






















































Introduction to the data and analytics journey
The online transaction processing (OLTP) and online analytical processing (OLAP) systems worked great by themselves for a very long time when data producers were limited, the volume of data was under control, and data was mostly structured in tabular format. The last 20 years have seen a seismic shift in the way new businesses and technologies have come up.
As the volume, velocity, and variety of data started to pick steam, data grew into big data and the data processing techniques needed a major rehaul. This gave rise to the Apache Hadoop framework, which changed the way big data was processed and stored. With more data, businesses wanted to get more descriptive and diagnostic analytics out of their data. At the same time, another technology was gaining rapid traction, which gave organizations hope that they could look ahead to the future and predict what may happen in advance so that they could take immediate actions to steer their businesses in the right direction. This was made possible by the rise of artificial intelligence and machine learning and soon, large organizations started investing in predictive analytics projects.
And while we were thinking that we got the big data under control with new frameworks, the data floodgates opened up. The last 10 to 15 years have been revolutionary with the onset of smart devices, including smartphones. Connectivity among all these devices and systems made data grow exponentially. This was termed the Internet of Things (IoT). And to add to the complexity, these devices started to share data in near real time, which meant that data had to be streamed immediately for consumption. The following figure highlights many of the sources from where data gets generated. A lot of insights can be derived from all this data so that organizations can make faster and better decisions:
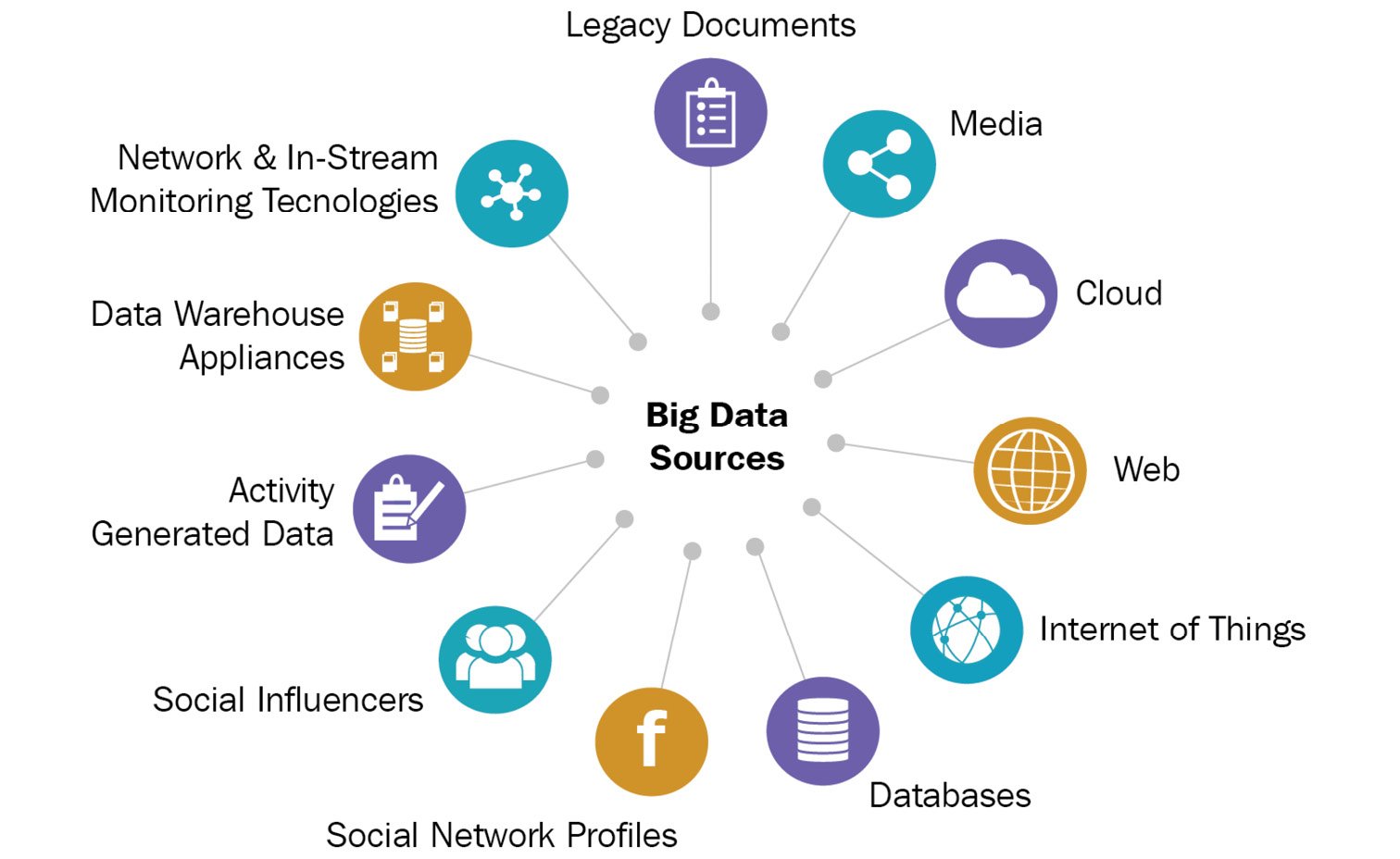
Figure 00.1 – Big data sources
This also meant that organizations started to carefully segregate their technical workforce to deal with data in personas. The people processing big data came to be known as data engineers, the people dealing with data for future predictions were the data scientists, and the people analyzing the data with various tools were the data analysts. Each type of persona had a well-defined task and there was a strong desire to create/purchase the best technological tool out there to make their day-to-day lives easier.
From a data and analytics point of view, systems started to grow bigger with extra hardware. Organizations started to expand their on-premises data centers with the latest and greatest servers out there to process all this data as fast as possible, to create value for their businesses. However, a lot of architecture patterns for data and analytics remained the same, which meant that many of the old use cases were still getting solved. However, with new demands from these businesses, pain areas started popping up more frequently.


