






















































Using SQL operators for data quality
Good data quality is crucial for an organization to ensure the effectiveness of its data systems. By performing quality checks within the DAG, it is possible to stop pipelines and notify stakeholders before erroneous data is introduced into a production lake or warehouse.
Although plenty of available tools in the market provide data quality checks, one of the most popular ways to do this is by running SQL queries. As you may have already guessed, Airflow has providers to support those operations.
This recipe will cover the data quality principal topics in the data ingestion process, pointing out the best SQLOperator type to run in those situations.
Getting ready
Before starting our exercise, let’s create a simple Entity Relationship Diagram (ERD) for a customers table. You can see here how it looks:
Figure 10.40 – An example of customers table columns
And the same table is represented with its schema:
CREATE TABLE customers ( customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(20), address VARCHAR(200), city VARCHAR(50), state VARCHAR(50), country VARCHAR(50), zip_code VARCHAR(20) );
You don’t need to worry about creating this table in a SQL database. This exercise will focus on the data quality factors to be checked, using this table as an example.
How to do it…
Here are the steps to perform this recipe:
- Let’s start by defining the essential data quality checks that apply as follows:
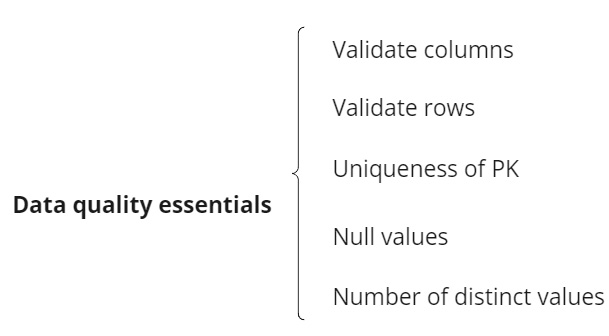
Figure 10.41 – Data quality essential points
- Let’s imagine implementing it using
SQLColumnCheckOperator, integrated and installed in our Airflow platform. Let’s now create a simple task to check whether our table has unique IDs and whether all customers havefirst_name. Our example code looks like this:id_username_check = SQLColumnCheckOperator( task_id="id_username_check", conn_id= my_conn, table=my_table, column_mapping={ "customer_id": { "null_check": { "equal_to": 0, "tolerance": 0, }, "distinct_check": { "equal_to": 1, }, }, "first_name": { "null_check": {"equal_to": 0}, }, } ) - Now, let’s validate whether we ingest the required count of rows using
SQLTableCheckOperator, as follows:customer_table_rows_count = SQLTableCheckOperator( task_id="customer_table_rows_count", conn_id= my_conn, table=my_table, checks={"row_count_check": { "check_statement": "COUNT(*) >= 1000" } } ) - Finally, let’s ensure the customers in our database have at least one order. Our example code looks like this:
count_orders_check = SQLColumnCheckOperator( task_id="check_columns", conn_id=my-conn, table=my_table, column_mapping={ "MY_NUM_COL": { "min": {"geq_to ": 1} } } )
The geq_to key stands for great or equal to.
How it works…
Data quality is a complex topic encompassing many variables, such as the project or company context, business models, and Service Level Agreements (SLAs) between teams. Based on this, the goal of this recipe was to offer the core concept of data quality and demonstrate how to first approach using Airflow SQLOperators.
Let’s start with the essential topics in step 1, as follows:

Figure 10.42 – Data quality essential points
In a generic scenario, those items are the principal topics to be approached and implemented. They will guarantee the minimum data reliability, based on whether the columns are the ones we expected, creating an average value for the row count, ensuring the IDs are unique, and having control of the null and distinct values in specific columns.
Using Airflow, we used the SQL approach to check data. As mentioned at the beginning of this recipe, SQL checks are widespread and popular due to their simplicity and flexibility. Unfortunately, to simulate a scenario like this, we would be required to set up a hard-working local infrastructure, and the best we could come up with is simulating the tasks in Airflow.
Here, we used two SQLOperator subtypes – SQLColumnCheckOperator and SQLTableCheckOperator. As the name suggests, the first operator is more focused on verifying the column’s content by checking whether there are null or distinct values. In the case of customer_id, we verified both scenarios and only null values for first_name, as you can see here:
column_mapping={
"customer_id": {
"null_check": {
"equal_to": 0,
"tolerance": 0,
},
"distinct_check": {
"equal_to": 1,
},
},
"first_name": {
"null_check": {"equal_to": 0},
},
}
SQLTableCheckOperator will perform validations across the whole table. It allows the insertion of a SQL query to make counts or other operations, as we did to validate the expected number of rows in step 3, as you can see in the piece of code here:
checks={"row_count_check": {
"check_statement": "COUNT(*) >= 1000"
}
}
However, SQLOperator is not limited to these two. In the Airflow documentation, you can see other examples and the complete list of accepted parameters for these functions: https://airflow.apache.org/docs/apache-airflow/2.1.4/_api/airflow/operators/sql/index.html#module-airflow.operators.sql.
A fantastic operator to check out is SQLIntervalCheckOperator, used to validate historical data and ensure the stored information is concise.
In your data career, you will see that data quality is a daily topic and concern among teams. The best advice here is to continually search for tools and methods to improve this methodology.
There’s more…
We can use additional tools to enhance our data quality checks. One of the recommended tools for this use is GreatExpectations, an open source platform made in Python with plenty of integrations, with resources such as Airflow, AWS S3, and Databricks.
Although it is a platform you can install in any cluster, GreatExpectations is expanding toward a managed cloud version. You can check more about it on the official page here: https://greatexpectations.io/integrations.
See also
- Yu Ishikawa has a nice blog post about other checks you can do using SQL in Airflow: https://yu-ishikawa.medium.com/apache-airflow-as-a-data-quality-checker-416ca7f5a3ad
- More information about data quality in Airflow is available here: https://docs.astronomer.io/learn/data-quality


