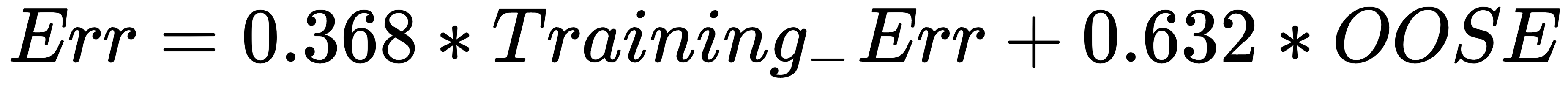0.632 rule in bootstrapping
Before we get into the 0.632 rule of bootstrapping, we need to understand what bootstrapping is. Bootstrapping is the process wherein random sampling is performed with a replacement from a population that's comprised of n observations. In this scenario, a sample can have duplicate observations. For example, if the population is (2,3,4,5,6) and we are trying to draw two random samples of size 4 with replacement, then sample 1 will be (2,3,3,6) and sample 2 will be (4,4,6,2).
Now, let's delve into the 0.632 rule.
We have already seen that the estimate of the training error while using a prediction is 1/n ∑L(yi,y-hat). This is nothing but the loss function:
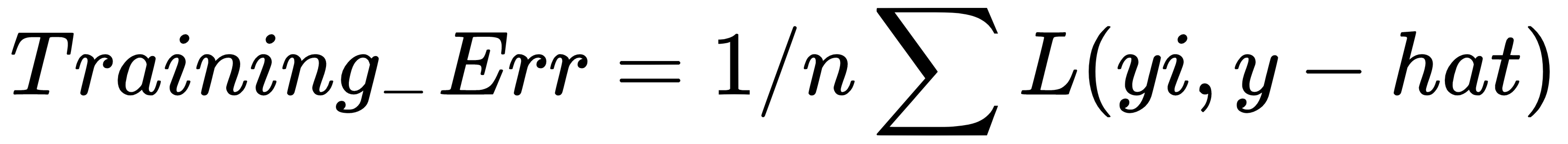
Cross-validation is a way to estimate the expected output of a sample error:
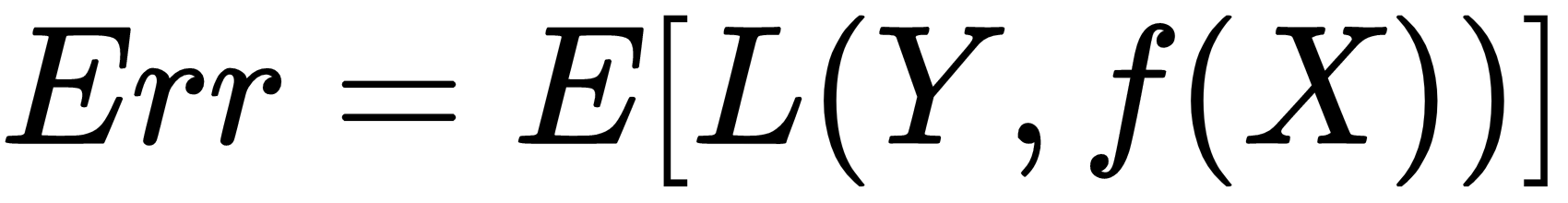
However, in the case of k-fold cross-validation, it is as follows:
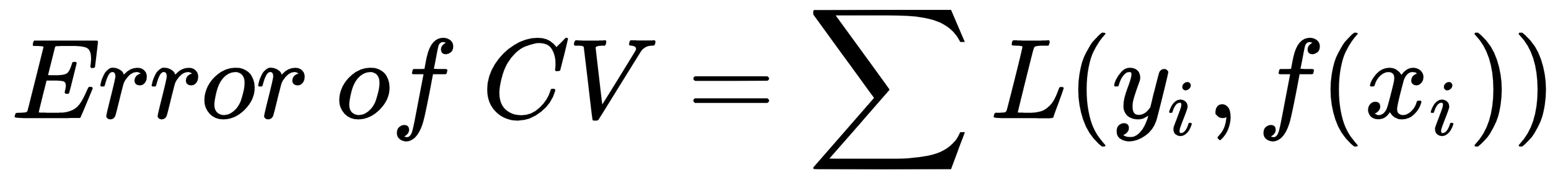
Here, the training data is X=(x1,x2.....,xn) and we take bootstrap samples from this set (z1,.....,zb) where each zi is a set of n samples.
In this scenario, the following is our out-of-sample error:
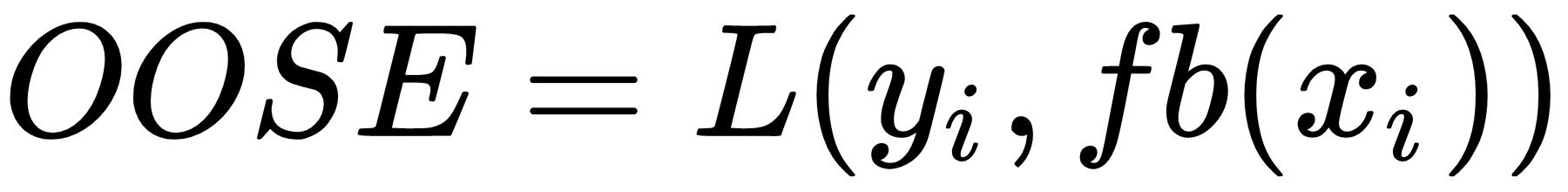
Here, fb(xi) is the predicted value at xi from the model that's been fit to the bootstrap dataset.
Unfortunately, this is not a particularly good estimator because bootstrap samples that have been used to produce fb(xi) may have contained xi.OOSE solves the overfitting problem, but is still biased. This bias is due to non-distinct observations in the bootstrap samples that result from sampling with replacement. The average number of distinct observations in each sample is about 0.632n. To solve the bias problem, Efron and Tibshirani proposed the 0.632 estimator: