






















































To investigate how to reverse engineer a new website, we will take a look at the BMW site. The BMW website has a search tool to find local dealerships, available at https://www.bmw.de/de/home.html?entryType=dlo:
This tool takes a location and then displays the points near it on a map, such as this search for Berlin:
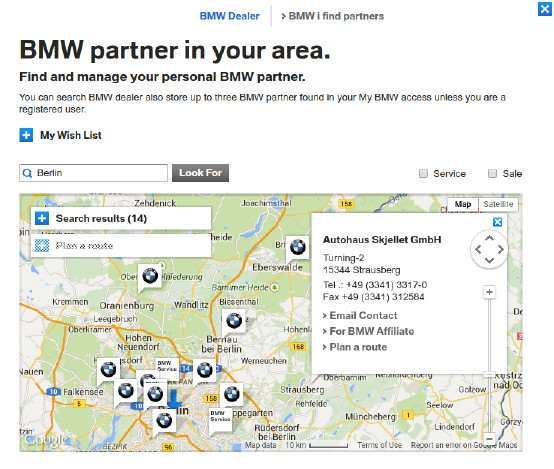
Using browser developer tools such as the Network tab, we find that the search triggers this AJAX request:
https://c2b-services.bmw.com/c2b-localsearch/services/api/v3/
clients/BMWDIGITAL_DLO/DE/
pois?country=DE&category=BM&maxResults=99&language=en&
lat=52.507537768880056&lng=13.425269635701511
Here, the maxResults parameter is set to 99. However, we can increase this to download all locations in a single query, a technique covered in Chapter 1, Introduction to Web Scraping. Here is the result when maxResults is increased to 1000:
>>> import...













