






















































Setting up your shooting range
By now, you should have a pretty solid understanding of what Arrow is, the basics of how it's laid out in memory, and the basic terminology. So now, let's set up a development environment where you can test out and play with Arrow. For the purposes of this book, I'm going to primarily focus on the three libraries that I'm most familiar with: the C++ library, the Python library, and the Go library. While the basic concepts will apply to all of the implementations, the precise APIs may differ between them so, armed with the knowledge gained so far, you should be able to make sense of the documentation for your preferred language, even without precise examples for that language being printed here.
For each of C++, Python, and Go, after the instructions for installing the Arrow library, I'll go through a few exercises to get you acquainted with the basics of using the Arrow library in that language.
Using pyarrow For Python
With data science being a primary target of Arrow, it's no surprise that the Python library tends to be the most commonly used and interacted with by developers. Let's start with a quick introduction to setting up and using the pyarrow library for development.
Most modern IDEs provide plugins with exceptional Python support so you can fire up your preferred Python development IDE. I highly recommend using one of the methods for creating virtual environments with Python, such as pipenv, venv, or virtualenv, for setting up your environment. After creating that virtual environment, in most cases, installing pyarrow is as simple as using pip to install it:
$ pipenv install pyarrow # this or $ python3 -m venv arrow_playground && pip3 install pyarrow # this
It's also possible that, depending on your settings and platform, pip may attempt to build pyarrow locally. You can use the –-prefer-binary or –-only-binary arguments to tell pip to install the pre-build binary package rather than build from source:
$ pip3 install pyarrow --only-binary pyarrow
Alternately to using pip, Conda [16] is a common toolset utilized by data scientists and engineers, and the Arrow project provides binary Conda packages on conda-forge [17] for Linux, macOS, and Windows for Python 3.6+. You can install it with Conda and conda-forge as follows:
$ conda install pyarrow=6.0.* -c conda-forge
Understanding the basics of pyarrow
With the package installed, first let's confirm that the package installed successfully by opening up the Python interpreter and trying to import the package:
>>> import pyarrow as pa
>>> arr = pa.array([1,2,3,4])
>>> arr
<pyarrow.lib.Int64Array object at 0x0000019C4EC153A8>
[
1,
2,
3,
4
]
The important piece here to note is the highlighted lines where we import the library and create a simple array, letting the library determine the type for us, which it decides on using Int64 as the logical type.
Now that we've got a working installation of the pyarrow library, we can create a small example script to generate some random data and create a record batch:
import pyarrow as pa
import numpy as np
NROWS = 8192
NCOLS = 16
data = [pa.array(np.random.randn(NROWS)) for i in range(NCOLS)]
cols = ['c' + str(i) for i in range(NCOLS)]
rb = pa.RecordBatch.from_arrays(data, cols)
print(rb.schema)
print(rb.num_rows)
Going through this trivial example, this is what happens:
- First, the
numpylibrary is used to generate a bunch of data to use for our arrays. Callingpa.array(values), wherevaluesis a list of values for the array, will construct an array with the library inferring the logical type to use. - Next, a list of strings in the style of
'c0', 'c1', 'c2'…is created as names for the columns. - Finally, the highlighted line is where we construct a record batch from this random data, and then the subsequent two lines print out the schema and the number of rows.
We have got a new term here, record batch! A record batch is a common concept used when interacting with Arrow that we'll see show up in many places and refers to a group of equal length arrays and a schema. Often, a record batch will be a subset of rows of a larger dataset with the same schema. Record batches are a useful unit of parallelization for operating on data, as we'll see more in-depth in later chapters. That said, a record batch is actually very similar to a struct array when you think about it. Each field in a struct array can correspond to a column of the record batch. Let's use our archer example from earlier:
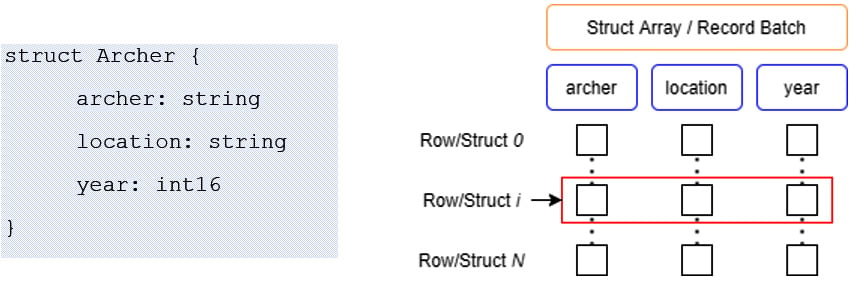
Figure 1.17 – Archer struct array
Since we're talking about a struct array, it will use the struct physical layout: an array with one child array for each field of our struct. This means that to refer to the entire struct at index i, you simply get the value at index i from each of the child arrays in the same way that if you were looking at a record batch; you do the same thing to get the semantic row at index i (Figure 1.17).
When constructing such an array, there are a couple of ways to think about how it would look in code. You could build up your struct array by building all three children simultaneously in a row-based fashion, or you could build up the individual child arrays completely separately and then just semantically group them together as a struct array with the column names. This shows another benefit of using columnar-based in-memory handling of this type of structure: each column could potentially be built in parallel and then brought back together at the end without the need for any extraneous copies. Parallelizing in a row-oriented fashion would typically be done by grouping batches of these records together and operating on the batches in parallel, which can still be done with the column-oriented approach, providing extra avenues of parallelization that wouldn't have existed in a row-oriented solution.
Building a struct array
The following steps describe how to construct a struct array from your data using a Python dictionary, but the data itself could come from anywhere, such as a JSON or CSV file:
- First, let's create a dictionary of our archers from previously to represent our data:
archer_list = [{ 'archer': 'Legolas', 'location': 'Mirkwood', 'year': 1954, },{ 'archer': 'Oliver', 'location': 'Star City', 'year': 1941, }, ……]
The rest of the values in this list are just the values from all the way back in Figure 1.3!
- Then, we define a data type for our struct array:
archer_type = pa.struct([('archer', pa.utf8()), ('location', pa.utf8()), ('year', pa.int16())]) - Now, we can construct the struct array itself:
archers = pa.array(archer_list, type=archer_type) print(archers.type) print(archers)
Data Types
See the usage of
pa.utf8()andpa.int16()? These usages are creating data type instances with the data types API. Specifying a list would bepa.list_(t1), wheret1is some other type, just as we're doing here withpa.struct; check the documentation [18] for the full listing.
The output is as follows (assuming you pulled the data from Figure 1.3 as I said):
struct<archer: string, location: string, year: int16> -- is_valid: all not null -- child 0 type: string [ "Legolas", "Oliver", "Merida", "Lara", "Artemis" ] -- child 1 type: string [ "Mirkwood", "Star City", "Scotland", "London", "Greece" ] -- child 2 type: int16 [ 1954, 1941, 2012, 1996, -600 ]
Do you recognize the similarity between the printed struct data and our earlier example of columnar data?
Using record batches and zero-copy manipulation
Often, after ingesting some data, there is still a need to further clean or reorganize it before running whatever processing or analytics you need to do. Being able to rearrange and move around the structure of your data like this with Arrow without having to make copies also results in some significant performance improvements over other approaches. To exemplify how we can optimize memory usage when utilizing Arrow, we can take the arrays from the struct array we created and easily flatten them into a record batch without any copies being made. Let's take the struct array of archers and flatten it into a record batch:
# archers is the struct array created earlier, flatten() returns
# the fields of the struct array as a python list of array objects
# remember 'pa' is from import pyarrow as pa
rb = pa.RecordBatch.from_arrays(archers.flatten(),
['archer', 'location', 'year'])
print(rb)
print(rb.num_rows) # prints 5
print(rb.num_columns) # prints 3
Since our struct array was 3 fields and had a length of 5, our record batch will have five rows and three columns. Record batches require having a schema defined, which is similar to defining a struct type; it's a list of fields, each with a name, a logical type, and metadata. The highlighted print statement in the preceding code to print out the record batch will just print the schema of the record batch:
pyarrow.RecordBatch archer: string location: string year: int16
The record batch we created holds references to the exact same arrays we created for the struct array, not copies, which makes this a very efficient operation, even for very large data sets. Cleaning, restructuring, and manipulating raw data into a more understandable or easier to work with format is a common task for data scientists and engineers. One of the strengths of using Arrow is that this can be done efficiently and without making copies of the data.
Another common situation when working with data is when you only need a particular slice of your dataset to work on, rather than the entire thing. As before, the library provides a slice function for slicing record batches or arrays without copying memory. Think back to the structure of the arrays; because any array has a length, null count, and sequence of buffers, the buffers that are used for a given array can be slices of the buffers from a larger array. This allows working with subsets of data without having to copy it around.
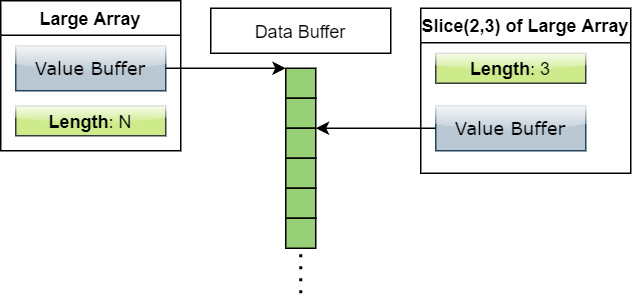
Figure 1.18 – Making a slice
A slice of a record batch is just slicing each of the constituent arrays which make it up; the same goes for any array of a nested type. Using our previous example, we use the following:
slice = rb.slice(1,3) # (start, length)
print(slice.num_rows) # prints 3 not 5
print(rb.column(0)[0]) # <pyarrow.StringScalar: 'Legolas'>
print(slice.column(0)[0]) # <pyarrow.StringScalar: 'Oliver'>
There's also a shortcut syntax for slicing an array, which should be comfortable for Python developers since it matches the same syntax for slicing a Python list:
archerslice = archers[1:3] # slice of length 2 viewing indexes 1
# and 2 from the struct array, so it slices all three arrays
One thing that does make a copy though is to convert Arrow arrays back to native Python objects for use with any other Python code that isn't using Arrow. Just like I mentioned back at the beginning of this chapter, shifting between different formats instead of the libraries all using the same one has costs to copy and convert the data:
print(rb.to_pydict()) # prints dictionary {column: list<values>}
print(archers.to_pylist()) # prints the same list of dictionaries
# we started with
Both of the preceding calls, to_pylist and to_pydict, perform copies of the data in order to put them into native Python object formats and should be used sparingly with large datasets.
Handling none values
The last thing to mention is the handling of null values. The None Python object is always converted to an Arrow null element when converting to an array, and vice versa when converting back to native Python objects.
An exercise for you
To get a feel for what real usage of the library might look like, here's an exercise to try out. You can find the solution along with the full code for any examples in the book in a GitHub repository located at https://github.com/PacktPublishing/In-Memory-Analytics-with-Apache-Arrow-:
- Take a (row-wise) list of objects with the following structure and convert them to a column-oriented record batch:
{ id: int, cost: double, cost_components: list<double> }
An example might be { "id": 4, "cost": 241.21, "cost_components": [ 100.00, 140.10, 1.11] } for a single object.
- Now that you've converted the row-based data in the list to a column-oriented Arrow record batch, do the reverse and convert the record batch back into the row-oriented list representation.
Now, let's take a look at the C++ library.
C++ for the 1337 coders
Due to the nature of C++, the setup potentially isn't as straightforward as Python or Go. There are a few different routes you can use to install the development headers and libraries, along with the necessary dependencies depending on your desired platform.
Technical requirements for using C++
Before we can develop, you need to first install the Arrow library on your system. The process is obviously going to differ based on the operating system you're using:
- If you are using Windows, you will need one of the following, along with either Visual Studio, C++, or Mingw gcc/g++ as your compiler:
- Conda: Replace
7.0.0with the version you wish to install:conda install arrow-cpp=7.0.0 -c conda-forge
- MSYS2 [19]: After installing MSYS2, you can use
pacmanto install the libraries:- For 64-bit:
pacman -S --noconfirm mingw-w64-x86_64-arrow
- For 32-bit:
pacman -S -–noconfirm mingw-w64-i686-arrow
vcpkg: This is kept up to date by Microsoft team members and community contributors:git clone https://github.com/Microsoft/vcpkg.git cd vcpkg ./bootstrap-vcpkg.sh ./vcpkg integrate install ./vcpkg install arrow
- Conda: Replace
Build it from source yourself: https://arrow.apache.org/docs/developers/cpp/windows.html.
Whichever way you decide to install the libraries, you need to add the path to where it installs the libraries to your environment path in order for them to be found at runtime.
- If using macOS and you don't want to build it yourself from source, you can use Homebrew [20] to install the library:
brew install apache-arrow
- If using Linux and you don't want to build it from source:
Packages for Debian GNU/Linux, Ubuntu, CentOS, Red Hat Enterprise Linux, and Amazon Linux are provided via APT and Yum repositories.
Rather than cover all of the instructions here, all of the installation instructions for the C++ library can be found at https://arrow.apache.org/install/. Only libarrow-dev is needed for the exercises in this chapter.
Once you've got your environment all set up and configured, let's take a look at the code. When compiling it, the easiest route is to use pkg-config if it's available on your system, otherwise, make sure you've added the correct include path and link against the Arrow library with the appropriate options (-I<path to arrow headers> -L<path to arrow libraries> -larrow).
Just like with the Python examples, let's start with a very simple example to walk through the API of the library.
Understanding the basics of the C++ library
Let's do the same first example in C++ that we did in Python:
#include <arrow/api.h>
#include <arrow/array.h>
#include <iostream>
int main(int argc, char** argv) {
std::vector<int64_t> data{1,2,3,4};
auto arr = std::make_shared<arrow::Int64Array>(data.size(), arrow::Buffer::Wrap(data));
std::cout << arr->ToString() << std::endl;
}
Just like the Python example previously, this outputs the following:
[ 1, 2, 3, 4, ]
Let's break down the highlighted line in the source code and explain what we did.
After creating std::vector of int64_ts to use as an example, we initialize std::shared_ptr to Int64Array by specifying the array length, or the number of values, and then wrapping the raw contiguous memory of the vector in a buffer for the array to use as its value buffer. It's important to note that using Buffer::Wrap does not copy the data, instead we're just referencing the memory that is used for the vector and using that same block of memory for the array. Finally, we use the ToString method of our array to create a string representation that we then output. Pretty straightforward, but also very useful in terms of getting used to the library and confirming your environment is set up properly.
When working with the C++ library, the Builder Pattern is commonly used for efficient construction of arrays. We can do the same random data example in C++ that we did earlier using Python, although it's a bit more verbose. Instead of numpy, we can just use the std library's normal distribution generator:
#include <random>
// later on
std::random_device rd{};
std::mt19937 gen{rd()};
std::normal_distribution<> d{5, 2};
Once we've done this setup, we can use d(gen) to produce random 64-bit float (or double) values. All that's left is to feed them into a builder and generate the arrays and a schema since, in order to create a record batch, you need to provide a schema.
First, we create our builder:
#include <arrow/builder.h>
auto pool = arrow::default_memory_pool();
arrow::DoubleBuilder builder{arrow::float64(), pool};
Just like how in Python we had pa.utf8() and pa.int16(), arrow::float64() returns a DataType object that is used to denote the logical type to use for this array. There's also the usage of the default_memory_pool() function, which returns the current global memory pool that this instance of Arrow has. The memory pool will get cleaned up at the process exit, and different pools can be created if needed, but in the majority of cases, just using the default one will be sufficient.
Now that we have our random number generator and our builder, let's create those arrays with random data:
#include <arrow/record_batch.h>
// previous code sections go here
constexpr auto ncols = 16;
constexpr auto nrows = 8192;
arrow::ArrayVector columns(ncols);
arrow::FieldVector fields;
for (int i = 0; i < ncols; ++i) {
for (int j = 0; j < nrows; ++j) {
builder.Append(d(gen));
}
auto status = builder.Finish(&columns[i]);
if (!status.ok()) {
std::cerr << status.message() << std::endl;
// handle the error
}
fields.push_back(arrow::field("c" + std::to_string(i),
arrow::float64()));
}
auto rb = arrow::RecordBatch::Make(arrow::schema(fields),
columns[0]->length(), columns);
std::cout << rb->ToString() << std::endl;
The most important lines are highlighted showing the population of the arrays and the record batch creation. Calling Builder::Finish also resets the builder so that it can be re-used to build more arrays of the same type. We also use a vector of fields to construct a schema that we use to create the record batch. After this, we can perform whatever operations we wish on the record batch, such as rearranging, flattening, or unflattening columns, performing aggregations or calculations on the data, or maybe just calling ToString to write out the data to the terminal.
Building a struct array, again
When building nested type arrays in C++, it's a little more complex when working with the builders. We can do the same struct example for our archers that we did in Python! If you remember, a struct array is essentially just a collection of children arrays that are the same size and a validity bitmap. This means that one way to build a struct array would be to simply build each constituent array as previously, and construct the struct array using them:
- Let's first mention
includeand someusingstatements for convenience, along with our initial data:#include <arrow/api.h> using arrow::field; using arrow::utf8; using arrow::int16; // vectors of archer data to start with std::vector<std::string> archers{"Legolas", "Oliver", "Merida", "Lara", "Artemis"}; std::vector<std::string> locations{"Mirkwood", "Star City", "Scotland", "London", "Greece"}; std::vector<int16_t> years{1954, 1941, 2012, 1996, -600}; - Now, we construct the constituent Arrow arrays that will make up our final struct array:
arrow::ArrayVector children; children.resize(3); arrow::StringBuilder str_bldr; str_bldr.AppendValues(archers); str_bldr.Finish(&children[0]); // resets the builder str_bldr.AppendValues(locations); // re-use it! str_bldr.Finish(&children[1]); arrow::Int16Builder year_bldr; year_bldr.AppendValues(years); year_bldr.Finish(&children[2]);
- Finally, with our children arrays constructed, we can define the struct array:
arrow::StructArray arr{arrow::struct_({ field("archer", utf8()), field("location", utf8()), field("year", int16())}), children[0]->length(), children}; std::cout << arr.ToString() << std::endl;
You can see the similarities to the Python version. We create our struct array by creating the struct type and defining the fields and types for each field, and then just hand it references to the child arrays that it needs. Being able to do this makes building up or splitting apart struct arrays extremely efficient and easy to do, regardless of the complexity of the types. Also, remember that it's not copying the data; the resulting StructArray just references the children arrays instead.
Rather, if you have your data and want to build out the struct array from scratch, we can use StructBuilder. It's very similar to our previous builder example, except the builders for the individual fields are owned by StructBuilder itself and we can build them all up together at one time. This is pretty straightforward and easy if there are no null structs since the validity bitmap can be left out, but if there are any nulls, we need to make sure that the builder is aware of them in order to build the bitmap (see Figure 1.12 for a reminder of the layout of a struct array in memory):
- First, we create our data type:
using arrow::field; std::shared_ptr<arrow::DataType> st_type = arrow::struct_({field("archer", arrow::utf8()), field("location", arrow::utf8()), field("year", arrow::int16())}); - Now, we create our builder:
std::unique_ptr<arrow::ArrayBuilder> tmp; // returns a status, handle the error case arrow::MakeBuilder(arrow::default_memory_pool(), st_type, &tmp); std::shared_ptr<arrow::StructBuilder> builder; builder.reset( static_cast<arrow::StructBuilder*>(tmp.release()));
Some notes to keep in mind with the highlighted lines are as follows:
- By using the
MakeBuildercall as seen in the highlighted line, the builders for our fields will be automatically created for us. It will use the data type that is passed in to determine the correct builder type to construct. - Then, in the second highlighted line, we cast our pointer to
ArrayBuilderto aStructBuilderpointer.
- Now we can append the data we need to, and since we know the types of the fields, we can just use the same technique of casting pointers in order to be able to use the field builders. Since they are all owned by the struct builder itself, we can just use raw pointers:
using namespace arrow; StringBuilder* archer_builder = static_cast< StringBuilder*>(builder->field_builder(0)); StringBuilder* location_builder = static_cast<StringBuilder*>(builder->field_builder(1)); Int16Builder* year_builder = static_cast<Int16Builder*>(builder->field_builder(2));
- Finally, now that we've got our individual builders, we can append whatever values we need to them as long as we make sure that when we call
Finishon the struct builder, all of the field builders must have the same number of values. If there are any null structs, you can call theAppend,AppendNull, orAppendValuesfunctions on the struct builder to indicate which indexes are valid and which are null. Just as with the field builders, this must either be left out entirely (if there are no nulls) or equal to the same number of values in each of the fields. - And, of course, the last step, just like before, is to call
Finishon the struct builder:std::shared_ptr<arrow::Array> out; builder->Finish(&out); std::cout << out->ToString() << std::endl;
Now that we've covered building arrays in C++, here's an exercise for you to try out!
An exercise for you
Try doing the same exercise from the Python section but with C++, converting std::vector<row> to an Arrow record batch where row is defined as the following:
struct row {
int64_t id;
double cost;
std::vector<double> cost_components;
};
Then, write a function to convert the record batch back into the row-oriented representation of std::vector<row>.
Go Arrow go!
The Golang Arrow library is the one I've been most directly involved in the development of and is also very easy to install and use, just like the pyarrow library. Most IDEs will have a plugin for developing in Go, so you can set up your preferred IDE and environment for writing code, and then the following commands will set you up with downloading the Arrow library for import:
$ mkdir arrow_chapter1 && cd arrow_chapter1 $ go mod init arrow_chapter1 $ go get -u github.com/apache/arrow/go/v7/arrow@v7
Tip
If you're not familiar with Go, the Tour of Go is an excellent introduction to the language and can be found here: https://tour.golang.org/.
By this point, I think you can guess what our first example is going to be; just create a file with the .go extension in the directory you created:
package main
import (
"fmt"
"github.com/apache/arrow/go/v7/arrow/array"
"github.com/apache/arrow/go/v7/arrow/memory"
)
func main() {
bldr := array.NewInt64Builder(memory.DefaultAllocator)
defer bldr.Release()
bldr.AppendValues([]int64{1, 2, 3, 4}, nil)
arr := bldr.NewArray()
defer arr.Release()
fmt.Println(arr)
}
Just as we started with the C++ and Python libraries, this is a minimal Go file that creates an Int64 array with the values [1, 2, 3, 4] and prints it out to the terminal. The builder pattern that we saw in the C++ library is also the same pattern that the Go library utilizes; the big difference between them is the highlighted lines. You can run the example with the go run command:
$ go run . [1, 2, 3, 4]
Because Go is a garbage-collected language, there's less direct control over exactly when a value is cleaned up or memory is deallocated. While in C++ we have shared_ptr and unique_ptr objects, there is not an equivalent construct in Go. To allow that more granular control, the library adds function calls for Retain and Release on most of the constructs such as arrays. These present a way to perform reference counting on your values using Retain to ensure that the underlying data stays alive, particularly when passing through channels or other cases where internal memory might get undesirably garbage-collected, and Release to free up the internal references to the memory so it can get garbage-collected earlier than the array object itself. If you're unfamiliar with it, the defer keyword marks a function to be called just before the enclosing function, not necessarily the scope, ends. Calls that are deferred will execute in the reverse order that they appear in code, similar to C++ destructors.
Let's create the same second example, populating arrays with random data and creating a record batch:
- We can import the standard
randlibrary for generating our random values. Technically, it generates a pseudo-random value between0and1.0(not including1) that we could combine with some math to increase the range of values, but for the purposes of this example, that's not necessary:import ( "math/rand" … "github.com/apache/arrow/go/v7/arrow" … )
- Next, we just create our builder that we can use and re-use to append values to, just like before:
fltBldr := array.NewFloat64Builder(memory.DefaultAllocator) defer fltBldr.Release()
The usage of memory.DefaultAllocator is equivalent to the call of arrow::default_memory_pool in the C++ library, referring to a default allocator that is initialized for the process. Alternately, you could call memory.NewGoAllocator or otherwise.
- As in the C++ example, we need a list of column arrays and a list of fields to build a schema from, so let's create the slices:
const ncols = 16 columns := make([]arrow.Array, ncols) fields := make([]arrow.Field, ncols)
- Then, we can add our random data to the builder and create our columns:
const nrows = 8192 for i := range columns { for j := 0; j < nrows; j++ { fltBldr.Append(rand.Float64()) } columns[i] = fltBlder.NewArray() defer columns[i].Release() fields[i] = arrow.Field{ Name: "c" + strconv.Itoa(i), Type: arrow.PrimitiveTypes.Float64} }
As with the other two libraries, we need to specify the type for our field.
- Finally, we create our record batch and print it out:
record := array.NewRecord(arrow.NewSchema(fields, nil), columns, -1) defer record.Release() fmt.Println(record)
When creating the new record, we have to create a schema from the list of fields. The nil that is passed in there represents that we're not providing any schema-level metadata for this record. Schemas can contain metadata at the top level and each individual field can also contain metadata.
The -1 value that we pass is the numRows argument that also existed in the other libraries. We could have used columns[0].Len() to know the length, but by passing -1, we can have the number of rows lazily determined by the record itself rather than us having to pass it in.
We can see all the same conceptual trappings across different libraries:
- Record batches are made up of a group of same length arrays with a schema.
- A schema is a list of fields, where each field contains a name, type, and some metadata.
- A single array knows its type and has the raw data, but a name and metadata must be tied to a
Fieldobject.
I bet you can guess the next example we're going to code up!
Building a struct array, yet again!
Building nested type arrays in Go is closer to the way it is done in the C++ library than in the Python library, but there are still similar steps of creating your struct type, populating each of the constituent arrays, and then finalizing it.
First, we create our type:
archerType := arrow.StructOf(
arrow.Field{Name: "archer", Type: arrow.BinaryTypes.String},
arrow.Field{Name: "location", Type: arrow.BinaryTypes.String},
arrow.Field{Name: "year", Type: arrow.PrimitiveTypes.Int16})
Just like before, there's two ways to go about it:
- Build each constituent array separately and then join references to them together into a single struct array:
mem := memory.DefaultAllocator namesBldr := array.NewStringBuilder(mem) defer namesBldr.Release() locationsBldr := array.NewStringBuilder(mem) defer locationsBldr.Release() yearsBldr := array.NewInt16Builder(mem) defer yearsBldr.Release() // populate the builders and create the arrays named names, // locations, and years data := array.NewData(archerType, names.Len(), []*memory.Buffer{nil}, []arrow.ArrayData{names.Data(), locations.Data(), years.Data()}, 0, 0) defer data.Release() archers := array.NewStructData(data) defer archers.Release() fmt.Println(archers)
Breaking down the highlighted line, which is something new, in both the C++ and Go libraries, there is the concept of ArrayData, which is contained within each array. It contains the pieces mentioned before that make up the array: the type, the buffers, the length, the null count, any children arrays, and the optional dictionary. In the highlighted line, we create a new Data object, which has its own reference count, and initialize it with the struct type we created, the length of our struct, and a slice made up of the pointers to the Data objects of each of the field arrays. Remember, struct arrays only have one buffer, a null bitmap, which can be left out if there are no nulls, so we pass a nil buffer as []*memory.Buffer{nil}.
- The other option is to use a struct builder directly and build up all of the constituent arrays simultaneously. If you don't already have the arrays from something else, this is the easier and more efficient option:
// archerType is the struct type from before, and lets // assume the data is in a slice of archer structs // named archerList bldr := array.NewStructBuilder(memory.DefaultAllocator, archerType) defer bldr.Release() f1b := bldr.FieldBuilder(0).(*array.StringBuilder) f2b := bldr.FieldBuilder(1).(*array.StringBuilder) f3b := bldr.FieldBuilder(2).(*array.Int16Builder) for _, ar := range archerList { bldr.Append(true) f1b.Append(ar.archer) f2b.Append(ar.location) f3b.Append(ar.year) } archers := bldr.NewStructArray() defer archers.Release() fmt.Println(archers)
Just like in the C++ example before, the field builders are owned by the struct builder itself, so we just assert the types of the appropriate builder so we can call Append on them.
In the last highlighted line, we call Append on the struct builder itself so the builder keeps track that it is a non-null struct we are adding. We could pass false there to tell the builder to add a null struct, or we can call the AppendNull function to do the same.
An exercise for you (yes, it's the same one)
Try using the Arrow library for Go to write a function that takes a row-oriented slice of structs and converts them into an Arrow record batch, and vice versa. Use the following type definition:
type datarow struct {
id int64
cost float64
costComponents []float64
}
You should probably be pretty good at this by now if you did this exercise in the Python and C++ libraries already!

