r--r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.tcp.usage_in_bytes -r--r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.usage_in_bytes -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.limit_in_bytes -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.max_usage_in_bytes -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.move_charge_at_immigrate -r--r--r-- 1 root root 0 Aug 24 22:05 memory.numa_stat -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.oom_control ---------- 1 root root 0 Aug 24 22:05 memory.pressure_level -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.soft_limit_in_bytes -r--r--r-- 1 root root 0 Aug 24 22:05 memory.stat -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.swappiness -r--r--r-- 1 root root 0 Aug 24 22:05 memory.usage_in_bytes -rw-r--r-- 1 root root 0 Aug 24 22:05 memory.use_hierarchy -rw-r--r-- 1 root root 0 Aug 24 22:05 tasks root@server:~#
The files and their function in the memory subsystem are described in the following table:
|
File |
Description |
|
|
Shows the total number of memory limit hits |
|
|
If set to |
|
|
Shows the total number of kernel memory limit hits |
|
|
Sets or shows kernel memory hard limit |
|
|
Shows maximum kernel memory usage |
|
|
Shows the number of TCP buffer memory limit hits |
|
|
Sets or shows hard limit for TCP buffer memory |
|
|
Shows maximum TCP buffer memory usage |
|
|
Shows current TCP buffer memory |
|
|
Shows current kernel memory |
|
|
Sets or shows memory usage limit |
|
|
Shows maximum memory usage |
|
|
Sets or shows controls of moving charges |
|
|
Shows the number of memory usage per NUMA node |
|
|
Sets or shows the OOM controls |
|
|
Sets memory pressure notifications |
|
|
Sets or shows soft limit of memory usage |
|
|
Shows various statistics |
|
|
Sets or shows swappiness level |
|
|
Shows current memory usage |
|
|
Sets memory reclamation from child processes |
|
|
Attaches tasks to the cgroup |
Limiting the memory available to a process might trigger the Out of Memory (OOM) killer, which might kill the running task. If this is not the desired behavior and you prefer the process to be suspended waiting for memory to be freed, the OOM killer can be disabled:
root@server:~# cat /cgroup/memory/app1/memory.oom_control oom_kill_disable 0 under_oom 0 root@server:~# echo 1 > /cgroup/memory/app1/memory.oom_control root@server:~#
The memory cgroup presents a wide slew of accounting statistics in the memory.stat file, which can be of interest:
root@server:~# head /cgroup/memory/app1/memory.stat cache 43325 # Number of bytes of page cache memory rss 55d43 # Number of bytes of anonymous and swap cache memory rss_huge 0 # Number of anonymous transparent hugepages mapped_file 2 # Number of bytes of mapped file writeback 0 # Number of bytes of cache queued for syncing pgpgin 0 # Number of charging events to the memory cgroup pgpgout 0 # Number of uncharging events to the memory cgroup pgfault 0 # Total number of page faults pgmajfault 0 # Number of major page faults inactive_anon 0 # Anonymous and swap cache memory on inactive LRU list
If you need to start a new task in the app1 memory hierarchy you can move the current shell process into the tasks file, and all other processes started in this shell will be direct descendants and inherit the same cgroup properties:
root@server:~# echo $$ > /cgroup/memory/app1/tasks root@server:~# echo "The memory limit is now applied to all processes started from this shell"
The cpu and cpuset subsystems
The cpu subsystem schedules CPU time to cgroup hierarchies and their tasks. It provides finer control over CPU execution time than the default behavior of the CFS.
The cpuset subsystem allows for assigning CPU cores to a set of tasks, similar to the taskset command in Linux.
The main benefits that the cpu and cpuset subsystems provide are better utilization per processor core for highly CPU bound applications. They also allow for distributing load between cores that are otherwise idle at certain times of the day. In the context of multitenant environments, running many LXC containers, cpu and cpuset cgroups allow for creating different instance sizes and container flavors, for example exposing only a single core per container, with 40 percent scheduled work time.
As an example, let's assume we have two processes app1 and app2, and we would like app1 to use 60 percent of the CPU time and app2 only 40 percent. We start by mounting the cgroup VFS:
root@server:~# mkdir -p /cgroup/cpu root@server:~# mount -t cgroup -o cpu cpu /cgroup/cpu root@server:~# cat /proc/mounts | grep cpu cpu /cgroup/cpu cgroup rw, relatime, cpu, release_agent=/run/cgmanager/agents/cgm-release-agent.cpu 0 0
Then we create two child hierarchies:
root@server:~# mkdir /cgroup/cpu/limit_60_percent root@server:~# mkdir /cgroup/cpu/limit_40_percent
Also assign CPU shares for each, where app1 will get 60 percent and app2 will get 40 percent of the scheduled time:
root@server:~# echo 600 > /cgroup/cpu/limit_60_percent/cpu.shares root@server:~# echo 400 > /cgroup/cpu/limit_40_percent/cpu.shares
Finally, we move the PIDs in the tasks files:
root@server:~# pidof app1 | while read PID; do echo $PID >> /cgroup/cpu/limit_60_percent/tasks; done root@server:~# pidof app2 | while read PID; do echo $PID >> /cgroup/cpu/limit_40_percent/tasks; done root@server:~#
The cpu subsystem contains the following control files:
root@server:~# ls -la /cgroup/cpu/limit_60_percent/ drwxr-xr-x 2 root root 0 Aug 25 15:13 . drwxr-xr-x 4 root root 0 Aug 19 21:02 .. -rw-r--r-- 1 root root 0 Aug 25 15:13 cgroup.clone_children --w--w--w- 1 root root 0 Aug 25 15:13 cgroup.event_control -rw-r--r-- 1 root root 0 Aug 25 15:13 cgroup.procs -rw-r--r-- 1 root root 0 Aug 25 15:13 cpu.cfs_period_us -rw-r--r-- 1 root root 0 Aug 25 15:13 cpu.cfs_quota_us -rw-r--r-- 1 root root 0 Aug 25 15:14 cpu.shares -r--r--r-- 1 root root 0 Aug 25 15:13 cpu.stat -rw-r--r-- 1 root root 0 Aug 25 15:13 notify_on_release -rw-r--r-- 1 root root 0 Aug 25 15:13 tasks root@server:~#
Here's a brief explanation of each:
|
File |
Description |
|
|
CPU resource reallocation in microseconds |
|
|
Run duration of tasks in microseconds during one |
|
|
Relative share of CPU time available to the tasks |
|
|
Shows CPU time statistics |
|
|
Attaches tasks to the cgroup |
The cpu.stat file is of particular interest:
root@server:~# cat /cgroup/cpu/limit_60_percent/cpu.stat nr_periods 0 # number of elapsed period intervals, as specified in # cpu.cfs_period_us nr_throttled 0 # number of times a task was not scheduled to run # because of quota limit throttled_time 0 # total time in nanoseconds for which tasks have been # throttled root@server:~#
To demonstrate how the cpuset subsystem works, let's create cpuset hierarchies named app1, containing CPUs 0 and 1. The app2 cgroup will contain only CPU 1:
root@server:~# mkdir /cgroup/cpuset root@server:~# mount -t cgroup -o cpuset cpuset /cgroup/cpuset root@server:~# mkdir /cgroup/cpuset/app{1..2} root@server:~# echo 0-1 > /cgroup/cpuset/app1/cpuset.cpus root@server:~# echo 1 > /cgroup/cpuset/app2/cpuset.cpus root@server:~# pidof app1 | while read PID; do echo $PID >> /cgroup/cpuset/app1/tasks limit_60_percent/tasks; done root@server:~# pidof app2 | while read PID; do echo $PID >> /cgroup/cpuset/app2/tasks limit_40_percent/tasks; done root@server:~#
To check if the app1 process is pinned to CPU 0 and 1, we can use:
root@server:~# taskset -c -p $(pidof app1) pid 8052's current affinity list: 0,1 root@server:~# taskset -c -p $(pidof app2) pid 8052's current affinity list: 1 root@server:~#
The cpuset app1 hierarchy contains the following files:
root@server:~# ls -la /cgroup/cpuset/app1/ drwxr-xr-x 2 root root 0 Aug 25 16:47 . drwxr-xr-x 5 root root 0 Aug 19 21:02 .. -rw-r--r-- 1 root root 0 Aug 25 16:47 cgroup.clone_children --w--w--w- 1 root root 0 Aug 25 16:47 cgroup.event_control -rw-r--r-- 1 root root 0 Aug 25 16:47 cgroup.procs -rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.cpu_exclusive -rw-r--r-- 1 root root 0 Aug 25 17:57 cpuset.cpus -rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.mem_exclusive -rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.mem_hardwall -rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.memory_migrate -r--r--r-- 1 root root 0 Aug 25 16:47 cpuset.memory_pressure -rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.memory_spread_page -rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.memory_spread_slab -rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.mems -rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.sched_load_balance -rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.sched_relax_domain_level -rw-r--r-- 1 root root 0 Aug 25 16:47 notify_on_release -rw-r--r-- 1 root root 0 Aug 25 17:13 tasks root@server:~#
A brief description of the control files is as follows:
|
File |
Description |
|
|
Checks if other |
|
|
List of the physical numbers of the CPUs on which processes in that |
|
|
Should the |
|
|
Checks if each tasks' user allocation be kept separate |
|
|
Checks if a page in memory should migrate to a new node if the values in |
|
|
Contains running average of the memory pressure created by the processes |
|
|
Checks if filesystem buffers should spread evenly across the memory nodes |
|
|
Checks if kernel slab caches for file I/O operations should spread evenly across the |
|
|
Specifies the memory nodes that tasks in this cgroup are permitted to access |
|
|
Checks if the kernel balance should load across the CPUs in the |
|
|
Contains the width of the range of CPUs across which the kernel should attempt to balance loads |
|
|
Checks if the hierarchy should receive special handling after it is released and no process are using it |
|
|
Attaches tasks to the cgroup |
The cgroup freezer subsystem
The freezer subsystem can be used to suspend the current state of running tasks for the purposes of analyzing them, or to create a checkpoint that can be used to migrate the process to a different server. Another use case is when a process is negatively impacting the system and needs to be temporarily paused, without losing its current state data.
The next example shows how to suspend the execution of the top process, check its state, and then resume it.
First, mount the freezer subsystem and create the new hierarchy:
root@server:~# mkdir /cgroup/freezer root@server:~# mount -t cgroup -o freezer freezer /cgroup/freezer root@server:~# mkdir /cgroup/freezer/frozen_group root@server:~# cat /proc/mounts | grep freezer freezer /cgroup/freezer cgroup rw,relatime,freezer,release_agent=/run/cgmanager/agents/cgm-release-agent.freezer 0 0 root@server:~#
In a new terminal, start the top process and observe how it periodically refreshes. Back in the original terminal, add the PID of top to the frozen_group task file and observe its state:
root@server:~# echo 25731 > /cgroup/freezer/frozen_group/tasks root@server:~# cat /cgroup/freezer/frozen_group/freezer.state THAWED root@server:~#
To freeze the process, echo the following:
root@server:~# echo FROZEN > /cgroup/freezer/frozen_group/freezer.state root@server:~# cat /cgroup/freezer/frozen_group/freezer.state FROZEN root@server:~# cat /proc/25s731/status | grep -i state State: D (disk sleep) root@server:~#
Notice how the top process output is not refreshing anymore, and upon inspection of its status file, you can see that it is now in the blocked state.
To resume it, execute the following:
root@server:~# echo THAWED > /cgroup/freezer/frozen_group/freezer.state root@server:~# cat /proc/29328/status | grep -i state State: S (sleeping) root@server:~#
Inspecting the frozen_group hierarchy yields the following files:
root@server:~# ls -la /cgroup/freezer/frozen_group/ drwxr-xr-x 2 root root 0 Aug 25 20:50 . drwxr-xr-x 4 root root 0 Aug 19 21:02 .. -rw-r--r-- 1 root root 0 Aug 25 20:50 cgroup.clone_children --w--w--w- 1 root root 0 Aug 25 20:50 cgroup.event_control -rw-r--r-- 1 root root 0 Aug 25 20:50 cgroup.procs -r--r--r-- 1 root root 0 Aug 25 20:50 freezer.parent_freezing -r--r--r-- 1 root root 0 Aug 25 20:50 freezer.self_freezing -rw-r--r-- 1 root root 0 Aug 25 21:00 freezer.state -rw-r--r-- 1 root root 0 Aug 25 20:50 notify_on_release -rw-r--r-- 1 root root 0 Aug 25 20:59 tasks root@server:~#
The few files of interest are described in the following table:
|
File |
Description |
|
|
Shows the parent-state. Shows |
|
|
Shows the self-state. Shows |
|
|
Sets the self-state of the cgroup to either |
|
|
Attaches tasks to the cgroup. |
Using userspace tools to manage cgroups and persist changes
Working with the cgroups subsystems by manipulating directories and files directly is a fast and convenient way to prototype and test changes, however, this comes with few drawbacks, namely the changes made will not persist a server restart and there's not much error reporting or handling.
To address this, there are packages that provide userspace tools and daemons that are quite easy to use. Let's see a few examples.
To install the tools on Debian/Ubuntu, run the following:
root@server:~# apt-get install -y cgroup-bin cgroup-lite libcgroup1 root@server:~# service cgroup-lite start
On RHEL/CentOS, execute the following:
root@server:~# yum install libcgroup root@server:~# service cgconfig start
To mount all subsystems, run the following:
root@server:~# cgroups-mount root@server:~# cat /proc/mounts | grep cgroup cgroup /sys/fs/cgroup/memory cgroup rw,relatime,memory,release_agent=/run/cgmanager/agents/cgm-release-agent.memory 0 0 cgroup /sys/fs/cgroup/devices cgroup rw,relatime,devices,release_agent=/run/cgmanager/agents/cgm-release-agent.devices 0 0 cgroup /sys/fs/cgroup/freezer cgroup rw,relatime,freezer,release_agent=/run/cgmanager/agents/cgm-release-agent.freezer 0 0 cgroup /sys/fs/cgroup/blkio cgroup rw,relatime,blkio,release_agent=/run/cgmanager/agents/cgm-release-agent.blkio 0 0 cgroup /sys/fs/cgroup/perf_event cgroup rw,relatime,perf_event,release_agent=/run/cgmanager/agents/cgm-release-agent.perf_event 0 0 cgroup /sys/fs/cgroup/hugetlb cgroup rw,relatime,hugetlb,release_agent=/run/cgmanager/agents/cgm-release-agent.hugetlb 0 0 cgroup /sys/fs/cgroup/cpuset cgroup rw,relatime,cpuset,release_agent=/run/cgmanager/agents/cgm-release-agent.cpuset,clone_children 0 0 cgroup /sys/fs/cgroup/cpu cgroup rw,relatime,cpu,release_agent=/run/cgmanager/agents/cgm-release-agent.cpu 0 0 cgroup /sys/fs/cgroup/cpuacct cgroup rw,relatime,cpuacct,release_agent=/run/cgmanager/agents/cgm-release-agent.cpuacct 0 0
Notice from the preceding output the location of the cgroups - /sys/fs/cgroup. This is the default location on many Linux distributions and in most cases the various subsystems have already been mounted.
To verify what cgroup subsystems are in use, we can check with the following commands:
root@server:~# cat /proc/cgroups #subsys_name hierarchy num_cgroups enabled cpuset 7 1 1 cpu 8 2 1 cpuacct 9 1 1 memory 10 2 1 devices 11 1 1 freezer 12 1 1 blkio 6 3 1 perf_event 13 1 1 hugetlb 14 1 1
Next, let's create a blkio hierarchy and add an already running process to it with cgclassify. This is similar to what we did earlier, by creating the directories and the files by hand:
root@server:~# cgcreate -g blkio:high_io root@server:~# cgcreate -g blkio:low_io root@server:~# cgclassify -g blkio:low_io $(pidof app1) root@server:~# cat /sys/fs/cgroup/blkio/low_io/tasks 8052 root@server:~# cgset -r blkio.weight=1000 high_io root@server:~# cgset -r blkio.weight=100 low_io root@server:~# cat /sys/fs/cgroup/blkio/high_io/blkio.weight 1000 root@server:~#
Now that we have defined the high_io and low_io cgroups and added a process to them, let's generate a configuration file that can be used later to reapply the setup:
root@server:~# cgsnapshot -s -f /tmp/cgconfig_io.conf cpuset = /sys/fs/cgroup/cpuset; cpu = /sys/fs/cgroup/cpu; cpuacct = /sys/fs/cgroup/cpuacct; memory = /sys/fs/cgroup/memory; devices = /sys/fs/cgroup/devices; freezer = /sys/fs/cgroup/freezer; blkio = /sys/fs/cgroup/blkio; perf_event = /sys/fs/cgroup/perf_event; hugetlb = /sys/fs/cgroup/hugetlb; root@server:~# cat /tmp/cgconfig_io.conf # Configuration file generated by cgsnapshot mount { blkio = /sys/fs/cgroup/blkio; } group low_io { blkio { blkio.leaf_weight="500"; blkio.leaf_weight_device=""; blkio.weight="100"; blkio.weight_device=""; blkio.throttle.write_iops_device=""; blkio.throttle.read_iops_device=""; blkio.throttle.write_bps_device=""; blkio.throttle.read_bps_device=""; blkio.reset_stats=""; } } group high_io { blkio { blkio.leaf_weight="500"; blkio.leaf_weight_device=""; blkio.weight="1000"; blkio.weight_device=""; blkio.throttle.write_iops_device=""; blkio.throttle.read_iops_device=""; blkio.throttle.write_bps_device=""; blkio.throttle.read_bps_device=""; blkio.reset_stats=""; } } root@server:~#
To start a new process in the high_io group, we can use the cgexec command:
root@server:~# cgexec -g blkio:high_io bash root@server:~# echo $$ 19654 root@server:~# cat /sys/fs/cgroup/blkio/high_io/tasks 19654 root@server:~#
In the preceding example, we started a new bash process in the high_io cgroup, as confirmed by looking at the tasks file.
To move an already running process to the memory subsystem, first we create the high_prio and low_prio groups and move the task with cgclassify:
root@server:~# cgcreate -g cpu,memory:high_prio root@server:~# cgcreate -g cpu,memory:low_prio root@server:~# cgclassify -g cpu,memory:high_prio 8052 root@server:~# cat /sys/fs/cgroup/memory/high_prio/tasks 8052 root@server:~# cat /sys/fs/cgroup/cpu/high_prio/tasks 8052 root@server:~#
To set the memory and CPU limits, we can use the cgset command. In contrast, remember that we used the echo command to manually move the PIDs and memory limits to the tasks and the memory.limit_in_bytes files:
root@server:~# cgset -r memory.limit_in_bytes=1G low_prio root@server:~# cat /sys/fs/cgroup/memory/low_prio/memory.limit_in_bytes 1073741824 root@server:~# cgset -r cpu.shares=1000 high_prio root@server:~# cat /sys/fs/cgroup/cpu/high_prio/cpu.shares 1000 root@server:~#
To see how the cgroup hierarchies look, we can use the lscgroup utility:
root@server:~# lscgroup cpuset:/ cpu:/ cpu:/low_prio cpu:/high_prio cpuacct:/ memory:/ memory:/low_prio memory:/high_prio devices:/ freezer:/ blkio:/ blkio:/low_io blkio:/high_io perf_event:/ hugetlb:/ root@server:~#
The preceding output confirms the existence of the blkio, memory, and cpu hierarchies and their children.
Once finished, you can delete the hierarchies with cgdelete, which deletes the respective directories on the VFS:
root@server:~# cgdelete -g cpu,memory:high_prio root@server:~# cgdelete -g cpu,memory:low_prio root@server:~# lscgroup cpuset:/ cpu:/ cpuacct:/ memory:/ devices:/ freezer:/ blkio:/ blkio:/low_io blkio:/high_io perf_event:/ hugetlb:/ root@server:~#
To completely clear the cgroups, we can use the cgclear utility, which will unmount the cgroup directories:
root@server:~# cgclear root@server:~# lscgroup cgroups can't be listed: Cgroup is not mounted root@server:~#
Managing resources with systemd
With the increased adoption of systemd as an init system, new ways of manipulating cgroups were introduced. For example, if the cpu controller is enabled in the kernel, systemd will create a cgroup for each service by default. This behavior can be changed by adding or removing cgroup subsystems in the configuration file of systemd, usually found at /etc/systemd/system.conf.
If multiple services are running on the server, the CPU resources will be shared equally among them by default, because systemd assigns equal weights to each. To change this behavior for an application, we can edit its service file and define the CPU shares, allocated memory, and I/O.
The following example demonstrates how to change the CPU shares, memory, and I/O limits for the nginx process:
root@server:~# vim /etc/systemd/system/nginx.service .include /usr/lib/systemd/system/httpd.service [Service] CPUShares=2000 MemoryLimit=1G BlockIOWeight=100
To apply the changes first reload systemd, then nginx:
root@server:~# systemctl daemon-reload root@server:~# systemctl restart httpd.service root@server:~#
This will create and update the necessary control files in /sys/fs/cgroup/systemd and apply the limits.







