Working with other providers
By default, Kubernetes uses the GCE provider for Google Cloud. In order to use other cloud providers, we can explore a rapidly expanding tool set of different options. Let's use AWS for this example, where we have two main options: kops (https://github.com/kubernetes/kops) and kube-aws (https://github.com/kubernetes-incubator/kube-aws). For reference, the following KUBERNETES_PROVIDER are listed in this table:
Provider | KUBERNETES_PROVIDER value | Type |
Google Compute Engine |
| Public cloud |
Google Container Engine |
| Public cloud |
Amazon Web Services |
| Public cloud |
Microsoft Azure |
| Public cloud |
Hashicorp vagrant |
| Virtual development environment |
VMware vSphere |
| Private cloud/on-premise virtualization |
|
| Virtualization management tool |
Canonical Juju (folks behind Ubuntu) |
| OS service orchestration tool |
CLI setup
Let's try setting up the cluster on AWS. As a prerequisite, we need to have the AWS CLI installed and configured for our account. The AWS CLI installation and configuration documentation can be found at the following links:
- Installation documentation: http://docs.aws.amazon.com/cli/latest/userguide/installing.html#install-bundle-other-os
- Configuration documentation: http://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-started.html
You'll also need to configure your credentials as recommended by AWS (refer to https://docs.aws.amazon.com/sdk-for-go/v1/developer-guide/configuring-sdk.html#specifying-credentials) in order to use kops. To get started, you'll need to first install the CLI tool (refer to https://github.com/kubernetes/kops/blob/master/docs/install.md). If you're running on Linux, you can install the tools as follows:
curl -Lo kops https://github.com/kubernetes/kops/releases/download/$(curl -s https://api.github.com/repos/kubernetes/kops/releases/latest | grep tag_name | cut -d '"' -f 4)/kops-darwin-amd64 chmod +x ./kops sudo mv ./kops /usr/local/bin/
If you're installing this for macOS, you can use brew update && brew install kops from the command-line Terminal. As a reminder, you'll need kubectl installed if you haven't already! Check the instructions in the preceding links to confirm the installation.
IAM setup
In order for us to use kops, we'll need an IAM role created in AWS with the following permissions:
AmazonEC2FullAccess AmazonRoute53FullAccess AmazonS3FullAccess IAMFullAccess AmazonVPCFullAccess
Once you've created those pieces manually in the AWS GUI, you can run the following commands from your PC to set up permissions with the correct access:
aws iam create-group --group-name kops aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonEC2FullAccess --group-name kops aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonRoute53FullAccess --group-name kops aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess --group-name kops aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/IAMFullAccess --group-name kops aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonVPCFullAccess --group-name kops aws iam create-user --user-name kops aws iam add-user-to-group --user-name kops --group-name kops aws iam create-access-key --user-name kops
In order to use this newly created kops user to interact with the kops tool, you need to copy down the SecretAccessKey and AccessKeyID from the output JSON, and then configure the AWS CLI as follows:
# configure the aws client to use your new IAM user aws configure # Use your new access and secret key here aws iam list-users # you should see a list of all your IAM users here # Because "aws configure" doesn't export these vars for kops to use, we export them now export AWS_ACCESS_KEY_ID=$(aws configure get aws_access_key_id) export AWS_SECRET_ACCESS_KEY=$(aws configure get aws_secret_access_key)
We're going to use a gossip-based cluster to bypass a kops configuration requirement of public DNS zones. This requires kops 1.6.2 or later, and allows you to create a locally registered cluster that requires a name ending in .k8s.local. More on that in a bit.
Note
If you'd like to explore how to purchase and set up publicly routable DNS through a provider, you can review the available scenarios in the kops documentation here: https://github.com/kubernetes/kops/blob/master/docs/aws.md#configure-dns.
Cluster state storage
Since we're building resources in the cloud using configuration management, we're going to need to store the representation of our cluster in a dedicated S3 bucket. This source of truth will allow us to maintain a single location for the configuration and state of our Kubernetes cluster. Please prepend your bucket name with a unique value.
Note
You'll need to have kubectl, kops, the aws cli, and IAM credentials set up for yourself at this point!
Be sure to create your bucket in the us-east-1 region for now, as kops is currently opinionated as to where the bucket belongs:
aws s3api create-bucket \ --bucket gsw-k8s-3-state-store \ --region us-east-1
Let's go ahead and set up versioning as well, so you can roll your cluster back to previous states in case anything goes wrong. Behold the power of Infrastructure as Code!
aws s3api put-bucket-versioning --bucket gsw-k8s-3-state-store --versioning-configuration Status=EnabledCreating your cluster
We'll go ahead and use the .k8s.local settings mentioned previously to simplify the DNS setup of the cluster. If you'd prefer, you can also use the name and state flags available within kops to avoid using environment variables. Let's prepare the local environment first:
$ export NAME=gswk8s3.k8s.local $ export KOPS_STATE_STORE=s3://gsw-k8s-3-state-store $ aws s3api create-bucket --bucket gsw-k8s-3-state-store --region us-east-1 { "Location": "/gsw-k8s-3-state-store" } $
Let's spin up our cluster in Ohio, and verify that we can see that region first:
$ aws ec2 describe-availability-zones --region us-east-2 { "AvailabilityZones": [ { "State": "available", "ZoneName": "us-east-2a", "Messages": [], "RegionName": "us-east-2" }, { "State": "available", "ZoneName": "us-east-2b", "Messages": [], "RegionName": "us-east-2" }, { "State": "available", "ZoneName": "us-east-2c", "Messages": [], "RegionName": "us-east-2" } ] }
Great! Let's make some Kubernetes. We're going to use the most basic kops cluster command available, though there are much more complex examples available in the documentation (https://github.com/kubernetes/kops/blob/master/docs/high_availability.md):
kops create cluster --zones us-east-2a ${NAME}With kops and generally with Kubernetes, everything is going to be created within Auto Scaling groups (ASGs).
Note
Read more about AWS autoscaling groups here—they're essential: https://docs.aws.amazon.com/autoscaling/ec2/userguide/AutoScalingGroup.html.
Once you run this command, you'll get a whole lot of configuration output in what we call a dry run format. This is similar to the Terraform idea of a Terraform plan, which lets you see what you're about to build in AWS and lets you edit the output accordingly.
At the end of the output, you'll see the following text, which gives you some basic suggestions on the next steps:
Must specify --yes to apply changes Cluster configuration has been created. Suggestions: * list clusters with: kops get cluster * edit this cluster with: kops edit cluster gwsk8s3.k8s.local * edit your node instance group: kops edit ig --name=gwsk8s3.k8s.local nodes * edit your master instance group: kops edit ig --name=gwsk8s3.k8s.local master-us-east-2a Finally configure your cluster with: kops update cluster gwsk8s3.k8s.local --yes
Note
If you don't have an SSH keypair in your ~/.ssh directory, you'll need to create one. This article will lead you through the steps: https://help.github.com/articles/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent/.
Once you've confirmed that you like the look of the output, you can create the cluster:
kops update cluster gwsk8s3.k8s.local --yesThis will give you a lot of output about cluster creation that you can follow along with:
I0320 21:37:34.761784 29197 apply_cluster.go:450] Gossip DNS: skipping DNS validation I0320 21:37:35.172971 29197 executor.go:91] Tasks: 0 done / 77 total; 30 can run I0320 21:37:36.045260 29197 vfs_castore.go:435] Issuing new certificate: "apiserver-aggregator-ca" I0320 21:37:36.070047 29197 vfs_castore.go:435] Issuing new certificate: "ca" I0320 21:37:36.727579 29197 executor.go:91] Tasks: 30 done / 77 total; 24 can run I0320 21:37:37.740018 29197 vfs_castore.go:435] Issuing new certificate: "apiserver-proxy-client" I0320 21:37:37.758789 29197 vfs_castore.go:435] Issuing new certificate: "kubecfg" I0320 21:37:37.830861 29197 vfs_castore.go:435] Issuing new certificate: "kube-controller-manager" I0320 21:37:37.928930 29197 vfs_castore.go:435] Issuing new certificate: "kubelet" I0320 21:37:37.940619 29197 vfs_castore.go:435] Issuing new certificate: "kops" I0320 21:37:38.095516 29197 vfs_castore.go:435] Issuing new certificate: "kubelet-api" I0320 21:37:38.124966 29197 vfs_castore.go:435] Issuing new certificate: "kube-proxy" I0320 21:37:38.274664 29197 vfs_castore.go:435] Issuing new certificate: "kube-scheduler" I0320 21:37:38.344367 29197 vfs_castore.go:435] Issuing new certificate: "apiserver-aggregator" I0320 21:37:38.784822 29197 executor.go:91] Tasks: 54 done / 77 total; 19 can run I0320 21:37:40.663441 29197 launchconfiguration.go:333] waiting for IAM instance profile "nodes.gswk8s3.k8s.local" to be ready I0320 21:37:40.889286 29197 launchconfiguration.go:333] waiting for IAM instance profile "masters.gswk8s3.k8s.local" to be ready I0320 21:37:51.302353 29197 executor.go:91] Tasks: 73 done / 77 total; 3 can run I0320 21:37:52.464204 29197 vfs_castore.go:435] Issuing new certificate: "master" I0320 21:37:52.644756 29197 executor.go:91] Tasks: 76 done / 77 total; 1 can run I0320 21:37:52.916042 29197 executor.go:91] Tasks: 77 done / 77 total; 0 can run I0320 21:37:53.360796 29197 update_cluster.go:248] Exporting kubecfg for cluster kops has set your kubectl context to gswk8s3.k8s.local
As with GCE, the setup activity will take a few minutes. It will stage files in S3 and create the appropriate instances, Virtual Private Cloud (VPC), security groups, and so on in our AWS account. Then, the Kubernetes cluster will be set up and started. Once everything is finished and started, we should see some options on what comes next:
Cluster is starting. It should be ready in a few minutes. Suggestions: * validate cluster: kops validate cluster * list nodes: kubectl get nodes --show-labels * ssh to the master: ssh -i ~/.ssh/id_rsa admin@api.gswk8s3.k8s.local The admin user is specific to Debian. If not using Debian please use the appropriate user based on your OS. * read about installing addons: https://github.com/kubernetes/kops/blob/master/docs/addons.md
You'll be able to see instances and security groups, and a VPC will be created for your cluster. The kubectl context will also be pointed at your new AWS cluster so that you can interact with it:
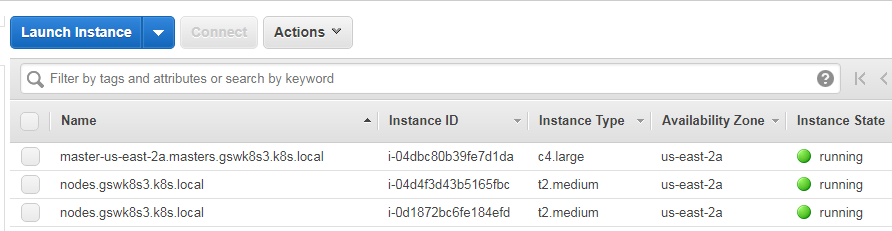
Once again, we will SSH into master. This time, we can use the native SSH client and the admin user as the AMI for Kubernetes in kops is Debian. We'll find the key files in /home/<username>/.ssh:
$ ssh -v -i /home/<username>/.ssh/<your_id_rsa_file> admin@<Your master IP>If you have trouble with your SSH key, you can set it manually on the cluster by creating a secret, adding it to the cluster, and checking if the cluster requires a rolling update:
$ kops create secret --name gswk8s3.k8s.local sshpublickey admin -i ~/.ssh/id_rsa.pub $ kops update cluster --yes Using cluster from kubectl context: gswk8s3.k8s.local I0320 22:03:42.823049 31465 apply_cluster.go:450] Gossip DNS: skipping DNS validation I0320 22:03:43.220675 31465 executor.go:91] Tasks: 0 done / 77 total; 30 can run I0320 22:03:43.919989 31465 executor.go:91] Tasks: 30 done / 77 total; 24 can run I0320 22:03:44.343478 31465 executor.go:91] Tasks: 54 done / 77 total; 19 can run I0320 22:03:44.905293 31465 executor.go:91] Tasks: 73 done / 77 total; 3 can run I0320 22:03:45.385288 31465 executor.go:91] Tasks: 76 done / 77 total; 1 can run I0320 22:03:45.463711 31465 executor.go:91] Tasks: 77 done / 77 total; 0 can run I0320 22:03:45.675720 31465 update_cluster.go:248] Exporting kubecfg for cluster kops has set your kubectl context to gswk8s3.k8s.local Cluster changes have been applied to the cloud. Changes may require instances to restart: kops rolling-update cluster $ kops rolling-update cluster --name gswk8s3.k8s.local NAME STATUS NEEDUPDATE READY MIN MAX NODES master-us-east-2a Ready 0 1 1 1 1 nodes Ready 0 2 2 2 2 No rolling-update required. $
Once you've gotten into the cluster master, we can look at the containers. We'll use sudo docker ps --format 'table {{.Image}}t{{.Status}}' to explore the running containers. We should see the following:
admin@ip-172-20-47-159:~$ sudo docker container ls --format 'table {{.Image}}\t{{.Status}}' IMAGE STATUS kope/dns-controller@sha256:97f80ad43ff833b254907a0341c7fe34748e007515004cf0da09727c5442f53b Up 29 minutes gcr.io/google_containers/pause-amd64:3.0 Up 29 minutes gcr.io/google_containers/kube-apiserver@sha256:71273b57d811654620dc7a0d22fd893d9852b6637616f8e7e3f4507c60ea7357 Up 30 minutes gcr.io/google_containers/etcd@sha256:19544a655157fb089b62d4dac02bbd095f82ca245dd5e31dd1684d175b109947 Up 30 minutes gcr.io/google_containers/kube-proxy@sha256:cc94b481f168bf96bd21cb576cfaa06c55807fcba8a6620b51850e1e30febeb4 Up 30 minutes gcr.io/google_containers/kube-controller-manager@sha256:5ca59252abaf231681f96d07c939e57a05799d1cf876447fe6c2e1469d582bde Up 30 minutes gcr.io/google_containers/etcd@sha256:19544a655157fb089b62d4dac02bbd095f82ca245dd5e31dd1684d175b109947 Up 30 minutes gcr.io/google_containers/kube-scheduler@sha256:46d215410a407b9b5a3500bf8b421778790f5123ff2f4364f99b352a2ba62940 Up 30 minutes gcr.io/google_containers/pause-amd64:3.0 Up 30 minutes gcr.io/google_containers/pause-amd64:3.0 Up 30 minutes gcr.io/google_containers/pause-amd64:3.0 Up 30 minutes gcr.io/google_containers/pause-amd64:3.0 Up 30 minutes gcr.io/google_containers/pause-amd64:3.0 Up 30 minutes gcr.io/google_containers/pause-amd64:3.0 Up 30 minutes protokube:1.8.1
We can see some of the same containers as our GCE cluster had. However, there are several missing. We can see the core Kubernetes components, but the fluentd-gcp service is missing, as well as some of the newer utilities such as node-problem-detector, rescheduler, glbc, kube-addon-manager, and etcd-empty-dir-cleanup. This reflects some of the subtle differences in the kube-up script between various public cloud providers. This is ultimately decided by the efforts of the large Kubernetes open-source community, but GCP often has many of the latest features first.
You also have a command that allows you to check on the state of the cluster in kops validate cluster, which allows you to make sure that the cluster is working as expected. There's also a lot of handy modes that kops provides that allow you to do various things with the output, provisioners, and configuration of the cluster.
Other modes
There are various other modes to take into consideration, including the following:
- Build a terraform model:
--target=terraform. The terraform model will be built inout/terraform. - Build a cloudformation model:
--target=cloudformation. The Cloudformation JSON file will be built inout/cloudformation. - Specify the K8s build to run:
--kubernetes-version=1.2.2. - Run nodes in multiple zones:
--zones=us-east-1b,us-east-1c,us-east-1d. - Run with a HA master:
--master-zones=us-east-1b,us-east-1c,us-east-1d. - Specify the number of nodes:
--node-count=4. - Specify the node size:
--node-size=m4.large. - Specify the master size:
--master-size=m4.large. - Override the default DNS zone:
--dns-zone=<my.hosted.zone>.
Note
The full list of CLI documentation can be found here: https://github.com/kubernetes/kops/tree/master/docs/cli.
Another tool for diagnosing the cluster status is the componentstatuses command, which will inform you of state of the major Kubernetes moving pieces:
$ kubectl get componentstatuses NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health": "true"}
Resetting the cluster
You just had a little taste of running the cluster on AWS. For the remainder of this book, I will be basing my examples on a GCE cluster. For the best experience following along, you can get back to a GCE cluster easily.
Simply tear down the AWS cluster, as follows:
$ kops delete cluster --name ${NAME} --yesIf you omit the --yes flag, you'll get a similar dry run output that you can confirm. Then, create a GCE cluster again using the following, and in doing so making sure that you're back in the directory where you installed the Kubernetes code:
$ cd ~/<kubernetes_install_dir> $ kube-up.sh
Investigating other deployment automation
If you'd like to learn more about other tools for cluster automation, we recommend that you visit the kube-deploy repository, which has references to community maintained Kubernetes cluster deployment tools.
Note
Visit https://github.com/kubernetes/kube-deploy to learn more.
Local alternatives
The kube-up.sh script and kops are pretty handy ways to get started using Kubernetes on your platform of choice. However, they're not without flaws and can sometimes run aground when conditions are not just so.
Luckily, since K8's inception, a number of alternative methods for creating clusters have emerged. We'd recommend checking out Minikube in particular, as it's an extremely simple and local development environment that you can use to test out your Kubernetes configuration.
This project can be found here: https://github.com/kubernetes/minikube.
Note
It's important to mention that you're going to need a hypervisor on your machine to run Minikube. For Linux, you can use kvm/kvm2, or VirtualBox, and on macOS you can run native xhyve or VirtualBox. For Windows, Hyper-V is the default hypervisor.
The main limitation for this project is that it only runs a single node, which limits our exploration of certain advanced topics that require multiple machines. Minikube is a great resource for simple or local development however, and can be installed very simply on your Linux VM with the following:
$ curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/Or install it on macOS with the following:
$ brew cask install minikubeWe'll cover how to get started with Minikube with the following commands:
$ minikube start Starting local Kubernetes v1.7.5 cluster... Starting VM... SSH-ing files into VM... Setting up certs... Starting cluster components... Connecting to cluster... Setting up kubeconfig... Kubectl is now configured to use the cluster.
You can create a sample deployment quite simply:
$ kubectl run hello-minikube --image=k8s.gcr.io/echoserver:1.4 --port=8080
deployment "hello-minikube" created
$ kubectl expose deployment hello-minikube --type=NodePort
service "hello-minikube" exposed
Once you have your cluster and service up and running, you can interact with it simply by using the kubectl tool and the context command. You can get to the Minikube dashboard with minikube dashboard.
Note
Minikube is powered by localkube (https://github.com/kubernetes/minikube/tree/master/pkg/localkube) and libmachine (https://github.com/docker/machine/tree/master/libmachine). Check them out!
Additionally, we've already referenced a number of managed services, including GKE, EKS, and Microsoft Azure Container Service (ACS), which provide an automated installation and some managed cluster operations.
Starting from scratch
Finally, there is the option to start from scratch. Luckily, starting in 1.4, the Kubernetes team has put a major focus on simplifying the cluster setup process. To that end, they have introduced kubeadm for Ubuntu 16.04, CentOS 7, and HypriotOS v1.0.1+.
Let's take a quick look at spinning up a cluster on AWS from scratch using the kubeadm tool.
Cluster setup
We will need to provision our cluster master and nodes beforehand. For the moment, we are limited to the operating systems and version listed earlier. Additionally, it is recommended that you have at least 1 GB of RAM. All the nodes must have network connectivity to one another.
For this walkthrough, we will need one t2.medium (master node) and three t2.mirco (nodes) sized instances on AWS. These instance have burstable CPU and come with the minimum 1 GB of RAM that's required. We will need to create one master and three worker nodes.
We will also need to create some security groups for the cluster. The following ports are needed for the master:
Type | Protocol | Port range | Source |
All traffic | All | All | {This SG ID (Master SG)} |
All traffic | All | All | {Node SG ID} |
SSH | TCP |
| {Your Local Machine's IP} |
HTTPS | TCP |
| {Range allowed to access K8s API and UI} |
The following table shows the port's node security groups:
Type | Protocol | Port range | Source |
All traffic | All | All | {Master SG ID} |
All traffic | All | All | {This SG ID (Node SG)} |
SSH | TCP |
| {Your Local Machine's IP} |
Once you have these SGs, go ahead and spin up four instances (one t2.medium and three t2.mircos) using Ubuntu 16.04. If you are new to AWS, refer to the documentation on spinning up EC2 instances at the following URL: http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/LaunchingAndUsingInstances.html.
Be sure to identify the t2.medium instance as the master and associate the master security group. Name the other three as nodes and associate the node security group with those.
Note
These steps are adapted from the walk-through in the manual. For more information or to work with an alternative to Ubuntu, refer to https://kubernetes.io/docs/getting-started-guides/kubeadm/.
Installing Kubernetes components (kubelet and kubeadm)
Next, we will need to SSH into all four of the instances and install the Kubernetes components.
As the root user, perform the following steps on all four instances:
- Update the packages and install the
apt-transport-httpspackage so that we can download from sources that use HTTPS:
$ apt-get update $ apt-get install -y apt-transport-https
- Install the Google Cloud public key:
$ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg |
apt-key add -- Next, let's set up the repository:
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet kubeadm kubectl docker.io kubernetes-cni
You'll need to make sure that the cgroup driver used by the kubelet on the master node is configured correctly to work with Docker. Make sure you're on the master node, then run the following:
docker info | grep -i cgroup cat /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
If these items don't match, you're going to need to change the kubelet configuration to match the Docker driver. Running sed -i "s/cgroup-driver=systemd/cgroup-driver=cgroupfs/g" /etc/systemd/system/kubelet.service.d/10-kubeadm.conf should fix the settings, or you can manually open the systemd file and add the correct flag to the appropriate environment. After that's complete, restart the service:
$ systemctl daemon-reload $ systemctl restart kubelet
Setting up a master
On the instance you have previously chosen as master, we will run master initialization. Again, as the root, run the following command, and you should see the following output:
$ kubeadm init
[init] using Kubernetes version: v1.11.3
[preflight] running pre-flight checks
I1015 02:49:42.378355 5250 kernel_validator.go:81] Validating kernel version
I1015 02:49:42.378609 5250 kernel_validator.go:96] Validating kernel config
[preflight/images] Pulling images required for setting up a Kubernetes cluster
[preflight/images] This might take a minute or two, depending on the speed of your internet connection
[preflight/images] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[preflight] Activating the kubelet service
[certificates] Generated ca certificate and key.
[certificates] Generated apiserver certificate and key.
[certificates] apiserver serving cert is signed for DNS names [master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 172.17.0.71]
[certificates] Generated apiserver-kubelet-client certificate and key.
[certificates] Generated sa key and public key.
[certificates] Generated front-proxy-ca certificate and key.
[certificates] Generated front-proxy-client certificate and key.
[certificates] Generated etcd/ca certificate and key.
[certificates] Generated etcd/server certificate and key.
[certificates] etcd/server serving cert is signed for DNS names [master localhost] and IPs [127.0.0.1 ::1]
[certificates] Generated etcd/peer certificate and key.
[certificates] etcd/peer serving cert is signed for DNS names [master localhost] and IPs [172.17.0.71 127.0.0.1 ::1]
[certificates] Generated etcd/healthcheck-client certificate and key.
[certificates] Generated apiserver-etcd-client certificate and key.
[certificates] valid certificates and keys now exist in "/etc/kubernetes/pki"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/admin.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/controller-manager.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/scheduler.conf"
[controlplane] wrote Static Pod manifest for component kube-apiserver to "/etc/kubernetes/manifests/kube-apiserver.yaml"
[controlplane] wrote Static Pod manifest for component kube-controller-manager to "/etc/kubernetes/manifests/kube-controller-manager.yaml"
[controlplane] wrote Static Pod manifest for component kube-scheduler to "/etc/kubernetes/manifests/kube-scheduler.yaml"
[etcd] Wrote Static Pod manifest for a local etcd instance to "/etc/kubernetes/manifests/etcd.yaml"
[init] waiting for the kubelet to boot up the control plane as Static Pods from directory "/etc/kubernetes/manifests"
[init] this might take a minute or longer if the control plane images have to be pulled
[apiclient] All control plane components are healthy after 43.001889 seconds
[uploadconfig] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.11" in namespace kube-system with the configuration for the kubelets in the cluster
[markmaster] Marking the node master as master by adding the label "node-role.kubernetes.io/master=''"
[markmaster] Marking the node master as master by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[patchnode] Uploading the CRI Socket information "/var/run/dockershim.sock" to the Node API object "master" as an annotation
[bootstraptoken] using token: o760dk.q4l5au0jyx4vg6hr
[bootstraptoken] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstraptoken] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstraptoken] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstraptoken] creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join 172.17.0.71:6443 --token o760dk.q4l5au0jyx4vg6hr --discovery-token-ca-cert-hash sha256:453e2964eb9cc0cecfdb167194f60c6f7bd8894dc3913e0034bf0b33af4f40f5
To start using your cluster, you need to run as a regular user:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster. Run kubectl apply -f [podnetwork].yaml with one of the options listed at https://kubernetes.io/docs/concepts/cluster-administration/addons/.
You can now join any number of machines by running the following on each node as root:
kubeadm join --token <token> <master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>Note that initialization can only be run once, so if you run into problems, you'll need to use kubeadm reset.
Joining nodes
After a successful initialization, you will get a join command that can be used by the nodes. Copy this down for the join process later on. It should look similar to this:
$ kubeadm join --token=<some token> <master ip address>The token is used to authenticate cluster nodes, so make sure to store it somewhere securely for future use.
Networking
Our cluster will need a networking layer for the pods to communicate on. Note that kubeadm requires a CNI compatible network fabric. The list of plugins currently available can be found here: http://kubernetes.io/docs/admin/addons/.
For our example, we will use calico. We will need to create the calico components on our cluster using the following yaml. For convenience, you can download it here: http://docs.projectcalico.org/v1.6/getting-started/kubernetes/installation/hosted/kubeadm/calico.yaml.
Once you have this file on your master, create the components with the following command:
$ kubectl apply -f calico.yamlGive this a minute to run setup and then list the kube-system nodes in order to check this:
$ kubectl get pods --namespace=kube-systemYou should get a listing similar to the following one with three new calico pods and one completed job that is not shown:
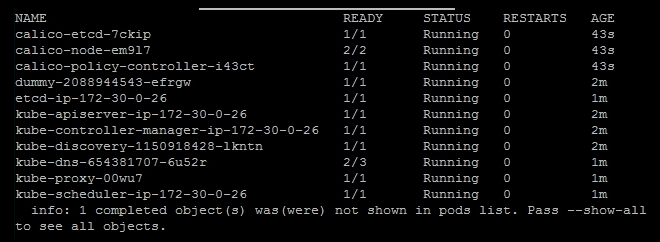
Calico setup
Joining the cluster
Now, we need to run the join command we copied earlier, on each of our node instances:
$ kubeadm join --token=<some token> <master ip address>Once you've finished that, you should be able to see all nodes from the master by running the following command:
$ kubectl get nodesIf all went well, this will show three nodes and one master, as shown here: