






















































Introduction
The previous chapter provided a primer to Python programming and an overview of the data science field. Data science is a relatively young multidisciplinary field of study. It draws its concepts and methods from the traditional fields of statistics, computer science, and the broad field of artificial intelligence (AI), especially the subfield of AI called machine learning:
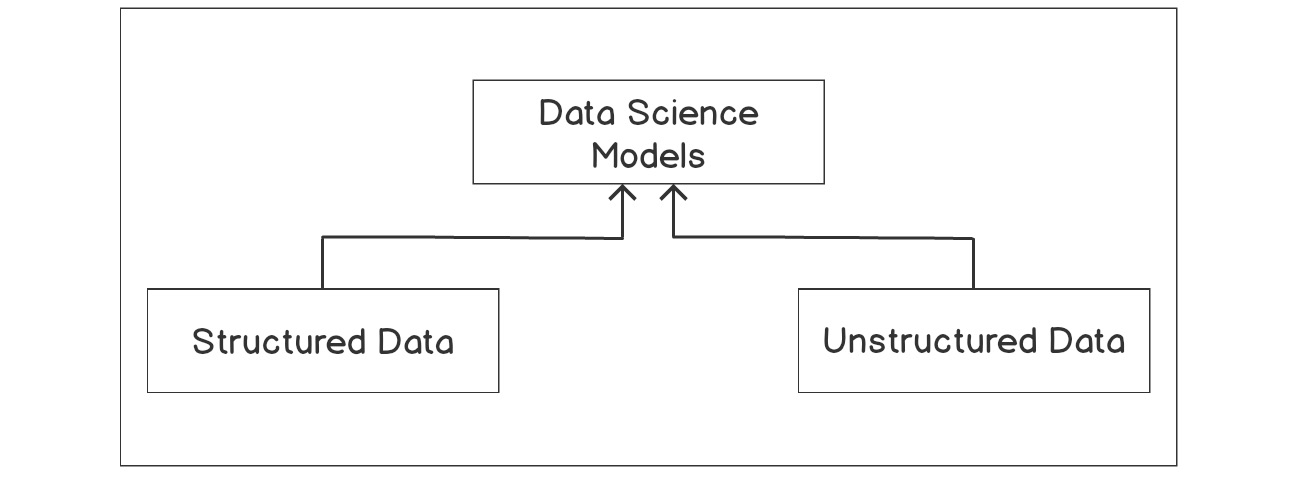
Figure 2.1: The data science models
As you can see in Figure 2.1, data science aims to make use of both structured and unstructured data, develop models that can be effectively used, make predictions, and also derive insights for decision making.
A loose description of structured data will be any set of data that can be conveniently arranged into a table that consists of rows and columns. This kind of data is normally stored in database management systems.
Unstructured data, however, cannot be conveniently stored in tabular form – an example of such a dataset is a text document. To achieve the objectives of data science, a flexible programming language that effectively combines interactivity with computing power and speed is necessary. This is where the Python programming language meets the needs of data science and, as mentioned in Chapter 1, Introduction to Data Science in Python, we will be using Python in this book.
The need to develop models to make predictions and to gain insights for decisionmaking cuts across many industries. Data science is, therefore, finding uses in many industries, including healthcare, manufacturing and the process industries in general, the banking and finance sectors, marketing and e-commerce, the government, and education.
In this chapter, we will be specifically be looking at regression, which is one of the key methods that is used regularly in data science, in order to model relationships between variables, where the target variable (that is, the value you're looking for) is a real number.
Consider a situation where a real estate business wants to understand and, if possible, model the relationship between the prices of property in a city and knowing the key attributes of the properties. This is a data science problem and it can be tackled using regression.
This is because the target variable of interest, which is the price of a property, is a real number. Examples of the key attributes of a property that can be used to predict its value are as follows:
- The age of the property
- The number of bedrooms in a property
- Whether the property has a pool or not
- The area of land the property covers
- The distance of the property from facilities such as railway stations and schools
Regression analysis can be employed to study this scenario, in which you have to create a function that maps the key attributes of a property to the target variable, which, in this case, is the price of a property.
Regression analysis is part of a family of machine learning techniques called supervised machine learning. It is called supervised because the machine learning algorithm that learns the model is provided a kind of question and answer dataset to learn from. The question here is the key attribute and the answer is the property price for each property that is used in the study, as shown in the following figure:
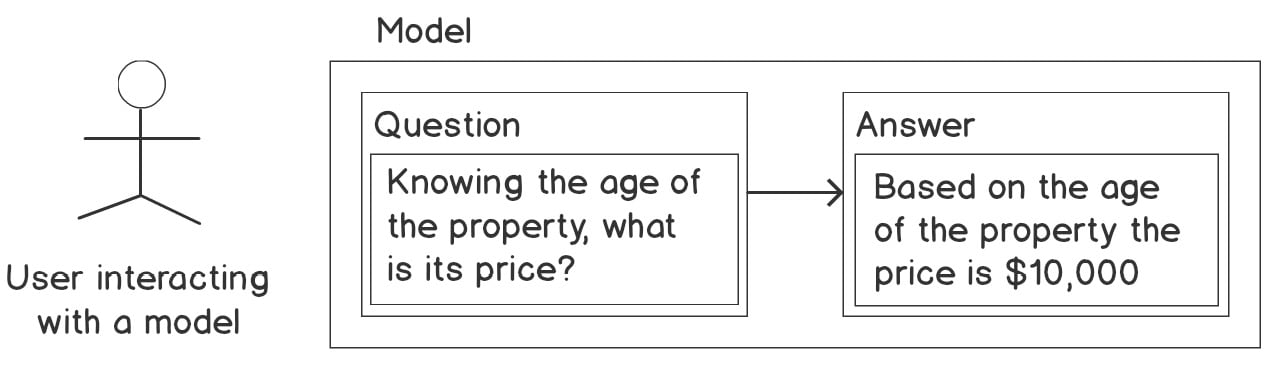
Figure 2.2: Example of a supervised learning technique
Once a model has been learned by the algorithm, we can provide the model with a question (that is, a set of attributes for a property whose price we want to find) for it to tell us what the answer (that is, the price) of that property will be.
This chapter is an introduction to linear regression and how it can be applied to solve practical problems like the one described previously in data science. Python provides a rich set of modules (libraries) that can be used to conduct rigorous regression analysis of various kinds. In this chapter, we will make use of the following Python modules, among others: pandas, statsmodels, seaborn, matplotlib, and scikit-learn.



