






















































Chapter 6. Advanced Concepts – OOP, Decorators, and Iterators
"La classe non è acqua. (Class will out)" | ||
| --Italian saying | ||
I could probably write a small book about object-oriented programming (referred to as OOP henceforth) and classes. In this chapter, I'm facing the hard challenge of finding the balance between breadth and depth. There are simply too many things to tell, and there's plenty of them that would take more than this whole chapter if I described them alone in depth. Therefore, I will try to give you what I think is a good panoramic view of the fundamentals, plus a few things that may come in handy in the next chapters. Python's official documentation will help in filling the gaps.
We're going to explore three important concepts in this chapter: decorators, OOP, and iterators.
Decorators
In the previous chapter, I measured the execution time of various expressions. If you recall, I had to initialize a variable to the start time, and subtract it from the current time after execution in order to calculate the elapsed time. I also printed it on the console after each measurement. That was very tedious.
Every time you find yourself repeating things, an alarm bell should go off. Can you put that code in a function and avoid repetition? The answer most of the time is yes, so let's look at an example.
decorators/time.measure.start.py
from time import sleep, time def f(): sleep(.3) def g(): sleep(.5) t = time() f() print('f took: ', time() - t) # f took: 0.3003859519958496 t = time() g() print('g took:', time() - t) # g took: 0.5005719661712646
In the preceding code, I defined two functions, f and g, which do nothing but sleep (by 0.3 and 0.5 seconds respectively). I used the sleep function to suspend the execution for the desired amount of time. I also highlighted how we calculate the time elapsed by setting t to the current time and then subtracting it when the task is done. You can see that the measure is pretty accurate.
Now, how do we avoid repeating that code and those calculations? One first potential approach could be the following:
decorators/time.measure.dry.py
from time import sleep, time
def f():
sleep(.3)
def g():
sleep(.5)
def measure(func):
t = time()
func()
print(func.__name__, 'took:', time() - t)
measure(f) # f took: 0.30041074752807617
measure(g) # g took: 0.5006198883056641Ah, much better now. The whole timing mechanism has been encapsulated into a function so we don't repeat code. We print the function name dynamically and it's easy enough to code. What if we need to pass arguments to the function we measure? This code would get just a bit more complicated, so let's see an example.
decorators/time.measure.arguments.py
from time import sleep, time def f(sleep_time=0.1): sleep(sleep_time) def measure(func, *args, **kwargs): t = time() func(*args, **kwargs) print(func.__name__, 'took:', time() - t) measure(f, sleep_time=0.3) # f took: 0.3004162311553955 measure(f, 0.2) # f took: 0.20028162002563477
Now, f is expecting to be fed sleep_time (with a default value of 0.1). I also had to change the measure function so that it is now accepting a function, any variable positional arguments, and any variable keyword arguments. In this way, whatever we call measure with, we redirect those arguments to the call to f we do inside.
This is very good, but we can push it a little bit further. Let's say we want to somehow have that timing behavior built-in in the f function, so that we could just call it and have that measure taken. Here's how we could do it:
decorators/time.measure.deco1.py
from time import sleep, time
def f(sleep_time=0.1):
sleep(sleep_time)
def measure(func):
def wrapper(*args, **kwargs):
t = time()
func(*args, **kwargs)
print(func.__name__, 'took:', time() - t)
return wrapper
f = measure(f) # decoration point
f(0.2) # f took: 0.2002875804901123
f(sleep_time=0.3) # f took: 0.3003721237182617
print(f.__name__) # wrapper <- ouch!The preceding code is probably not so straightforward. I confess that, even today, it sometimes requires me some serious concentration to understand some decorators, they can be pretty nasty. Let's see what happens here. The magic is in the decoration point. We basically reassign f with whatever is returned by measure when we call it with f as an argument. Within measure, we define another function, wrapper, and then we return it. So, the net effect is that after the decoration point, when we call f, we're actually calling wrapper. Since the wrapper inside is calling func, which is f, we are actually closing the loop like that. If you don't believe me, take a look at the last line.
wrapper is actually... a wrapper. It takes variable and positional arguments, and calls f with them. It also does the time measurement trick around the call.
This technique is called decoration, and measure is, at all effects, a
decorator. This paradigm became so popular and widely used that at some point, Python added a special syntax for it (check PEP 318). Let's explore three cases: one decorator, two decorators, and one decorator that takes arguments.
decorators/syntax.py
def func(arg1, arg2, ...):
pass
func = decorator(func)
# is equivalent to the following:
@decorator
def func(arg1, arg2, ...):
passBasically, instead of manually reassigning the function to what was returned by the decorator, we prepend the definition of the function with the special syntax @decorator_name.
We can apply multiple decorators to the same function in the following way:
decorators/syntax.py
def func(arg1, arg2, ...):
pass
func = deco1(deco2(func))
# is equivalent to the following:
@deco1
@deco2
def func(arg1, arg2, ...):
passWhen applying multiple decorators, pay attention to the order, should it matter. In the preceding example, func is decorated with deco2 first, and the result is decorated with deco1. A good rule of thumb is: the closer the decorator to the function, the sooner it is applied.
Some decorators can take arguments. This technique is generally used to produce other decorators. Let's look at the syntax, and then we'll see an example of it.
decorators/syntax.py
def func(arg1, arg2, ...):
pass
func = decoarg(argA, argB)(func)
# is equivalent to the following:
@decoarg(argA, argB)
def func(arg1, arg2, ...):
passAs you can see, this case is a bit different. First decoarg is called with the given arguments, and then its return value (the actual decorator) is called with func. Before I give you another example, let's fix one thing that is bothering me. I don't want to lose the original function name and docstring (and the other attributes as well, check the documentation for the details) when I decorate it. But because inside our decorator we return wrapper, the original attributes from func are lost and f ends up being assigned the attributes of wrapper. There is an easy fix for that from functools, a wonderful module from the Python standard library. I will fix the last example, and I will also rewrite its syntax to use the @ operator.
decorators/time.measure.deco2.py
from time import sleep, time from functools import wraps def measure(func): @wraps(func) def wrapper(*args, **kwargs): t = time() func(*args, **kwargs) print(func.__name__, 'took:', time() - t) return wrapper @measure def f(sleep_time=0.1): """I'm a cat. I love to sleep! """ sleep(sleep_time) f(sleep_time=0.3) # f took: 0.30039525032043457 print(f.__name__, ':', f.__doc__) # f : I'm a cat. I love to sleep!
Now we're talking! As you can see, all we need to do is to tell Python that wrapper actually wraps func (by means of the wraps function), and you can see that the original name and docstring are now maintained.
Let's see another example. I want a decorator that prints an error message when the result of a function is greater than a threshold. I will also take this opportunity to show you how to apply two decorators at once.
decorators/two.decorators.py
from time import sleep, time
from functools import wraps
def measure(func):
@wraps(func)
def wrapper(*args, **kwargs):
t = time()
result = func(*args, **kwargs)
print(func.__name__, 'took:', time() - t)
return result
return wrapper
def max_result(func):
@wraps(func)
def wrapper(*args, **kwargs):
result = func(*args, **kwargs)
if result > 100:
print('Result is too big ({0}). Max allowed is 100.'
.format(result))
return result
return wrapper
@measure
@max_result
def cube(n):
return n ** 3
print(cube(2))
print(cube(5))Tip
Take your time in studying the preceding example until you are sure you understand it well. If you do, I don't think there is any decorator you won't be able to write afterwards.
I had to enhance the measure decorator, so that its wrapper now returns the result of the call to func. The max_result decorator does that as well, but before returning, it checks that result is not greater than 100, which is the maximum allowed.
I decorated cube with both of them. First, max_result is applied, then measure. Running this code yields this result:
$ python two.decorators.py cube took: 7.62939453125e-06 # 8 # Result is too big (125). Max allowed is 100. cube took: 1.1205673217773438e-05 125
For your convenience, I put a # to the right of the results of the first call: print(cube(2)). The result is 8, and therefore it passes the threshold check silently. The running time is measured and printed. Finally, we print the result (8).
On the second call, the result is 125, so the error message is printed, the result returned, and then it's the turn of measure, which prints the running time again, and finally, we print the result (125).
Had I decorated the cube function with the same two decorators but in a different order, the error message would follow the line that prints the running time, instead of preceding it.
A decorator factory
Let's simplify this example now, going back to a single decorator: max_result. I want to make it so that I can decorate different functions with different thresholds, and I don't want to write one decorator for each threshold. Let's amend max_result so that it allows us to decorate functions specifying the threshold dynamically.
decorators/decorators.factory.py
from functools import wraps def max_result(threshold): def decorator(func): @wraps(func) def wrapper(*args, **kwargs): result = func(*args, **kwargs) if result > threshold: print( 'Result is too big ({0}). Max allowed is {1}.' .format(result, threshold)) return result return wrapper return decorator @max_result(75) def cube(n): return n ** 3 print(cube(5))
This preceding code shows you how to write a decorator factory. If you recall, decorating a function with a decorator that takes arguments is the same as writing func = decorator(argA, argB)(func), so when we decorate cube with max_result(75), we're doing cube = max_result(75)(cube).
Let's go through what happens, step by step. When we call max_result(75), we enter its body. A decorator function is defined inside, which takes a function as its only argument. Inside that function, the usual decorator trick is performed. We define a wrapper, inside of which we check the result of the original function's call. The beauty of this approach is that from the innermost level, we can still refer to both func and threshold, which allows us to set the threshold dynamically.
wrapper returns result, decorator returns wrapper, and max_result returns decorator. This means that our call cube = max_result(75)(cube), actually becomes cube = decorator(cube). Not just any decorator though, but one for which threshold has the value 75. This is achieved by a mechanism called closure, which is outside of the scope of this chapter but nonetheless very interesting, so I mentioned it for you to do some research on it.
Running the last example produces the following result:
$ python decorators.factory.py Result is too big (125). Max allowed is 75. 125
The preceding code allows me to use the max_result decorator with different thresholds at my own will, like this:
decorators/decorators.factory.py
@max_result(75) def cube(n): return n ** 3 @max_result(100) def square(n): return n ** 2 @max_result(1000) def multiply(a, b): return a * b
Note that every decoration uses a different threshold value.
Decorators are very popular in Python. They are used quite often and they simplify (and beautify, I dare say) the code a lot.
Object-oriented programming
It's been quite a long and hopefully nice journey and, by now, we should be ready to explore object-oriented programming. I'll use the definition from Kindler, E.; Krivy, I. (2011). Object-Oriented Simulation of systems with sophisticated control. International Journal of General Systems, and adapt it to Python:
Object-oriented programming (OOP) is a programming paradigm based on the concept of "objects", which are data structures that contain data, in the form of attributes, and code, in the form of functions known as methods. A distinguishing feature of objects is that an object's method can access and often modify the data attributes of the object with which they are associated (objects have a notion of "self"). In OO programming, computer programs are designed by making them out of objects that interact with one another.
Python has full support for this paradigm. Actually, as we have already said, everything in Python is an object, so this shows that OOP is not just supported by Python, but it's part of its very core.
The two main players in OOP are objects and classes. Classes are used to create objects (objects are instances of the classes with which they were created), so we could see them as instance factories. When objects are created by a class, they inherit the class attributes and methods. They represent concrete items in the program's domain.
The simplest Python class
I will start with the simplest class you could ever write in Python.
oop/simplest.class.py
class Simplest(): # when empty, the braces are optional pass print(type(Simplest)) # what type is this object? simp = Simplest() # we create an instance of Simplest: simp print(type(simp)) # what type is simp? # is simp an instance of Simplest? print(type(simp) == Simplest) # There's a better way for this
Let's run the preceding code and explain it line by line:
$ python oop/simplest.class.py <class 'type'> <class '__main__.Simplest'> True
The Simplest class I defined only has the pass instruction for its body, which means it doesn't have any custom attributes or methods. I will print its type (__main__ is the name of the scope in which top-level code executes), and I am aware that, in the comment, I wrote object instead of class. It turns out that, as you can see by the result of that print, classes are actually objects. To be precise, they are instances of type. Explaining this concept would lead to a talk about metaclasses and metaprogramming, advanced concepts that require a solid grasp of the fundamentals to be understood and alas this is beyond the scope of this chapter. As usual, I mentioned it to leave a pointer for you, for when you'll be ready to dig deeper.
Let's go back to the example: I used Simplest to create an instance, simp. You can see that the syntax to create an instance is the same we use to call a function.
Then we print what type simp belongs to and we verify that simp is in fact an instance of Simplest. I'll show you a better way of doing this later on in the chapter.
Up to now, it's all very simple. What happens when we write class ClassName(): pass, though? Well, what Python does is create a class object and assign it a name. This is very similar to what happens when we declare a function using def.
Class and object namespaces
After the class object has been created (which usually happens when the module is first imported), it basically represents a namespace. We can call that class to create its instances. Each instance inherits the class attributes and methods and is given its own namespace. We already know that, to walk a namespace, all we need to do is to use the dot (.) operator.
Let's look at another example:
oop/class.namespaces.py
class Person():
species = 'Human'
print(Person.species) # Human
Person.alive = True # Added dynamically!
print(Person.alive) # True
man = Person()
print(man.species) # Human (inherited)
print(man.alive) # True (inherited)
Person.alive = False
print(man.alive) # False (inherited)
man.name = 'Darth'
man.surname = 'Vader'
print(man.name, man.surname) # Darth VaderIn the preceding example, I have defined a class attribute called species. Any variable defined in the body of a class is an attribute that belongs to that class. In the code, I have also defined Person.alive, which is another class attribute. You can see that there is no restriction on accessing that attribute from the class. You can see that man, which is an instance of Person, inherits both of them, and reflects them instantly when they change.
man has also two attributes which belong to its own namespace and therefore are called instance attributes: name and surname.
Note
Class attributes are shared amongst all instances, while instance attributes are not; therefore, you should use class attributes to provide the states and behaviors to be shared by all instances, and use instance attributes for data that belongs just to one specific object.
Attribute shadowing
When you search for an attribute in an object, if it is not found, Python keeps searching in the class that was used to create that object (and keeps searching until it's either found or the end of the inheritance chain is reached). This leads to an interesting shadowing behavior. Let's look at an example:
oop/class.attribute.shadowing.py
class Point():
x = 10
y = 7
p = Point()
print(p.x) # 10 (from class attribute)
print(p.y) # 7 (from class attribute)
p.x = 12 # p gets its own 'x' attribute
print(p.x) # 12 (now found on the instance)
print(Point.x) # 10 (class attribute still the same)
del p.x # we delete instance attribute
print(p.x) # 10 (now search has to go again to find class attr)
p.z = 3 # let's make it a 3D point
print(p.z) # 3
print(Point.z)
# AttributeError: type object 'Point' has no attribute 'z'The preceding code is very interesting. We have defined a class called Point with two class attributes, x and y. When we create an instance, p, you can see that we can print both x and y from p's namespace (p.x and p.y). What happens when we do that is that Python doesn't find any x or y attributes on the instance, and therefore searches the class, and finds them there.
Then we give p its own x attribute by assigning p.x = 12. This behavior may appear a bit weird at first, but if you think about it, it's exactly the same as what happens in a function that declares x = 12 when there is a global x = 10 outside. We know that x = 12 won't affect the global one, and for classes and instances, it is exactly the same.
After assigning p.x = 12, when we print it, the search doesn't need to read the class attributes, because x is found on the instance, therefore we get 12 printed out.
We also print Point.x which refers to x in the class namespace.
And then, we delete x from the namespace of p, which means that, on the next line, when we print it again, Python will go again and search for it in the class, because it won't be found in the instance any more.
The last three lines show you that assigning attributes to an instance doesn't mean that they will be found in the class. Instances get whatever is in the class, but the opposite is not true.
What do you think about putting the x and y coordinates as class attributes? Do you think it was a good idea?
I, me, and myself – using the self variable
From within a class method we can refer to an instance by means of a special argument, called self by convention. self is always the first attribute of an instance method. Let's examine this behavior together with how we can share, not just attributes, but methods with all instances.
oop/class.self.py
class Square():
side = 8
def area(self): # self is a reference to an instance
return self.side ** 2
sq = Square()
print(sq.area()) # 64 (side is found on the class)
print(Square.area(sq)) # 64 (equivalent to sq.area())
sq.side = 10
print(sq.area()) # 100 (side is found on the instance)Note how the area method is used by sq. The two calls, Square.area(sq) and sq.area(), are equivalent, and teach us how the mechanism works. Either you pass the instance to the method call (Square.area(sq)), which within the method will be called self, or you can use a more comfortable syntax: sq.area() and Python will translate that for you behind the curtains.
Let's look at a better example:
oop/class.price.py
class Price():
def final_price(self, vat, discount=0):
"""Returns price after applying vat and fixed discount."""
return (self.net_price * (100 + vat) / 100) - discount
p1 = Price()
p1.net_price = 100
print(Price.final_price(p1, 20, 10)) # 110 (100 * 1.2 - 10)
print(p1.final_price(20, 10)) # equivalentThe preceding code shows you that nothing prevents us from using arguments when declaring methods. We can use the exact same syntax as we used with the function, but we need to remember that the first argument will always be the instance.
Initializing an instance
Have you noticed how, before calling p1.final_price(...), we had to assign net_price to p1? There is a better way to do it. In other languages, this would be called a constructor, but in Python, it's not. It is actually an initializer, since it works on an already created instance, and therefore it's called __init__. It's a magic method, which is run right after the object is created. Python objects also have a __new__ method, which is the actual constructor. In practice, it's not so common to have to override it though, it's a practice that is mostly used when coding metaclasses, which is a fairly advanced topic that we won't explore in the book.
oop/class.init.py
class Rectangle():
def __init__(self, sideA, sideB):
self.sideA = sideA
self.sideB = sideB
def area(self):
return self.sideA * self.sideB
r1 = Rectangle(10, 4)
print(r1.sideA, r1.sideB) # 10 4
print(r1.area()) # 40
r2 = Rectangle(7, 3)
print(r2.area()) # 21Things are finally starting to take shape. When an object is created, the __init__ method is automatically run for us. In this case, I coded it so that when we create an object (by calling the class name like a function), we pass arguments to the creation call, like we would on any regular function call. The way we pass parameters follows the signature of the __init__ method, and therefore, in the two creation statements, 10 and 7 will be sideA for r1 and r2 respectively, while 4 and 3 will be sideB. You can see that the call to area() from r1 and r2 reflects that they have different instance arguments.
Setting up objects in this way is much nicer and convenient.
OOP is about code reuse
By now it should be pretty clear: OOP is all about code reuse. We define a class, we create instances, and those instances use methods that are defined only in the class. They will behave differently according to how the instances have been set up by the initializer.
Inheritance and composition
But this is just half of the story, OOP is much more powerful. We have two main design constructs to exploit: inheritance and composition.
Inheritance means that two objects are related by means of an Is-A type of relationship. On the other hand, composition means that two objects are related by means of a Has-A type of relationship. It's all very easy to explain with an example:
oop/class.inheritance.py
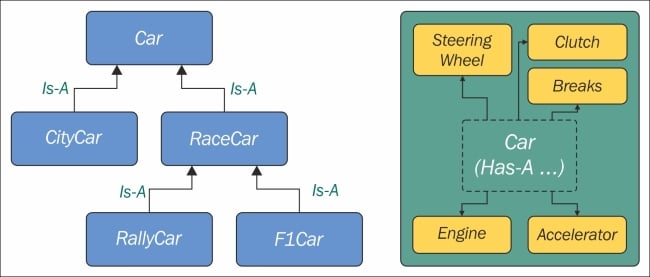
class Engine(): def start(self): pass def stop(self): pass class ElectricEngine(Engine): # Is-A Engine pass class V8Engine(Engine): # Is-A Engine pass class Car(): engine_cls = Engine def __init__(self): self.engine = self.engine_cls() # Has-A Engine def start(self): print( 'Starting engine {0} for car {1}... Wroom, wroom!' .format( self.engine.__class__.__name__, self.__class__.__name__) ) self.engine.start() def stop(self): self.engine.stop() class RaceCar(Car): # Is-A Car engine_cls = V8Engine class CityCar(Car): # Is-A Car engine_cls = ElectricEngine class F1Car(RaceCar): # Is-A RaceCar and also Is-A Car engine_cls = V8Engine car = Car() racecar = RaceCar() citycar = CityCar() f1car = F1Car() cars = [car, racecar, citycar, f1car] for car in cars: car.start() """ Prints: Starting engine Engine for car Car... Wroom, wroom! Starting engine V8Engine for car RaceCar... Wroom, wroom! Starting engine ElectricEngine for car CityCar... Wroom, wroom! Starting engine V8Engine for car F1Car... Wroom, wroom! """
The preceding example shows you both the Is-A and Has-A types of relationships between objects. First of all, let's consider Engine. It's a simple class that has two methods, start and stop. We then define ElectricEngine and V8Engine, which both inherit from Engine. You can see that by the fact that when we define them, we put Engine within the braces after the class name.
This means that both ElectricEngine and V8Engine inherit attributes and methods from the Engine class, which is said to be their base class.
The same happens with cars. Car is a base class for both RaceCar and CityCar. RaceCar is also the base class for F1Car. Another way of saying this is that F1Car inherits from RaceCar, which inherits from Car. Therefore, F1Car Is-A RaceCar and RaceCar Is-A Car. Because of the transitive property, we can say that F1Car Is-A Car as well. CityCar too, Is-A Car.
When we define class A(B): pass, we say A is the child of B, and B is the parent of A. parent and base are synonyms, as well as child and derived. Also, we say that a class inherits from another class, or that it extends it.
This is the inheritance mechanism.
On the other hand, let's go back to the code. Each class has a class attribute, engine_cls, which is a reference to the engine class we want to assign to each type of car. Car has a generic Engine, while the two race cars have a powerful V8 engine, and the city car has an electric one.
When a car is created in the initializer method __init__, we create an instance of whatever engine class is assigned to the car, and set it as engine instance attribute.
It makes sense to have engine_cls shared amongst all class instances because it's quite likely that the same instances of a car will have the same kind of engine. On the other hand, it wouldn't be good to have one single engine (an instance of any Engine class) as a class attribute, because we would be sharing one engine amongst all instances, which is incorrect.
The type of relationship between a car and its engine is a Has-A type. A car Has-A engine. This is called composition, and reflects the fact that objects can be made of many other objects. A car Has-A engine, gears, wheels, a frame, doors, seats, and so on.
When designing OOP code, it is of vital importance to describe objects in this way so that we can use inheritance and composition correctly to structure our code in the best way.
Before we leave this paragraph, let's check if I told you the truth with another example:
oop/class.issubclass.isinstance.py
car = Car()
racecar = RaceCar()
f1car = F1Car()
cars = [(car, 'car'), (racecar, 'racecar'), (f1car, 'f1car')]
car_classes = [Car, RaceCar, F1Car]
for car, car_name in cars:
for class_ in car_classes:
belongs = isinstance(car, class_)
msg = 'is a' if belongs else 'is not a'
print(car_name, msg, class_.__name__)
""" Prints:
car is a Car
car is not a RaceCar
car is not a F1Car
racecar is a Car
racecar is a RaceCar
racecar is not a F1Car
f1car is a Car
f1car is a RaceCar
f1car is a F1Car
"""As you can see, car is just an instance of Car, while racecar is an instance of RaceCar (and of Car by extension) and f1car is an instance of F1Car (and of both RaceCar and Car, by extension). A banana is an instance of Banana. But, also, it is a Fruit. Also, it is Food, right? This is the same concept.
To check if an object is an instance of a class, use the isinstance method. It is recommended over sheer type comparison (type(object) == Class).
Let's also check inheritance, same setup, with different for loops:
oop/class.issubclass.isinstance.py
for class1 in car_classes:
for class2 in car_classes:
is_subclass = issubclass(class1, class2)
msg = '{0} a subclass of'.format(
'is' if is_subclass else 'is not')
print(class1.__name__, msg, class2.__name__)
""" Prints:
Car is a subclass of Car
Car is not a subclass of RaceCar
Car is not a subclass of F1Car
RaceCar is a subclass of Car
RaceCar is a subclass of RaceCar
RaceCar is not a subclass of F1Car
F1Car is a subclass of Car
F1Car is a subclass of RaceCar
F1Car is a subclass of F1Car
"""Interestingly, we learn that a class is a subclass of itself. Check the output of the preceding example to see that it matches the explanation I provided.
Note
One thing to notice about conventions is that class names are always written using CapWords, which means ThisWayIsCorrect, as opposed to functions and methods, which are written this_way_is_correct. Also, when in the code you want to use a name which is a Python-reserved keyword or built-in function or class, the convention is to add a trailing underscore to the name. In the first for loop example, I'm looping through the class names using for class_ in ..., because class is a reserved word. But you already knew all this because you have thoroughly studied PEP8, right?
To help you picture the difference between Is-A and Has-A, take a look at the following diagram:
Accessing a base class
We've already seen class declarations like class ClassA: pass and class ClassB(BaseClassName): pass. When we don't specify a base class explicitly, Python will set the special object class as the base class for the one we're defining. Ultimately, all classes derive from object. Note that, if you don't specify a base class, braces are optional.
Therefore, writing class A: pass or class A(): pass or class A(object): pass is exactly the same thing. object is a special class in that it has the methods that are common to all Python classes, and it doesn't allow you to set any attributes on it.
Let's see how we can access a base class from within a class.
oop/super.duplication.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
self.title = title
self.publisher = publisher
self.pages = pages
self.format_ = format_Take a look at the preceding code. I highlighted the part of Ebook initialization that is duplicated from its base class Book. This is quite bad practice because we now have two sets of instructions that are doing the same thing. Moreover, any change in the signature of Book.__init__ will not reflect in Ebook. We know that Ebook Is-A Book, and therefore we would probably want changes to be reflected in the children classes.
Let's see one way to fix this issue:
oop/super.explicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
Book.__init__(self, title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFNow, that's better. We have removed that nasty duplication. Basically, we tell Python to call the __init__ method of the Book class, and we feed self to the call, making sure that we bind that call to the present instance.
If we modify the logic within the __init__ method of Book, we don't need to touch Ebook, it will auto adapt to the change.
This approach is good, but we can still do a bit better. Say that we change Book's name to Liber, because we've fallen in love with Latin. We have to change the __init__ method of Ebook to reflect the change. This can be avoided by using super.
oop/super.implicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
super().__init__(title, publisher, pages)
# Another way to do the same thing is:
# super(Ebook, self).__init__(title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFsuper is a function that returns a proxy object that delegates method calls to a parent or sibling class. In this case, it will delegate that call to __init__ to the Book class, and the beauty of this method is that now we're even free to change Book to Liber without having to touch the logic in the __init__ method of Ebook.
Now that we know how to access a base class from a child, let's explore Python's multiple inheritance.
Multiple inheritance
Apart from composing a class using more than one base class, what is of interest here is how an attribute search is performed. Take a look at the following diagram:
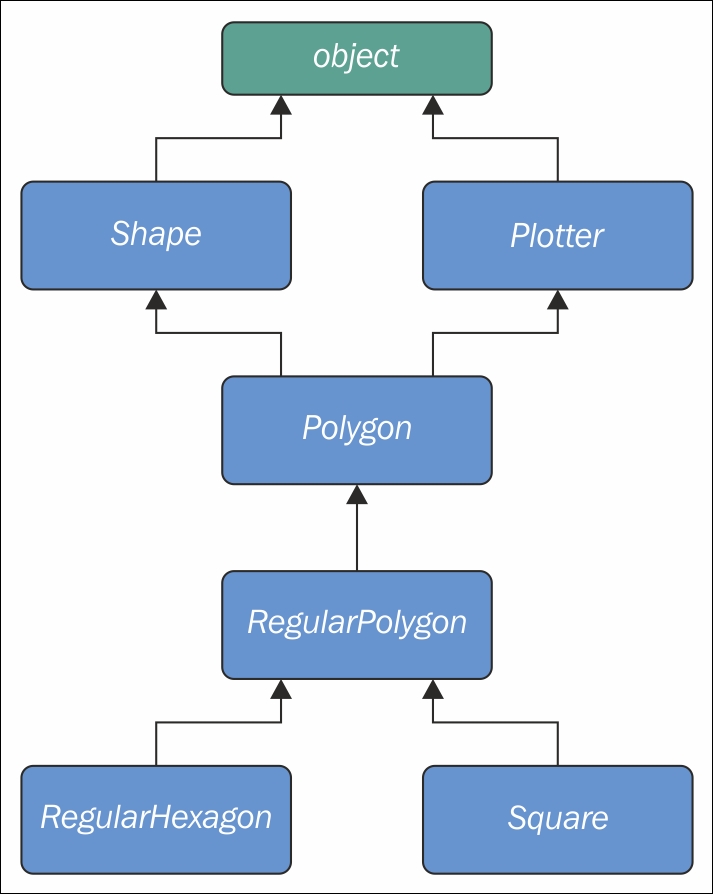
As you can see, Shape and Plotter act as base classes for all the others. Polygon inherits directly from them, RegularPolygon inherits from Polygon, and both RegularHexagon and Square inherit from RegulaPolygon. Note also that Shape and Plotter implicitly inherit from object, therefore we have what is called a diamond or, in simpler terms, more than one path to reach a base class. We'll see why this matters in a few moments. Let's translate it into some simple code:
oop/multiple.inheritance.py
class Shape: geometric_type = 'Generic Shape' def area(self): # This acts as placeholder for the interface raise NotImplementedError def get_geometric_type(self): return self.geometric_type class Plotter: def plot(self, ratio, topleft): # Imagine some nice plotting logic here... print('Plotting at {}, ratio {}.'.format( topleft, ratio)) class Polygon(Shape, Plotter): # base class for polygons geometric_type = 'Polygon' class RegularPolygon(Polygon): # Is-A Polygon geometric_type = 'Regular Polygon' def __init__(self, side): self.side = side class RegularHexagon(RegularPolygon): # Is-A RegularPolygon geometric_type = 'RegularHexagon' def area(self): return 1.5 * (3 ** .5 * self.side ** 2) class Square(RegularPolygon): # Is-A RegularPolygon geometric_type = 'Square' def area(self): return self.side * self.side hexagon = RegularHexagon(10) print(hexagon.area()) # 259.8076211353316 print(hexagon.get_geometric_type()) # RegularHexagon hexagon.plot(0.8, (75, 77)) # Plotting at (75, 77), ratio 0.8. square = Square(12) print(square.area()) # 144 print(square.get_geometric_type()) # Square square.plot(0.93, (74, 75)) # Plotting at (74, 75), ratio 0.93.
Take a look at the preceding code: the class Shape has one attribute, geometric_type, and two methods: area and get_geometric_type. It's quite common to use base classes (like Shape, in our example) to define an interface: methods for which children must provide an implementation. There are different and better ways to do this, but I want to keep this example as simple as possible.
We also have the Plotter class, which adds the plot method, thereby providing plotting capabilities for any class that inherits from it. Of course, the plot implementation is just a dummy print in this example. The first interesting class is Polygon, which inherits from both Shape and Plotter.
There are many types of polygons, one of which is the regular one, which is both equiangular (all angles are equal) and equilateral (all sides are equal), so we create the RegularPolygon class that inherits from Polygon. Because for a regular polygon, all sides are equal, we can implement a simple __init__ method on RegularPolygon, which takes the length of the side. Finally, we create the RegularHexagon and Square classes, which both inherit from RegularPolygon.
This structure is quite long, but hopefully gives you an idea of how to specialize the classification of your objects when you design the code.
Now, please take a look at the last eight lines. Note that when I call the area method on hexagon and square, I get the correct area for both. This is because they both provide the correct implementation logic for it. Also, I can call get_geometric_type on both of them, even though it is not defined on their classes, and Python has to go all the way up to Shape to find an implementation for it. Note that, even though the implementation is provided in the Shape class, the self.geometric_type used for the return value is correctly taken from the caller instance.
The plot method calls are also interesting, and show you how you can enrich your objects with capabilities they wouldn't otherwise have. This technique is very popular in web frameworks such as Django (which we'll explore in two later chapters), which provides special classes called mixins, whose capabilities you can just use out of the box. All you have to do is to define the desired mixin as one the base classes for your own, and that's it.
Multiple inheritance is powerful, but can also get really messy, so we need to make sure we understand what happens when we use it.
Method resolution order
By now, we know that when you ask for someobject.attribute, and attribute is not found on that object, Python starts searching in the class someobject was created from. If it's not there either, Python searches up the inheritance chain until either attribute is found or the object class is reached. This is quite simple to understand if the inheritance chain is only comprised of single inheritance steps, which means that classes have only one parent. However, when multiple inheritance is involved, there are cases when it's not straightforward to predict what will be the next class that will be searched for if an attribute is not found.
Python provides a way to always know what is the order in which classes are searched on attribute lookup: the method resolution order.
Note
The method resolution order (MRO) is the order in which base classes are searched for a member during lookup. From version 2.3 Python uses an algorithm called C3, which guarantees monotonicity.
In Python 2.2, new-style classes were introduced. The way you write a new-style class in Python 2.* is to define it with an explicit object base class. Classic classes were not explicitly inheriting from object and have been removed in Python 3.
One of the differences between classic and new style-classes in Python 2.* is that new-style classes are searched with the new MRO.
With regards to the previous example, let's see what is the MRO for the Square class:
oop/multiple.inheritance.py
print(square.__class__.__mro__)
# prints:
# (<class '__main__.Square'>, <class '__main__.RegularPolygon'>,
# <class '__main__.Polygon'>, <class '__main__.Shape'>,
# <class '__main__.Plotter'>, <class 'object'>)To get to the MRO of a class, we can go from the instance to its __class__ attribute and from that to its __mro__ attribute. Alternatively, we could have called Square.__mro__, or Square.mro() directly, but if you have to do it dynamically, it's more likely you will have an object in your hands rather than a class.
Note that the only point of doubt is the bisection after Polygon, where the inheritance chain breaks into two ways, one leads to Shape and the other to Plotter. We know by scanning the MRO for the Square class that Shape is searched before Plotter.
Why is this important? Well, imagine the following code:
oop/mro.simple.py
class A:
label = 'a'
class B(A):
label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # Hypothetically this could be either 'b' or 'c'Both B and C inherit from A, and D inherits from both B and C. This means that the lookup for the label attribute can reach the top (A) through both B or C. According to which is reached first, we get a different result.
So, in the preceding example we get 'b', which is what we were expecting, since B is the leftmost one amongst base classes of D. But what happens if I remove the label attribute from B? This would be the confusing situation: Will the algorithm go all the way up to A or will it get to C first? Let's find out!
oop/mro.py
class A:
label = 'a'
class B(A):
pass # was: label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # 'c'
print(d.__class__.mro()) # notice another way to get the MRO
# prints:
# [<class '__main__.D'>, <class '__main__.B'>,
# <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]So, we learn that the MRO is D-B-C-A-(object), which means when we ask for d.label, we get 'c', which is correct.
In day to day programming, it is not quite common to have to deal with the MRO, but the first time you fight against some mixin from a framework, I promise you'll be glad I spent a paragraph explaining it.
Static and class methods
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
Private methods and name mangling
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
The simplest Python class
I will start with the simplest class you could ever write in Python.
oop/simplest.class.py
class Simplest(): # when empty, the braces are optional pass print(type(Simplest)) # what type is this object? simp = Simplest() # we create an instance of Simplest: simp print(type(simp)) # what type is simp? # is simp an instance of Simplest? print(type(simp) == Simplest) # There's a better way for this
Let's run the preceding code and explain it line by line:
$ python oop/simplest.class.py <class 'type'> <class '__main__.Simplest'> True
The Simplest class I defined only has the pass instruction for its body, which means it doesn't have any custom attributes or methods. I will print its type (__main__ is the name of the scope in which top-level code executes), and I am aware that, in the comment, I wrote object instead of class. It turns out that, as you can see by the result of that print, classes are actually objects. To be precise, they are instances of type. Explaining this concept would lead to a talk about metaclasses and metaprogramming, advanced concepts that require a solid grasp of the fundamentals to be understood and alas this is beyond the scope of this chapter. As usual, I mentioned it to leave a pointer for you, for when you'll be ready to dig deeper.
Let's go back to the example: I used Simplest to create an instance, simp. You can see that the syntax to create an instance is the same we use to call a function.
Then we print what type simp belongs to and we verify that simp is in fact an instance of Simplest. I'll show you a better way of doing this later on in the chapter.
Up to now, it's all very simple. What happens when we write class ClassName(): pass, though? Well, what Python does is create a class object and assign it a name. This is very similar to what happens when we declare a function using def.
Class and object namespaces
After the class object has been created (which usually happens when the module is first imported), it basically represents a namespace. We can call that class to create its instances. Each instance inherits the class attributes and methods and is given its own namespace. We already know that, to walk a namespace, all we need to do is to use the dot (.) operator.
Let's look at another example:
oop/class.namespaces.py
class Person():
species = 'Human'
print(Person.species) # Human
Person.alive = True # Added dynamically!
print(Person.alive) # True
man = Person()
print(man.species) # Human (inherited)
print(man.alive) # True (inherited)
Person.alive = False
print(man.alive) # False (inherited)
man.name = 'Darth'
man.surname = 'Vader'
print(man.name, man.surname) # Darth VaderIn the preceding example, I have defined a class attribute called species. Any variable defined in the body of a class is an attribute that belongs to that class. In the code, I have also defined Person.alive, which is another class attribute. You can see that there is no restriction on accessing that attribute from the class. You can see that man, which is an instance of Person, inherits both of them, and reflects them instantly when they change.
man has also two attributes which belong to its own namespace and therefore are called instance attributes: name and surname.
Note
Class attributes are shared amongst all instances, while instance attributes are not; therefore, you should use class attributes to provide the states and behaviors to be shared by all instances, and use instance attributes for data that belongs just to one specific object.
Attribute shadowing
When you search for an attribute in an object, if it is not found, Python keeps searching in the class that was used to create that object (and keeps searching until it's either found or the end of the inheritance chain is reached). This leads to an interesting shadowing behavior. Let's look at an example:
oop/class.attribute.shadowing.py
class Point():
x = 10
y = 7
p = Point()
print(p.x) # 10 (from class attribute)
print(p.y) # 7 (from class attribute)
p.x = 12 # p gets its own 'x' attribute
print(p.x) # 12 (now found on the instance)
print(Point.x) # 10 (class attribute still the same)
del p.x # we delete instance attribute
print(p.x) # 10 (now search has to go again to find class attr)
p.z = 3 # let's make it a 3D point
print(p.z) # 3
print(Point.z)
# AttributeError: type object 'Point' has no attribute 'z'The preceding code is very interesting. We have defined a class called Point with two class attributes, x and y. When we create an instance, p, you can see that we can print both x and y from p's namespace (p.x and p.y). What happens when we do that is that Python doesn't find any x or y attributes on the instance, and therefore searches the class, and finds them there.
Then we give p its own x attribute by assigning p.x = 12. This behavior may appear a bit weird at first, but if you think about it, it's exactly the same as what happens in a function that declares x = 12 when there is a global x = 10 outside. We know that x = 12 won't affect the global one, and for classes and instances, it is exactly the same.
After assigning p.x = 12, when we print it, the search doesn't need to read the class attributes, because x is found on the instance, therefore we get 12 printed out.
We also print Point.x which refers to x in the class namespace.
And then, we delete x from the namespace of p, which means that, on the next line, when we print it again, Python will go again and search for it in the class, because it won't be found in the instance any more.
The last three lines show you that assigning attributes to an instance doesn't mean that they will be found in the class. Instances get whatever is in the class, but the opposite is not true.
What do you think about putting the x and y coordinates as class attributes? Do you think it was a good idea?
I, me, and myself – using the self variable
From within a class method we can refer to an instance by means of a special argument, called self by convention. self is always the first attribute of an instance method. Let's examine this behavior together with how we can share, not just attributes, but methods with all instances.
oop/class.self.py
class Square():
side = 8
def area(self): # self is a reference to an instance
return self.side ** 2
sq = Square()
print(sq.area()) # 64 (side is found on the class)
print(Square.area(sq)) # 64 (equivalent to sq.area())
sq.side = 10
print(sq.area()) # 100 (side is found on the instance)Note how the area method is used by sq. The two calls, Square.area(sq) and sq.area(), are equivalent, and teach us how the mechanism works. Either you pass the instance to the method call (Square.area(sq)), which within the method will be called self, or you can use a more comfortable syntax: sq.area() and Python will translate that for you behind the curtains.
Let's look at a better example:
oop/class.price.py
class Price():
def final_price(self, vat, discount=0):
"""Returns price after applying vat and fixed discount."""
return (self.net_price * (100 + vat) / 100) - discount
p1 = Price()
p1.net_price = 100
print(Price.final_price(p1, 20, 10)) # 110 (100 * 1.2 - 10)
print(p1.final_price(20, 10)) # equivalentThe preceding code shows you that nothing prevents us from using arguments when declaring methods. We can use the exact same syntax as we used with the function, but we need to remember that the first argument will always be the instance.
Initializing an instance
Have you noticed how, before calling p1.final_price(...), we had to assign net_price to p1? There is a better way to do it. In other languages, this would be called a constructor, but in Python, it's not. It is actually an initializer, since it works on an already created instance, and therefore it's called __init__. It's a magic method, which is run right after the object is created. Python objects also have a __new__ method, which is the actual constructor. In practice, it's not so common to have to override it though, it's a practice that is mostly used when coding metaclasses, which is a fairly advanced topic that we won't explore in the book.
oop/class.init.py
class Rectangle():
def __init__(self, sideA, sideB):
self.sideA = sideA
self.sideB = sideB
def area(self):
return self.sideA * self.sideB
r1 = Rectangle(10, 4)
print(r1.sideA, r1.sideB) # 10 4
print(r1.area()) # 40
r2 = Rectangle(7, 3)
print(r2.area()) # 21Things are finally starting to take shape. When an object is created, the __init__ method is automatically run for us. In this case, I coded it so that when we create an object (by calling the class name like a function), we pass arguments to the creation call, like we would on any regular function call. The way we pass parameters follows the signature of the __init__ method, and therefore, in the two creation statements, 10 and 7 will be sideA for r1 and r2 respectively, while 4 and 3 will be sideB. You can see that the call to area() from r1 and r2 reflects that they have different instance arguments.
Setting up objects in this way is much nicer and convenient.
OOP is about code reuse
By now it should be pretty clear: OOP is all about code reuse. We define a class, we create instances, and those instances use methods that are defined only in the class. They will behave differently according to how the instances have been set up by the initializer.
Inheritance and composition
But this is just half of the story, OOP is much more powerful. We have two main design constructs to exploit: inheritance and composition.
Inheritance means that two objects are related by means of an Is-A type of relationship. On the other hand, composition means that two objects are related by means of a Has-A type of relationship. It's all very easy to explain with an example:
oop/class.inheritance.py
class Engine(): def start(self): pass def stop(self): pass class ElectricEngine(Engine): # Is-A Engine pass class V8Engine(Engine): # Is-A Engine pass class Car(): engine_cls = Engine def __init__(self): self.engine = self.engine_cls() # Has-A Engine def start(self): print( 'Starting engine {0} for car {1}... Wroom, wroom!' .format( self.engine.__class__.__name__, self.__class__.__name__) ) self.engine.start() def stop(self): self.engine.stop() class RaceCar(Car): # Is-A Car engine_cls = V8Engine class CityCar(Car): # Is-A Car engine_cls = ElectricEngine class F1Car(RaceCar): # Is-A RaceCar and also Is-A Car engine_cls = V8Engine car = Car() racecar = RaceCar() citycar = CityCar() f1car = F1Car() cars = [car, racecar, citycar, f1car] for car in cars: car.start() """ Prints: Starting engine Engine for car Car... Wroom, wroom! Starting engine V8Engine for car RaceCar... Wroom, wroom! Starting engine ElectricEngine for car CityCar... Wroom, wroom! Starting engine V8Engine for car F1Car... Wroom, wroom! """
The preceding example shows you both the Is-A and Has-A types of relationships between objects. First of all, let's consider Engine. It's a simple class that has two methods, start and stop. We then define ElectricEngine and V8Engine, which both inherit from Engine. You can see that by the fact that when we define them, we put Engine within the braces after the class name.
This means that both ElectricEngine and V8Engine inherit attributes and methods from the Engine class, which is said to be their base class.
The same happens with cars. Car is a base class for both RaceCar and CityCar. RaceCar is also the base class for F1Car. Another way of saying this is that F1Car inherits from RaceCar, which inherits from Car. Therefore, F1Car Is-A RaceCar and RaceCar Is-A Car. Because of the transitive property, we can say that F1Car Is-A Car as well. CityCar too, Is-A Car.
When we define class A(B): pass, we say A is the child of B, and B is the parent of A. parent and base are synonyms, as well as child and derived. Also, we say that a class inherits from another class, or that it extends it.
This is the inheritance mechanism.
On the other hand, let's go back to the code. Each class has a class attribute, engine_cls, which is a reference to the engine class we want to assign to each type of car. Car has a generic Engine, while the two race cars have a powerful V8 engine, and the city car has an electric one.
When a car is created in the initializer method __init__, we create an instance of whatever engine class is assigned to the car, and set it as engine instance attribute.
It makes sense to have engine_cls shared amongst all class instances because it's quite likely that the same instances of a car will have the same kind of engine. On the other hand, it wouldn't be good to have one single engine (an instance of any Engine class) as a class attribute, because we would be sharing one engine amongst all instances, which is incorrect.
The type of relationship between a car and its engine is a Has-A type. A car Has-A engine. This is called composition, and reflects the fact that objects can be made of many other objects. A car Has-A engine, gears, wheels, a frame, doors, seats, and so on.
When designing OOP code, it is of vital importance to describe objects in this way so that we can use inheritance and composition correctly to structure our code in the best way.
Before we leave this paragraph, let's check if I told you the truth with another example:
oop/class.issubclass.isinstance.py
car = Car()
racecar = RaceCar()
f1car = F1Car()
cars = [(car, 'car'), (racecar, 'racecar'), (f1car, 'f1car')]
car_classes = [Car, RaceCar, F1Car]
for car, car_name in cars:
for class_ in car_classes:
belongs = isinstance(car, class_)
msg = 'is a' if belongs else 'is not a'
print(car_name, msg, class_.__name__)
""" Prints:
car is a Car
car is not a RaceCar
car is not a F1Car
racecar is a Car
racecar is a RaceCar
racecar is not a F1Car
f1car is a Car
f1car is a RaceCar
f1car is a F1Car
"""As you can see, car is just an instance of Car, while racecar is an instance of RaceCar (and of Car by extension) and f1car is an instance of F1Car (and of both RaceCar and Car, by extension). A banana is an instance of Banana. But, also, it is a Fruit. Also, it is Food, right? This is the same concept.
To check if an object is an instance of a class, use the isinstance method. It is recommended over sheer type comparison (type(object) == Class).
Let's also check inheritance, same setup, with different for loops:
oop/class.issubclass.isinstance.py
for class1 in car_classes:
for class2 in car_classes:
is_subclass = issubclass(class1, class2)
msg = '{0} a subclass of'.format(
'is' if is_subclass else 'is not')
print(class1.__name__, msg, class2.__name__)
""" Prints:
Car is a subclass of Car
Car is not a subclass of RaceCar
Car is not a subclass of F1Car
RaceCar is a subclass of Car
RaceCar is a subclass of RaceCar
RaceCar is not a subclass of F1Car
F1Car is a subclass of Car
F1Car is a subclass of RaceCar
F1Car is a subclass of F1Car
"""Interestingly, we learn that a class is a subclass of itself. Check the output of the preceding example to see that it matches the explanation I provided.
Note
One thing to notice about conventions is that class names are always written using CapWords, which means ThisWayIsCorrect, as opposed to functions and methods, which are written this_way_is_correct. Also, when in the code you want to use a name which is a Python-reserved keyword or built-in function or class, the convention is to add a trailing underscore to the name. In the first for loop example, I'm looping through the class names using for class_ in ..., because class is a reserved word. But you already knew all this because you have thoroughly studied PEP8, right?
To help you picture the difference between Is-A and Has-A, take a look at the following diagram:
Accessing a base class
We've already seen class declarations like class ClassA: pass and class ClassB(BaseClassName): pass. When we don't specify a base class explicitly, Python will set the special object class as the base class for the one we're defining. Ultimately, all classes derive from object. Note that, if you don't specify a base class, braces are optional.
Therefore, writing class A: pass or class A(): pass or class A(object): pass is exactly the same thing. object is a special class in that it has the methods that are common to all Python classes, and it doesn't allow you to set any attributes on it.
Let's see how we can access a base class from within a class.
oop/super.duplication.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
self.title = title
self.publisher = publisher
self.pages = pages
self.format_ = format_Take a look at the preceding code. I highlighted the part of Ebook initialization that is duplicated from its base class Book. This is quite bad practice because we now have two sets of instructions that are doing the same thing. Moreover, any change in the signature of Book.__init__ will not reflect in Ebook. We know that Ebook Is-A Book, and therefore we would probably want changes to be reflected in the children classes.
Let's see one way to fix this issue:
oop/super.explicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
Book.__init__(self, title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFNow, that's better. We have removed that nasty duplication. Basically, we tell Python to call the __init__ method of the Book class, and we feed self to the call, making sure that we bind that call to the present instance.
If we modify the logic within the __init__ method of Book, we don't need to touch Ebook, it will auto adapt to the change.
This approach is good, but we can still do a bit better. Say that we change Book's name to Liber, because we've fallen in love with Latin. We have to change the __init__ method of Ebook to reflect the change. This can be avoided by using super.
oop/super.implicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
super().__init__(title, publisher, pages)
# Another way to do the same thing is:
# super(Ebook, self).__init__(title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFsuper is a function that returns a proxy object that delegates method calls to a parent or sibling class. In this case, it will delegate that call to __init__ to the Book class, and the beauty of this method is that now we're even free to change Book to Liber without having to touch the logic in the __init__ method of Ebook.
Now that we know how to access a base class from a child, let's explore Python's multiple inheritance.
Multiple inheritance
Apart from composing a class using more than one base class, what is of interest here is how an attribute search is performed. Take a look at the following diagram:
As you can see, Shape and Plotter act as base classes for all the others. Polygon inherits directly from them, RegularPolygon inherits from Polygon, and both RegularHexagon and Square inherit from RegulaPolygon. Note also that Shape and Plotter implicitly inherit from object, therefore we have what is called a diamond or, in simpler terms, more than one path to reach a base class. We'll see why this matters in a few moments. Let's translate it into some simple code:
oop/multiple.inheritance.py
class Shape: geometric_type = 'Generic Shape' def area(self): # This acts as placeholder for the interface raise NotImplementedError def get_geometric_type(self): return self.geometric_type class Plotter: def plot(self, ratio, topleft): # Imagine some nice plotting logic here... print('Plotting at {}, ratio {}.'.format( topleft, ratio)) class Polygon(Shape, Plotter): # base class for polygons geometric_type = 'Polygon' class RegularPolygon(Polygon): # Is-A Polygon geometric_type = 'Regular Polygon' def __init__(self, side): self.side = side class RegularHexagon(RegularPolygon): # Is-A RegularPolygon geometric_type = 'RegularHexagon' def area(self): return 1.5 * (3 ** .5 * self.side ** 2) class Square(RegularPolygon): # Is-A RegularPolygon geometric_type = 'Square' def area(self): return self.side * self.side hexagon = RegularHexagon(10) print(hexagon.area()) # 259.8076211353316 print(hexagon.get_geometric_type()) # RegularHexagon hexagon.plot(0.8, (75, 77)) # Plotting at (75, 77), ratio 0.8. square = Square(12) print(square.area()) # 144 print(square.get_geometric_type()) # Square square.plot(0.93, (74, 75)) # Plotting at (74, 75), ratio 0.93.
Take a look at the preceding code: the class Shape has one attribute, geometric_type, and two methods: area and get_geometric_type. It's quite common to use base classes (like Shape, in our example) to define an interface: methods for which children must provide an implementation. There are different and better ways to do this, but I want to keep this example as simple as possible.
We also have the Plotter class, which adds the plot method, thereby providing plotting capabilities for any class that inherits from it. Of course, the plot implementation is just a dummy print in this example. The first interesting class is Polygon, which inherits from both Shape and Plotter.
There are many types of polygons, one of which is the regular one, which is both equiangular (all angles are equal) and equilateral (all sides are equal), so we create the RegularPolygon class that inherits from Polygon. Because for a regular polygon, all sides are equal, we can implement a simple __init__ method on RegularPolygon, which takes the length of the side. Finally, we create the RegularHexagon and Square classes, which both inherit from RegularPolygon.
This structure is quite long, but hopefully gives you an idea of how to specialize the classification of your objects when you design the code.
Now, please take a look at the last eight lines. Note that when I call the area method on hexagon and square, I get the correct area for both. This is because they both provide the correct implementation logic for it. Also, I can call get_geometric_type on both of them, even though it is not defined on their classes, and Python has to go all the way up to Shape to find an implementation for it. Note that, even though the implementation is provided in the Shape class, the self.geometric_type used for the return value is correctly taken from the caller instance.
The plot method calls are also interesting, and show you how you can enrich your objects with capabilities they wouldn't otherwise have. This technique is very popular in web frameworks such as Django (which we'll explore in two later chapters), which provides special classes called mixins, whose capabilities you can just use out of the box. All you have to do is to define the desired mixin as one the base classes for your own, and that's it.
Multiple inheritance is powerful, but can also get really messy, so we need to make sure we understand what happens when we use it.
Method resolution order
By now, we know that when you ask for someobject.attribute, and attribute is not found on that object, Python starts searching in the class someobject was created from. If it's not there either, Python searches up the inheritance chain until either attribute is found or the object class is reached. This is quite simple to understand if the inheritance chain is only comprised of single inheritance steps, which means that classes have only one parent. However, when multiple inheritance is involved, there are cases when it's not straightforward to predict what will be the next class that will be searched for if an attribute is not found.
Python provides a way to always know what is the order in which classes are searched on attribute lookup: the method resolution order.
Note
The method resolution order (MRO) is the order in which base classes are searched for a member during lookup. From version 2.3 Python uses an algorithm called C3, which guarantees monotonicity.
In Python 2.2, new-style classes were introduced. The way you write a new-style class in Python 2.* is to define it with an explicit object base class. Classic classes were not explicitly inheriting from object and have been removed in Python 3.
One of the differences between classic and new style-classes in Python 2.* is that new-style classes are searched with the new MRO.
With regards to the previous example, let's see what is the MRO for the Square class:
oop/multiple.inheritance.py
print(square.__class__.__mro__)
# prints:
# (<class '__main__.Square'>, <class '__main__.RegularPolygon'>,
# <class '__main__.Polygon'>, <class '__main__.Shape'>,
# <class '__main__.Plotter'>, <class 'object'>)To get to the MRO of a class, we can go from the instance to its __class__ attribute and from that to its __mro__ attribute. Alternatively, we could have called Square.__mro__, or Square.mro() directly, but if you have to do it dynamically, it's more likely you will have an object in your hands rather than a class.
Note that the only point of doubt is the bisection after Polygon, where the inheritance chain breaks into two ways, one leads to Shape and the other to Plotter. We know by scanning the MRO for the Square class that Shape is searched before Plotter.
Why is this important? Well, imagine the following code:
oop/mro.simple.py
class A:
label = 'a'
class B(A):
label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # Hypothetically this could be either 'b' or 'c'Both B and C inherit from A, and D inherits from both B and C. This means that the lookup for the label attribute can reach the top (A) through both B or C. According to which is reached first, we get a different result.
So, in the preceding example we get 'b', which is what we were expecting, since B is the leftmost one amongst base classes of D. But what happens if I remove the label attribute from B? This would be the confusing situation: Will the algorithm go all the way up to A or will it get to C first? Let's find out!
oop/mro.py
class A:
label = 'a'
class B(A):
pass # was: label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # 'c'
print(d.__class__.mro()) # notice another way to get the MRO
# prints:
# [<class '__main__.D'>, <class '__main__.B'>,
# <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]So, we learn that the MRO is D-B-C-A-(object), which means when we ask for d.label, we get 'c', which is correct.
In day to day programming, it is not quite common to have to deal with the MRO, but the first time you fight against some mixin from a framework, I promise you'll be glad I spent a paragraph explaining it.
Static and class methods
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
Private methods and name mangling
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Class and object namespaces
After the class object has been created (which usually happens when the module is first imported), it basically represents a namespace. We can call that class to create its instances. Each instance inherits the class attributes and methods and is given its own namespace. We already know that, to walk a namespace, all we need to do is to use the dot (.) operator.
Let's look at another example:
oop/class.namespaces.py
class Person():
species = 'Human'
print(Person.species) # Human
Person.alive = True # Added dynamically!
print(Person.alive) # True
man = Person()
print(man.species) # Human (inherited)
print(man.alive) # True (inherited)
Person.alive = False
print(man.alive) # False (inherited)
man.name = 'Darth'
man.surname = 'Vader'
print(man.name, man.surname) # Darth VaderIn the preceding example, I have defined a class attribute called species. Any variable defined in the body of a class is an attribute that belongs to that class. In the code, I have also defined Person.alive, which is another class attribute. You can see that there is no restriction on accessing that attribute from the class. You can see that man, which is an instance of Person, inherits both of them, and reflects them instantly when they change.
man has also two attributes which belong to its own namespace and therefore are called instance attributes: name and surname.
Note
Class attributes are shared amongst all instances, while instance attributes are not; therefore, you should use class attributes to provide the states and behaviors to be shared by all instances, and use instance attributes for data that belongs just to one specific object.
Attribute shadowing
When you search for an attribute in an object, if it is not found, Python keeps searching in the class that was used to create that object (and keeps searching until it's either found or the end of the inheritance chain is reached). This leads to an interesting shadowing behavior. Let's look at an example:
oop/class.attribute.shadowing.py
class Point():
x = 10
y = 7
p = Point()
print(p.x) # 10 (from class attribute)
print(p.y) # 7 (from class attribute)
p.x = 12 # p gets its own 'x' attribute
print(p.x) # 12 (now found on the instance)
print(Point.x) # 10 (class attribute still the same)
del p.x # we delete instance attribute
print(p.x) # 10 (now search has to go again to find class attr)
p.z = 3 # let's make it a 3D point
print(p.z) # 3
print(Point.z)
# AttributeError: type object 'Point' has no attribute 'z'The preceding code is very interesting. We have defined a class called Point with two class attributes, x and y. When we create an instance, p, you can see that we can print both x and y from p's namespace (p.x and p.y). What happens when we do that is that Python doesn't find any x or y attributes on the instance, and therefore searches the class, and finds them there.
Then we give p its own x attribute by assigning p.x = 12. This behavior may appear a bit weird at first, but if you think about it, it's exactly the same as what happens in a function that declares x = 12 when there is a global x = 10 outside. We know that x = 12 won't affect the global one, and for classes and instances, it is exactly the same.
After assigning p.x = 12, when we print it, the search doesn't need to read the class attributes, because x is found on the instance, therefore we get 12 printed out.
We also print Point.x which refers to x in the class namespace.
And then, we delete x from the namespace of p, which means that, on the next line, when we print it again, Python will go again and search for it in the class, because it won't be found in the instance any more.
The last three lines show you that assigning attributes to an instance doesn't mean that they will be found in the class. Instances get whatever is in the class, but the opposite is not true.
What do you think about putting the x and y coordinates as class attributes? Do you think it was a good idea?
I, me, and myself – using the self variable
From within a class method we can refer to an instance by means of a special argument, called self by convention. self is always the first attribute of an instance method. Let's examine this behavior together with how we can share, not just attributes, but methods with all instances.
oop/class.self.py
class Square():
side = 8
def area(self): # self is a reference to an instance
return self.side ** 2
sq = Square()
print(sq.area()) # 64 (side is found on the class)
print(Square.area(sq)) # 64 (equivalent to sq.area())
sq.side = 10
print(sq.area()) # 100 (side is found on the instance)Note how the area method is used by sq. The two calls, Square.area(sq) and sq.area(), are equivalent, and teach us how the mechanism works. Either you pass the instance to the method call (Square.area(sq)), which within the method will be called self, or you can use a more comfortable syntax: sq.area() and Python will translate that for you behind the curtains.
Let's look at a better example:
oop/class.price.py
class Price():
def final_price(self, vat, discount=0):
"""Returns price after applying vat and fixed discount."""
return (self.net_price * (100 + vat) / 100) - discount
p1 = Price()
p1.net_price = 100
print(Price.final_price(p1, 20, 10)) # 110 (100 * 1.2 - 10)
print(p1.final_price(20, 10)) # equivalentThe preceding code shows you that nothing prevents us from using arguments when declaring methods. We can use the exact same syntax as we used with the function, but we need to remember that the first argument will always be the instance.
Initializing an instance
Have you noticed how, before calling p1.final_price(...), we had to assign net_price to p1? There is a better way to do it. In other languages, this would be called a constructor, but in Python, it's not. It is actually an initializer, since it works on an already created instance, and therefore it's called __init__. It's a magic method, which is run right after the object is created. Python objects also have a __new__ method, which is the actual constructor. In practice, it's not so common to have to override it though, it's a practice that is mostly used when coding metaclasses, which is a fairly advanced topic that we won't explore in the book.
oop/class.init.py
class Rectangle():
def __init__(self, sideA, sideB):
self.sideA = sideA
self.sideB = sideB
def area(self):
return self.sideA * self.sideB
r1 = Rectangle(10, 4)
print(r1.sideA, r1.sideB) # 10 4
print(r1.area()) # 40
r2 = Rectangle(7, 3)
print(r2.area()) # 21Things are finally starting to take shape. When an object is created, the __init__ method is automatically run for us. In this case, I coded it so that when we create an object (by calling the class name like a function), we pass arguments to the creation call, like we would on any regular function call. The way we pass parameters follows the signature of the __init__ method, and therefore, in the two creation statements, 10 and 7 will be sideA for r1 and r2 respectively, while 4 and 3 will be sideB. You can see that the call to area() from r1 and r2 reflects that they have different instance arguments.
Setting up objects in this way is much nicer and convenient.
OOP is about code reuse
By now it should be pretty clear: OOP is all about code reuse. We define a class, we create instances, and those instances use methods that are defined only in the class. They will behave differently according to how the instances have been set up by the initializer.
Inheritance and composition
But this is just half of the story, OOP is much more powerful. We have two main design constructs to exploit: inheritance and composition.
Inheritance means that two objects are related by means of an Is-A type of relationship. On the other hand, composition means that two objects are related by means of a Has-A type of relationship. It's all very easy to explain with an example:
oop/class.inheritance.py
class Engine(): def start(self): pass def stop(self): pass class ElectricEngine(Engine): # Is-A Engine pass class V8Engine(Engine): # Is-A Engine pass class Car(): engine_cls = Engine def __init__(self): self.engine = self.engine_cls() # Has-A Engine def start(self): print( 'Starting engine {0} for car {1}... Wroom, wroom!' .format( self.engine.__class__.__name__, self.__class__.__name__) ) self.engine.start() def stop(self): self.engine.stop() class RaceCar(Car): # Is-A Car engine_cls = V8Engine class CityCar(Car): # Is-A Car engine_cls = ElectricEngine class F1Car(RaceCar): # Is-A RaceCar and also Is-A Car engine_cls = V8Engine car = Car() racecar = RaceCar() citycar = CityCar() f1car = F1Car() cars = [car, racecar, citycar, f1car] for car in cars: car.start() """ Prints: Starting engine Engine for car Car... Wroom, wroom! Starting engine V8Engine for car RaceCar... Wroom, wroom! Starting engine ElectricEngine for car CityCar... Wroom, wroom! Starting engine V8Engine for car F1Car... Wroom, wroom! """
The preceding example shows you both the Is-A and Has-A types of relationships between objects. First of all, let's consider Engine. It's a simple class that has two methods, start and stop. We then define ElectricEngine and V8Engine, which both inherit from Engine. You can see that by the fact that when we define them, we put Engine within the braces after the class name.
This means that both ElectricEngine and V8Engine inherit attributes and methods from the Engine class, which is said to be their base class.
The same happens with cars. Car is a base class for both RaceCar and CityCar. RaceCar is also the base class for F1Car. Another way of saying this is that F1Car inherits from RaceCar, which inherits from Car. Therefore, F1Car Is-A RaceCar and RaceCar Is-A Car. Because of the transitive property, we can say that F1Car Is-A Car as well. CityCar too, Is-A Car.
When we define class A(B): pass, we say A is the child of B, and B is the parent of A. parent and base are synonyms, as well as child and derived. Also, we say that a class inherits from another class, or that it extends it.
This is the inheritance mechanism.
On the other hand, let's go back to the code. Each class has a class attribute, engine_cls, which is a reference to the engine class we want to assign to each type of car. Car has a generic Engine, while the two race cars have a powerful V8 engine, and the city car has an electric one.
When a car is created in the initializer method __init__, we create an instance of whatever engine class is assigned to the car, and set it as engine instance attribute.
It makes sense to have engine_cls shared amongst all class instances because it's quite likely that the same instances of a car will have the same kind of engine. On the other hand, it wouldn't be good to have one single engine (an instance of any Engine class) as a class attribute, because we would be sharing one engine amongst all instances, which is incorrect.
The type of relationship between a car and its engine is a Has-A type. A car Has-A engine. This is called composition, and reflects the fact that objects can be made of many other objects. A car Has-A engine, gears, wheels, a frame, doors, seats, and so on.
When designing OOP code, it is of vital importance to describe objects in this way so that we can use inheritance and composition correctly to structure our code in the best way.
Before we leave this paragraph, let's check if I told you the truth with another example:
oop/class.issubclass.isinstance.py
car = Car()
racecar = RaceCar()
f1car = F1Car()
cars = [(car, 'car'), (racecar, 'racecar'), (f1car, 'f1car')]
car_classes = [Car, RaceCar, F1Car]
for car, car_name in cars:
for class_ in car_classes:
belongs = isinstance(car, class_)
msg = 'is a' if belongs else 'is not a'
print(car_name, msg, class_.__name__)
""" Prints:
car is a Car
car is not a RaceCar
car is not a F1Car
racecar is a Car
racecar is a RaceCar
racecar is not a F1Car
f1car is a Car
f1car is a RaceCar
f1car is a F1Car
"""As you can see, car is just an instance of Car, while racecar is an instance of RaceCar (and of Car by extension) and f1car is an instance of F1Car (and of both RaceCar and Car, by extension). A banana is an instance of Banana. But, also, it is a Fruit. Also, it is Food, right? This is the same concept.
To check if an object is an instance of a class, use the isinstance method. It is recommended over sheer type comparison (type(object) == Class).
Let's also check inheritance, same setup, with different for loops:
oop/class.issubclass.isinstance.py
for class1 in car_classes:
for class2 in car_classes:
is_subclass = issubclass(class1, class2)
msg = '{0} a subclass of'.format(
'is' if is_subclass else 'is not')
print(class1.__name__, msg, class2.__name__)
""" Prints:
Car is a subclass of Car
Car is not a subclass of RaceCar
Car is not a subclass of F1Car
RaceCar is a subclass of Car
RaceCar is a subclass of RaceCar
RaceCar is not a subclass of F1Car
F1Car is a subclass of Car
F1Car is a subclass of RaceCar
F1Car is a subclass of F1Car
"""Interestingly, we learn that a class is a subclass of itself. Check the output of the preceding example to see that it matches the explanation I provided.
Note
One thing to notice about conventions is that class names are always written using CapWords, which means ThisWayIsCorrect, as opposed to functions and methods, which are written this_way_is_correct. Also, when in the code you want to use a name which is a Python-reserved keyword or built-in function or class, the convention is to add a trailing underscore to the name. In the first for loop example, I'm looping through the class names using for class_ in ..., because class is a reserved word. But you already knew all this because you have thoroughly studied PEP8, right?
To help you picture the difference between Is-A and Has-A, take a look at the following diagram:
Accessing a base class
We've already seen class declarations like class ClassA: pass and class ClassB(BaseClassName): pass. When we don't specify a base class explicitly, Python will set the special object class as the base class for the one we're defining. Ultimately, all classes derive from object. Note that, if you don't specify a base class, braces are optional.
Therefore, writing class A: pass or class A(): pass or class A(object): pass is exactly the same thing. object is a special class in that it has the methods that are common to all Python classes, and it doesn't allow you to set any attributes on it.
Let's see how we can access a base class from within a class.
oop/super.duplication.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
self.title = title
self.publisher = publisher
self.pages = pages
self.format_ = format_Take a look at the preceding code. I highlighted the part of Ebook initialization that is duplicated from its base class Book. This is quite bad practice because we now have two sets of instructions that are doing the same thing. Moreover, any change in the signature of Book.__init__ will not reflect in Ebook. We know that Ebook Is-A Book, and therefore we would probably want changes to be reflected in the children classes.
Let's see one way to fix this issue:
oop/super.explicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
Book.__init__(self, title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFNow, that's better. We have removed that nasty duplication. Basically, we tell Python to call the __init__ method of the Book class, and we feed self to the call, making sure that we bind that call to the present instance.
If we modify the logic within the __init__ method of Book, we don't need to touch Ebook, it will auto adapt to the change.
This approach is good, but we can still do a bit better. Say that we change Book's name to Liber, because we've fallen in love with Latin. We have to change the __init__ method of Ebook to reflect the change. This can be avoided by using super.
oop/super.implicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
super().__init__(title, publisher, pages)
# Another way to do the same thing is:
# super(Ebook, self).__init__(title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFsuper is a function that returns a proxy object that delegates method calls to a parent or sibling class. In this case, it will delegate that call to __init__ to the Book class, and the beauty of this method is that now we're even free to change Book to Liber without having to touch the logic in the __init__ method of Ebook.
Now that we know how to access a base class from a child, let's explore Python's multiple inheritance.
Multiple inheritance
Apart from composing a class using more than one base class, what is of interest here is how an attribute search is performed. Take a look at the following diagram:
As you can see, Shape and Plotter act as base classes for all the others. Polygon inherits directly from them, RegularPolygon inherits from Polygon, and both RegularHexagon and Square inherit from RegulaPolygon. Note also that Shape and Plotter implicitly inherit from object, therefore we have what is called a diamond or, in simpler terms, more than one path to reach a base class. We'll see why this matters in a few moments. Let's translate it into some simple code:
oop/multiple.inheritance.py
class Shape: geometric_type = 'Generic Shape' def area(self): # This acts as placeholder for the interface raise NotImplementedError def get_geometric_type(self): return self.geometric_type class Plotter: def plot(self, ratio, topleft): # Imagine some nice plotting logic here... print('Plotting at {}, ratio {}.'.format( topleft, ratio)) class Polygon(Shape, Plotter): # base class for polygons geometric_type = 'Polygon' class RegularPolygon(Polygon): # Is-A Polygon geometric_type = 'Regular Polygon' def __init__(self, side): self.side = side class RegularHexagon(RegularPolygon): # Is-A RegularPolygon geometric_type = 'RegularHexagon' def area(self): return 1.5 * (3 ** .5 * self.side ** 2) class Square(RegularPolygon): # Is-A RegularPolygon geometric_type = 'Square' def area(self): return self.side * self.side hexagon = RegularHexagon(10) print(hexagon.area()) # 259.8076211353316 print(hexagon.get_geometric_type()) # RegularHexagon hexagon.plot(0.8, (75, 77)) # Plotting at (75, 77), ratio 0.8. square = Square(12) print(square.area()) # 144 print(square.get_geometric_type()) # Square square.plot(0.93, (74, 75)) # Plotting at (74, 75), ratio 0.93.
Take a look at the preceding code: the class Shape has one attribute, geometric_type, and two methods: area and get_geometric_type. It's quite common to use base classes (like Shape, in our example) to define an interface: methods for which children must provide an implementation. There are different and better ways to do this, but I want to keep this example as simple as possible.
We also have the Plotter class, which adds the plot method, thereby providing plotting capabilities for any class that inherits from it. Of course, the plot implementation is just a dummy print in this example. The first interesting class is Polygon, which inherits from both Shape and Plotter.
There are many types of polygons, one of which is the regular one, which is both equiangular (all angles are equal) and equilateral (all sides are equal), so we create the RegularPolygon class that inherits from Polygon. Because for a regular polygon, all sides are equal, we can implement a simple __init__ method on RegularPolygon, which takes the length of the side. Finally, we create the RegularHexagon and Square classes, which both inherit from RegularPolygon.
This structure is quite long, but hopefully gives you an idea of how to specialize the classification of your objects when you design the code.
Now, please take a look at the last eight lines. Note that when I call the area method on hexagon and square, I get the correct area for both. This is because they both provide the correct implementation logic for it. Also, I can call get_geometric_type on both of them, even though it is not defined on their classes, and Python has to go all the way up to Shape to find an implementation for it. Note that, even though the implementation is provided in the Shape class, the self.geometric_type used for the return value is correctly taken from the caller instance.
The plot method calls are also interesting, and show you how you can enrich your objects with capabilities they wouldn't otherwise have. This technique is very popular in web frameworks such as Django (which we'll explore in two later chapters), which provides special classes called mixins, whose capabilities you can just use out of the box. All you have to do is to define the desired mixin as one the base classes for your own, and that's it.
Multiple inheritance is powerful, but can also get really messy, so we need to make sure we understand what happens when we use it.
Method resolution order
By now, we know that when you ask for someobject.attribute, and attribute is not found on that object, Python starts searching in the class someobject was created from. If it's not there either, Python searches up the inheritance chain until either attribute is found or the object class is reached. This is quite simple to understand if the inheritance chain is only comprised of single inheritance steps, which means that classes have only one parent. However, when multiple inheritance is involved, there are cases when it's not straightforward to predict what will be the next class that will be searched for if an attribute is not found.
Python provides a way to always know what is the order in which classes are searched on attribute lookup: the method resolution order.
Note
The method resolution order (MRO) is the order in which base classes are searched for a member during lookup. From version 2.3 Python uses an algorithm called C3, which guarantees monotonicity.
In Python 2.2, new-style classes were introduced. The way you write a new-style class in Python 2.* is to define it with an explicit object base class. Classic classes were not explicitly inheriting from object and have been removed in Python 3.
One of the differences between classic and new style-classes in Python 2.* is that new-style classes are searched with the new MRO.
With regards to the previous example, let's see what is the MRO for the Square class:
oop/multiple.inheritance.py
print(square.__class__.__mro__)
# prints:
# (<class '__main__.Square'>, <class '__main__.RegularPolygon'>,
# <class '__main__.Polygon'>, <class '__main__.Shape'>,
# <class '__main__.Plotter'>, <class 'object'>)To get to the MRO of a class, we can go from the instance to its __class__ attribute and from that to its __mro__ attribute. Alternatively, we could have called Square.__mro__, or Square.mro() directly, but if you have to do it dynamically, it's more likely you will have an object in your hands rather than a class.
Note that the only point of doubt is the bisection after Polygon, where the inheritance chain breaks into two ways, one leads to Shape and the other to Plotter. We know by scanning the MRO for the Square class that Shape is searched before Plotter.
Why is this important? Well, imagine the following code:
oop/mro.simple.py
class A:
label = 'a'
class B(A):
label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # Hypothetically this could be either 'b' or 'c'Both B and C inherit from A, and D inherits from both B and C. This means that the lookup for the label attribute can reach the top (A) through both B or C. According to which is reached first, we get a different result.
So, in the preceding example we get 'b', which is what we were expecting, since B is the leftmost one amongst base classes of D. But what happens if I remove the label attribute from B? This would be the confusing situation: Will the algorithm go all the way up to A or will it get to C first? Let's find out!
oop/mro.py
class A:
label = 'a'
class B(A):
pass # was: label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # 'c'
print(d.__class__.mro()) # notice another way to get the MRO
# prints:
# [<class '__main__.D'>, <class '__main__.B'>,
# <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]So, we learn that the MRO is D-B-C-A-(object), which means when we ask for d.label, we get 'c', which is correct.
In day to day programming, it is not quite common to have to deal with the MRO, but the first time you fight against some mixin from a framework, I promise you'll be glad I spent a paragraph explaining it.
Static and class methods
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
Private methods and name mangling
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Attribute shadowing
When you search for an attribute in an object, if it is not found, Python keeps searching in the class that was used to create that object (and keeps searching until it's either found or the end of the inheritance chain is reached). This leads to an interesting shadowing behavior. Let's look at an example:
oop/class.attribute.shadowing.py
class Point():
x = 10
y = 7
p = Point()
print(p.x) # 10 (from class attribute)
print(p.y) # 7 (from class attribute)
p.x = 12 # p gets its own 'x' attribute
print(p.x) # 12 (now found on the instance)
print(Point.x) # 10 (class attribute still the same)
del p.x # we delete instance attribute
print(p.x) # 10 (now search has to go again to find class attr)
p.z = 3 # let's make it a 3D point
print(p.z) # 3
print(Point.z)
# AttributeError: type object 'Point' has no attribute 'z'The preceding code is very interesting. We have defined a class called Point with two class attributes, x and y. When we create an instance, p, you can see that we can print both x and y from p's namespace (p.x and p.y). What happens when we do that is that Python doesn't find any x or y attributes on the instance, and therefore searches the class, and finds them there.
Then we give p its own x attribute by assigning p.x = 12. This behavior may appear a bit weird at first, but if you think about it, it's exactly the same as what happens in a function that declares x = 12 when there is a global x = 10 outside. We know that x = 12 won't affect the global one, and for classes and instances, it is exactly the same.
After assigning p.x = 12, when we print it, the search doesn't need to read the class attributes, because x is found on the instance, therefore we get 12 printed out.
We also print Point.x which refers to x in the class namespace.
And then, we delete x from the namespace of p, which means that, on the next line, when we print it again, Python will go again and search for it in the class, because it won't be found in the instance any more.
The last three lines show you that assigning attributes to an instance doesn't mean that they will be found in the class. Instances get whatever is in the class, but the opposite is not true.
What do you think about putting the x and y coordinates as class attributes? Do you think it was a good idea?
I, me, and myself – using the self variable
From within a class method we can refer to an instance by means of a special argument, called self by convention. self is always the first attribute of an instance method. Let's examine this behavior together with how we can share, not just attributes, but methods with all instances.
oop/class.self.py
class Square():
side = 8
def area(self): # self is a reference to an instance
return self.side ** 2
sq = Square()
print(sq.area()) # 64 (side is found on the class)
print(Square.area(sq)) # 64 (equivalent to sq.area())
sq.side = 10
print(sq.area()) # 100 (side is found on the instance)Note how the area method is used by sq. The two calls, Square.area(sq) and sq.area(), are equivalent, and teach us how the mechanism works. Either you pass the instance to the method call (Square.area(sq)), which within the method will be called self, or you can use a more comfortable syntax: sq.area() and Python will translate that for you behind the curtains.
Let's look at a better example:
oop/class.price.py
class Price():
def final_price(self, vat, discount=0):
"""Returns price after applying vat and fixed discount."""
return (self.net_price * (100 + vat) / 100) - discount
p1 = Price()
p1.net_price = 100
print(Price.final_price(p1, 20, 10)) # 110 (100 * 1.2 - 10)
print(p1.final_price(20, 10)) # equivalentThe preceding code shows you that nothing prevents us from using arguments when declaring methods. We can use the exact same syntax as we used with the function, but we need to remember that the first argument will always be the instance.
Initializing an instance
Have you noticed how, before calling p1.final_price(...), we had to assign net_price to p1? There is a better way to do it. In other languages, this would be called a constructor, but in Python, it's not. It is actually an initializer, since it works on an already created instance, and therefore it's called __init__. It's a magic method, which is run right after the object is created. Python objects also have a __new__ method, which is the actual constructor. In practice, it's not so common to have to override it though, it's a practice that is mostly used when coding metaclasses, which is a fairly advanced topic that we won't explore in the book.
oop/class.init.py
class Rectangle():
def __init__(self, sideA, sideB):
self.sideA = sideA
self.sideB = sideB
def area(self):
return self.sideA * self.sideB
r1 = Rectangle(10, 4)
print(r1.sideA, r1.sideB) # 10 4
print(r1.area()) # 40
r2 = Rectangle(7, 3)
print(r2.area()) # 21Things are finally starting to take shape. When an object is created, the __init__ method is automatically run for us. In this case, I coded it so that when we create an object (by calling the class name like a function), we pass arguments to the creation call, like we would on any regular function call. The way we pass parameters follows the signature of the __init__ method, and therefore, in the two creation statements, 10 and 7 will be sideA for r1 and r2 respectively, while 4 and 3 will be sideB. You can see that the call to area() from r1 and r2 reflects that they have different instance arguments.
Setting up objects in this way is much nicer and convenient.
OOP is about code reuse
By now it should be pretty clear: OOP is all about code reuse. We define a class, we create instances, and those instances use methods that are defined only in the class. They will behave differently according to how the instances have been set up by the initializer.
Inheritance and composition
But this is just half of the story, OOP is much more powerful. We have two main design constructs to exploit: inheritance and composition.
Inheritance means that two objects are related by means of an Is-A type of relationship. On the other hand, composition means that two objects are related by means of a Has-A type of relationship. It's all very easy to explain with an example:
oop/class.inheritance.py
class Engine(): def start(self): pass def stop(self): pass class ElectricEngine(Engine): # Is-A Engine pass class V8Engine(Engine): # Is-A Engine pass class Car(): engine_cls = Engine def __init__(self): self.engine = self.engine_cls() # Has-A Engine def start(self): print( 'Starting engine {0} for car {1}... Wroom, wroom!' .format( self.engine.__class__.__name__, self.__class__.__name__) ) self.engine.start() def stop(self): self.engine.stop() class RaceCar(Car): # Is-A Car engine_cls = V8Engine class CityCar(Car): # Is-A Car engine_cls = ElectricEngine class F1Car(RaceCar): # Is-A RaceCar and also Is-A Car engine_cls = V8Engine car = Car() racecar = RaceCar() citycar = CityCar() f1car = F1Car() cars = [car, racecar, citycar, f1car] for car in cars: car.start() """ Prints: Starting engine Engine for car Car... Wroom, wroom! Starting engine V8Engine for car RaceCar... Wroom, wroom! Starting engine ElectricEngine for car CityCar... Wroom, wroom! Starting engine V8Engine for car F1Car... Wroom, wroom! """
The preceding example shows you both the Is-A and Has-A types of relationships between objects. First of all, let's consider Engine. It's a simple class that has two methods, start and stop. We then define ElectricEngine and V8Engine, which both inherit from Engine. You can see that by the fact that when we define them, we put Engine within the braces after the class name.
This means that both ElectricEngine and V8Engine inherit attributes and methods from the Engine class, which is said to be their base class.
The same happens with cars. Car is a base class for both RaceCar and CityCar. RaceCar is also the base class for F1Car. Another way of saying this is that F1Car inherits from RaceCar, which inherits from Car. Therefore, F1Car Is-A RaceCar and RaceCar Is-A Car. Because of the transitive property, we can say that F1Car Is-A Car as well. CityCar too, Is-A Car.
When we define class A(B): pass, we say A is the child of B, and B is the parent of A. parent and base are synonyms, as well as child and derived. Also, we say that a class inherits from another class, or that it extends it.
This is the inheritance mechanism.
On the other hand, let's go back to the code. Each class has a class attribute, engine_cls, which is a reference to the engine class we want to assign to each type of car. Car has a generic Engine, while the two race cars have a powerful V8 engine, and the city car has an electric one.
When a car is created in the initializer method __init__, we create an instance of whatever engine class is assigned to the car, and set it as engine instance attribute.
It makes sense to have engine_cls shared amongst all class instances because it's quite likely that the same instances of a car will have the same kind of engine. On the other hand, it wouldn't be good to have one single engine (an instance of any Engine class) as a class attribute, because we would be sharing one engine amongst all instances, which is incorrect.
The type of relationship between a car and its engine is a Has-A type. A car Has-A engine. This is called composition, and reflects the fact that objects can be made of many other objects. A car Has-A engine, gears, wheels, a frame, doors, seats, and so on.
When designing OOP code, it is of vital importance to describe objects in this way so that we can use inheritance and composition correctly to structure our code in the best way.
Before we leave this paragraph, let's check if I told you the truth with another example:
oop/class.issubclass.isinstance.py
car = Car()
racecar = RaceCar()
f1car = F1Car()
cars = [(car, 'car'), (racecar, 'racecar'), (f1car, 'f1car')]
car_classes = [Car, RaceCar, F1Car]
for car, car_name in cars:
for class_ in car_classes:
belongs = isinstance(car, class_)
msg = 'is a' if belongs else 'is not a'
print(car_name, msg, class_.__name__)
""" Prints:
car is a Car
car is not a RaceCar
car is not a F1Car
racecar is a Car
racecar is a RaceCar
racecar is not a F1Car
f1car is a Car
f1car is a RaceCar
f1car is a F1Car
"""As you can see, car is just an instance of Car, while racecar is an instance of RaceCar (and of Car by extension) and f1car is an instance of F1Car (and of both RaceCar and Car, by extension). A banana is an instance of Banana. But, also, it is a Fruit. Also, it is Food, right? This is the same concept.
To check if an object is an instance of a class, use the isinstance method. It is recommended over sheer type comparison (type(object) == Class).
Let's also check inheritance, same setup, with different for loops:
oop/class.issubclass.isinstance.py
for class1 in car_classes:
for class2 in car_classes:
is_subclass = issubclass(class1, class2)
msg = '{0} a subclass of'.format(
'is' if is_subclass else 'is not')
print(class1.__name__, msg, class2.__name__)
""" Prints:
Car is a subclass of Car
Car is not a subclass of RaceCar
Car is not a subclass of F1Car
RaceCar is a subclass of Car
RaceCar is a subclass of RaceCar
RaceCar is not a subclass of F1Car
F1Car is a subclass of Car
F1Car is a subclass of RaceCar
F1Car is a subclass of F1Car
"""Interestingly, we learn that a class is a subclass of itself. Check the output of the preceding example to see that it matches the explanation I provided.
Note
One thing to notice about conventions is that class names are always written using CapWords, which means ThisWayIsCorrect, as opposed to functions and methods, which are written this_way_is_correct. Also, when in the code you want to use a name which is a Python-reserved keyword or built-in function or class, the convention is to add a trailing underscore to the name. In the first for loop example, I'm looping through the class names using for class_ in ..., because class is a reserved word. But you already knew all this because you have thoroughly studied PEP8, right?
To help you picture the difference between Is-A and Has-A, take a look at the following diagram:
Accessing a base class
We've already seen class declarations like class ClassA: pass and class ClassB(BaseClassName): pass. When we don't specify a base class explicitly, Python will set the special object class as the base class for the one we're defining. Ultimately, all classes derive from object. Note that, if you don't specify a base class, braces are optional.
Therefore, writing class A: pass or class A(): pass or class A(object): pass is exactly the same thing. object is a special class in that it has the methods that are common to all Python classes, and it doesn't allow you to set any attributes on it.
Let's see how we can access a base class from within a class.
oop/super.duplication.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
self.title = title
self.publisher = publisher
self.pages = pages
self.format_ = format_Take a look at the preceding code. I highlighted the part of Ebook initialization that is duplicated from its base class Book. This is quite bad practice because we now have two sets of instructions that are doing the same thing. Moreover, any change in the signature of Book.__init__ will not reflect in Ebook. We know that Ebook Is-A Book, and therefore we would probably want changes to be reflected in the children classes.
Let's see one way to fix this issue:
oop/super.explicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
Book.__init__(self, title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFNow, that's better. We have removed that nasty duplication. Basically, we tell Python to call the __init__ method of the Book class, and we feed self to the call, making sure that we bind that call to the present instance.
If we modify the logic within the __init__ method of Book, we don't need to touch Ebook, it will auto adapt to the change.
This approach is good, but we can still do a bit better. Say that we change Book's name to Liber, because we've fallen in love with Latin. We have to change the __init__ method of Ebook to reflect the change. This can be avoided by using super.
oop/super.implicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
super().__init__(title, publisher, pages)
# Another way to do the same thing is:
# super(Ebook, self).__init__(title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFsuper is a function that returns a proxy object that delegates method calls to a parent or sibling class. In this case, it will delegate that call to __init__ to the Book class, and the beauty of this method is that now we're even free to change Book to Liber without having to touch the logic in the __init__ method of Ebook.
Now that we know how to access a base class from a child, let's explore Python's multiple inheritance.
Multiple inheritance
Apart from composing a class using more than one base class, what is of interest here is how an attribute search is performed. Take a look at the following diagram:
As you can see, Shape and Plotter act as base classes for all the others. Polygon inherits directly from them, RegularPolygon inherits from Polygon, and both RegularHexagon and Square inherit from RegulaPolygon. Note also that Shape and Plotter implicitly inherit from object, therefore we have what is called a diamond or, in simpler terms, more than one path to reach a base class. We'll see why this matters in a few moments. Let's translate it into some simple code:
oop/multiple.inheritance.py
class Shape: geometric_type = 'Generic Shape' def area(self): # This acts as placeholder for the interface raise NotImplementedError def get_geometric_type(self): return self.geometric_type class Plotter: def plot(self, ratio, topleft): # Imagine some nice plotting logic here... print('Plotting at {}, ratio {}.'.format( topleft, ratio)) class Polygon(Shape, Plotter): # base class for polygons geometric_type = 'Polygon' class RegularPolygon(Polygon): # Is-A Polygon geometric_type = 'Regular Polygon' def __init__(self, side): self.side = side class RegularHexagon(RegularPolygon): # Is-A RegularPolygon geometric_type = 'RegularHexagon' def area(self): return 1.5 * (3 ** .5 * self.side ** 2) class Square(RegularPolygon): # Is-A RegularPolygon geometric_type = 'Square' def area(self): return self.side * self.side hexagon = RegularHexagon(10) print(hexagon.area()) # 259.8076211353316 print(hexagon.get_geometric_type()) # RegularHexagon hexagon.plot(0.8, (75, 77)) # Plotting at (75, 77), ratio 0.8. square = Square(12) print(square.area()) # 144 print(square.get_geometric_type()) # Square square.plot(0.93, (74, 75)) # Plotting at (74, 75), ratio 0.93.
Take a look at the preceding code: the class Shape has one attribute, geometric_type, and two methods: area and get_geometric_type. It's quite common to use base classes (like Shape, in our example) to define an interface: methods for which children must provide an implementation. There are different and better ways to do this, but I want to keep this example as simple as possible.
We also have the Plotter class, which adds the plot method, thereby providing plotting capabilities for any class that inherits from it. Of course, the plot implementation is just a dummy print in this example. The first interesting class is Polygon, which inherits from both Shape and Plotter.
There are many types of polygons, one of which is the regular one, which is both equiangular (all angles are equal) and equilateral (all sides are equal), so we create the RegularPolygon class that inherits from Polygon. Because for a regular polygon, all sides are equal, we can implement a simple __init__ method on RegularPolygon, which takes the length of the side. Finally, we create the RegularHexagon and Square classes, which both inherit from RegularPolygon.
This structure is quite long, but hopefully gives you an idea of how to specialize the classification of your objects when you design the code.
Now, please take a look at the last eight lines. Note that when I call the area method on hexagon and square, I get the correct area for both. This is because they both provide the correct implementation logic for it. Also, I can call get_geometric_type on both of them, even though it is not defined on their classes, and Python has to go all the way up to Shape to find an implementation for it. Note that, even though the implementation is provided in the Shape class, the self.geometric_type used for the return value is correctly taken from the caller instance.
The plot method calls are also interesting, and show you how you can enrich your objects with capabilities they wouldn't otherwise have. This technique is very popular in web frameworks such as Django (which we'll explore in two later chapters), which provides special classes called mixins, whose capabilities you can just use out of the box. All you have to do is to define the desired mixin as one the base classes for your own, and that's it.
Multiple inheritance is powerful, but can also get really messy, so we need to make sure we understand what happens when we use it.
Method resolution order
By now, we know that when you ask for someobject.attribute, and attribute is not found on that object, Python starts searching in the class someobject was created from. If it's not there either, Python searches up the inheritance chain until either attribute is found or the object class is reached. This is quite simple to understand if the inheritance chain is only comprised of single inheritance steps, which means that classes have only one parent. However, when multiple inheritance is involved, there are cases when it's not straightforward to predict what will be the next class that will be searched for if an attribute is not found.
Python provides a way to always know what is the order in which classes are searched on attribute lookup: the method resolution order.
Note
The method resolution order (MRO) is the order in which base classes are searched for a member during lookup. From version 2.3 Python uses an algorithm called C3, which guarantees monotonicity.
In Python 2.2, new-style classes were introduced. The way you write a new-style class in Python 2.* is to define it with an explicit object base class. Classic classes were not explicitly inheriting from object and have been removed in Python 3.
One of the differences between classic and new style-classes in Python 2.* is that new-style classes are searched with the new MRO.
With regards to the previous example, let's see what is the MRO for the Square class:
oop/multiple.inheritance.py
print(square.__class__.__mro__)
# prints:
# (<class '__main__.Square'>, <class '__main__.RegularPolygon'>,
# <class '__main__.Polygon'>, <class '__main__.Shape'>,
# <class '__main__.Plotter'>, <class 'object'>)To get to the MRO of a class, we can go from the instance to its __class__ attribute and from that to its __mro__ attribute. Alternatively, we could have called Square.__mro__, or Square.mro() directly, but if you have to do it dynamically, it's more likely you will have an object in your hands rather than a class.
Note that the only point of doubt is the bisection after Polygon, where the inheritance chain breaks into two ways, one leads to Shape and the other to Plotter. We know by scanning the MRO for the Square class that Shape is searched before Plotter.
Why is this important? Well, imagine the following code:
oop/mro.simple.py
class A:
label = 'a'
class B(A):
label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # Hypothetically this could be either 'b' or 'c'Both B and C inherit from A, and D inherits from both B and C. This means that the lookup for the label attribute can reach the top (A) through both B or C. According to which is reached first, we get a different result.
So, in the preceding example we get 'b', which is what we were expecting, since B is the leftmost one amongst base classes of D. But what happens if I remove the label attribute from B? This would be the confusing situation: Will the algorithm go all the way up to A or will it get to C first? Let's find out!
oop/mro.py
class A:
label = 'a'
class B(A):
pass # was: label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # 'c'
print(d.__class__.mro()) # notice another way to get the MRO
# prints:
# [<class '__main__.D'>, <class '__main__.B'>,
# <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]So, we learn that the MRO is D-B-C-A-(object), which means when we ask for d.label, we get 'c', which is correct.
In day to day programming, it is not quite common to have to deal with the MRO, but the first time you fight against some mixin from a framework, I promise you'll be glad I spent a paragraph explaining it.
Static and class methods
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
Private methods and name mangling
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
I, me, and myself – using the self variable
From within a class method we can refer to an instance by means of a special argument, called self by convention. self is always the first attribute of an instance method. Let's examine this behavior together with how we can share, not just attributes, but methods with all instances.
oop/class.self.py
class Square():
side = 8
def area(self): # self is a reference to an instance
return self.side ** 2
sq = Square()
print(sq.area()) # 64 (side is found on the class)
print(Square.area(sq)) # 64 (equivalent to sq.area())
sq.side = 10
print(sq.area()) # 100 (side is found on the instance)Note how the area method is used by sq. The two calls, Square.area(sq) and sq.area(), are equivalent, and teach us how the mechanism works. Either you pass the instance to the method call (Square.area(sq)), which within the method will be called self, or you can use a more comfortable syntax: sq.area() and Python will translate that for you behind the curtains.
Let's look at a better example:
oop/class.price.py
class Price():
def final_price(self, vat, discount=0):
"""Returns price after applying vat and fixed discount."""
return (self.net_price * (100 + vat) / 100) - discount
p1 = Price()
p1.net_price = 100
print(Price.final_price(p1, 20, 10)) # 110 (100 * 1.2 - 10)
print(p1.final_price(20, 10)) # equivalentThe preceding code shows you that nothing prevents us from using arguments when declaring methods. We can use the exact same syntax as we used with the function, but we need to remember that the first argument will always be the instance.
Initializing an instance
Have you noticed how, before calling p1.final_price(...), we had to assign net_price to p1? There is a better way to do it. In other languages, this would be called a constructor, but in Python, it's not. It is actually an initializer, since it works on an already created instance, and therefore it's called __init__. It's a magic method, which is run right after the object is created. Python objects also have a __new__ method, which is the actual constructor. In practice, it's not so common to have to override it though, it's a practice that is mostly used when coding metaclasses, which is a fairly advanced topic that we won't explore in the book.
oop/class.init.py
class Rectangle():
def __init__(self, sideA, sideB):
self.sideA = sideA
self.sideB = sideB
def area(self):
return self.sideA * self.sideB
r1 = Rectangle(10, 4)
print(r1.sideA, r1.sideB) # 10 4
print(r1.area()) # 40
r2 = Rectangle(7, 3)
print(r2.area()) # 21Things are finally starting to take shape. When an object is created, the __init__ method is automatically run for us. In this case, I coded it so that when we create an object (by calling the class name like a function), we pass arguments to the creation call, like we would on any regular function call. The way we pass parameters follows the signature of the __init__ method, and therefore, in the two creation statements, 10 and 7 will be sideA for r1 and r2 respectively, while 4 and 3 will be sideB. You can see that the call to area() from r1 and r2 reflects that they have different instance arguments.
Setting up objects in this way is much nicer and convenient.
OOP is about code reuse
By now it should be pretty clear: OOP is all about code reuse. We define a class, we create instances, and those instances use methods that are defined only in the class. They will behave differently according to how the instances have been set up by the initializer.
Inheritance and composition
But this is just half of the story, OOP is much more powerful. We have two main design constructs to exploit: inheritance and composition.
Inheritance means that two objects are related by means of an Is-A type of relationship. On the other hand, composition means that two objects are related by means of a Has-A type of relationship. It's all very easy to explain with an example:
oop/class.inheritance.py
class Engine(): def start(self): pass def stop(self): pass class ElectricEngine(Engine): # Is-A Engine pass class V8Engine(Engine): # Is-A Engine pass class Car(): engine_cls = Engine def __init__(self): self.engine = self.engine_cls() # Has-A Engine def start(self): print( 'Starting engine {0} for car {1}... Wroom, wroom!' .format( self.engine.__class__.__name__, self.__class__.__name__) ) self.engine.start() def stop(self): self.engine.stop() class RaceCar(Car): # Is-A Car engine_cls = V8Engine class CityCar(Car): # Is-A Car engine_cls = ElectricEngine class F1Car(RaceCar): # Is-A RaceCar and also Is-A Car engine_cls = V8Engine car = Car() racecar = RaceCar() citycar = CityCar() f1car = F1Car() cars = [car, racecar, citycar, f1car] for car in cars: car.start() """ Prints: Starting engine Engine for car Car... Wroom, wroom! Starting engine V8Engine for car RaceCar... Wroom, wroom! Starting engine ElectricEngine for car CityCar... Wroom, wroom! Starting engine V8Engine for car F1Car... Wroom, wroom! """
The preceding example shows you both the Is-A and Has-A types of relationships between objects. First of all, let's consider Engine. It's a simple class that has two methods, start and stop. We then define ElectricEngine and V8Engine, which both inherit from Engine. You can see that by the fact that when we define them, we put Engine within the braces after the class name.
This means that both ElectricEngine and V8Engine inherit attributes and methods from the Engine class, which is said to be their base class.
The same happens with cars. Car is a base class for both RaceCar and CityCar. RaceCar is also the base class for F1Car. Another way of saying this is that F1Car inherits from RaceCar, which inherits from Car. Therefore, F1Car Is-A RaceCar and RaceCar Is-A Car. Because of the transitive property, we can say that F1Car Is-A Car as well. CityCar too, Is-A Car.
When we define class A(B): pass, we say A is the child of B, and B is the parent of A. parent and base are synonyms, as well as child and derived. Also, we say that a class inherits from another class, or that it extends it.
This is the inheritance mechanism.
On the other hand, let's go back to the code. Each class has a class attribute, engine_cls, which is a reference to the engine class we want to assign to each type of car. Car has a generic Engine, while the two race cars have a powerful V8 engine, and the city car has an electric one.
When a car is created in the initializer method __init__, we create an instance of whatever engine class is assigned to the car, and set it as engine instance attribute.
It makes sense to have engine_cls shared amongst all class instances because it's quite likely that the same instances of a car will have the same kind of engine. On the other hand, it wouldn't be good to have one single engine (an instance of any Engine class) as a class attribute, because we would be sharing one engine amongst all instances, which is incorrect.
The type of relationship between a car and its engine is a Has-A type. A car Has-A engine. This is called composition, and reflects the fact that objects can be made of many other objects. A car Has-A engine, gears, wheels, a frame, doors, seats, and so on.
When designing OOP code, it is of vital importance to describe objects in this way so that we can use inheritance and composition correctly to structure our code in the best way.
Before we leave this paragraph, let's check if I told you the truth with another example:
oop/class.issubclass.isinstance.py
car = Car()
racecar = RaceCar()
f1car = F1Car()
cars = [(car, 'car'), (racecar, 'racecar'), (f1car, 'f1car')]
car_classes = [Car, RaceCar, F1Car]
for car, car_name in cars:
for class_ in car_classes:
belongs = isinstance(car, class_)
msg = 'is a' if belongs else 'is not a'
print(car_name, msg, class_.__name__)
""" Prints:
car is a Car
car is not a RaceCar
car is not a F1Car
racecar is a Car
racecar is a RaceCar
racecar is not a F1Car
f1car is a Car
f1car is a RaceCar
f1car is a F1Car
"""As you can see, car is just an instance of Car, while racecar is an instance of RaceCar (and of Car by extension) and f1car is an instance of F1Car (and of both RaceCar and Car, by extension). A banana is an instance of Banana. But, also, it is a Fruit. Also, it is Food, right? This is the same concept.
To check if an object is an instance of a class, use the isinstance method. It is recommended over sheer type comparison (type(object) == Class).
Let's also check inheritance, same setup, with different for loops:
oop/class.issubclass.isinstance.py
for class1 in car_classes:
for class2 in car_classes:
is_subclass = issubclass(class1, class2)
msg = '{0} a subclass of'.format(
'is' if is_subclass else 'is not')
print(class1.__name__, msg, class2.__name__)
""" Prints:
Car is a subclass of Car
Car is not a subclass of RaceCar
Car is not a subclass of F1Car
RaceCar is a subclass of Car
RaceCar is a subclass of RaceCar
RaceCar is not a subclass of F1Car
F1Car is a subclass of Car
F1Car is a subclass of RaceCar
F1Car is a subclass of F1Car
"""Interestingly, we learn that a class is a subclass of itself. Check the output of the preceding example to see that it matches the explanation I provided.
Note
One thing to notice about conventions is that class names are always written using CapWords, which means ThisWayIsCorrect, as opposed to functions and methods, which are written this_way_is_correct. Also, when in the code you want to use a name which is a Python-reserved keyword or built-in function or class, the convention is to add a trailing underscore to the name. In the first for loop example, I'm looping through the class names using for class_ in ..., because class is a reserved word. But you already knew all this because you have thoroughly studied PEP8, right?
To help you picture the difference between Is-A and Has-A, take a look at the following diagram:
Accessing a base class
We've already seen class declarations like class ClassA: pass and class ClassB(BaseClassName): pass. When we don't specify a base class explicitly, Python will set the special object class as the base class for the one we're defining. Ultimately, all classes derive from object. Note that, if you don't specify a base class, braces are optional.
Therefore, writing class A: pass or class A(): pass or class A(object): pass is exactly the same thing. object is a special class in that it has the methods that are common to all Python classes, and it doesn't allow you to set any attributes on it.
Let's see how we can access a base class from within a class.
oop/super.duplication.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
self.title = title
self.publisher = publisher
self.pages = pages
self.format_ = format_Take a look at the preceding code. I highlighted the part of Ebook initialization that is duplicated from its base class Book. This is quite bad practice because we now have two sets of instructions that are doing the same thing. Moreover, any change in the signature of Book.__init__ will not reflect in Ebook. We know that Ebook Is-A Book, and therefore we would probably want changes to be reflected in the children classes.
Let's see one way to fix this issue:
oop/super.explicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
Book.__init__(self, title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFNow, that's better. We have removed that nasty duplication. Basically, we tell Python to call the __init__ method of the Book class, and we feed self to the call, making sure that we bind that call to the present instance.
If we modify the logic within the __init__ method of Book, we don't need to touch Ebook, it will auto adapt to the change.
This approach is good, but we can still do a bit better. Say that we change Book's name to Liber, because we've fallen in love with Latin. We have to change the __init__ method of Ebook to reflect the change. This can be avoided by using super.
oop/super.implicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
super().__init__(title, publisher, pages)
# Another way to do the same thing is:
# super(Ebook, self).__init__(title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFsuper is a function that returns a proxy object that delegates method calls to a parent or sibling class. In this case, it will delegate that call to __init__ to the Book class, and the beauty of this method is that now we're even free to change Book to Liber without having to touch the logic in the __init__ method of Ebook.
Now that we know how to access a base class from a child, let's explore Python's multiple inheritance.
Multiple inheritance
Apart from composing a class using more than one base class, what is of interest here is how an attribute search is performed. Take a look at the following diagram:
As you can see, Shape and Plotter act as base classes for all the others. Polygon inherits directly from them, RegularPolygon inherits from Polygon, and both RegularHexagon and Square inherit from RegulaPolygon. Note also that Shape and Plotter implicitly inherit from object, therefore we have what is called a diamond or, in simpler terms, more than one path to reach a base class. We'll see why this matters in a few moments. Let's translate it into some simple code:
oop/multiple.inheritance.py
class Shape: geometric_type = 'Generic Shape' def area(self): # This acts as placeholder for the interface raise NotImplementedError def get_geometric_type(self): return self.geometric_type class Plotter: def plot(self, ratio, topleft): # Imagine some nice plotting logic here... print('Plotting at {}, ratio {}.'.format( topleft, ratio)) class Polygon(Shape, Plotter): # base class for polygons geometric_type = 'Polygon' class RegularPolygon(Polygon): # Is-A Polygon geometric_type = 'Regular Polygon' def __init__(self, side): self.side = side class RegularHexagon(RegularPolygon): # Is-A RegularPolygon geometric_type = 'RegularHexagon' def area(self): return 1.5 * (3 ** .5 * self.side ** 2) class Square(RegularPolygon): # Is-A RegularPolygon geometric_type = 'Square' def area(self): return self.side * self.side hexagon = RegularHexagon(10) print(hexagon.area()) # 259.8076211353316 print(hexagon.get_geometric_type()) # RegularHexagon hexagon.plot(0.8, (75, 77)) # Plotting at (75, 77), ratio 0.8. square = Square(12) print(square.area()) # 144 print(square.get_geometric_type()) # Square square.plot(0.93, (74, 75)) # Plotting at (74, 75), ratio 0.93.
Take a look at the preceding code: the class Shape has one attribute, geometric_type, and two methods: area and get_geometric_type. It's quite common to use base classes (like Shape, in our example) to define an interface: methods for which children must provide an implementation. There are different and better ways to do this, but I want to keep this example as simple as possible.
We also have the Plotter class, which adds the plot method, thereby providing plotting capabilities for any class that inherits from it. Of course, the plot implementation is just a dummy print in this example. The first interesting class is Polygon, which inherits from both Shape and Plotter.
There are many types of polygons, one of which is the regular one, which is both equiangular (all angles are equal) and equilateral (all sides are equal), so we create the RegularPolygon class that inherits from Polygon. Because for a regular polygon, all sides are equal, we can implement a simple __init__ method on RegularPolygon, which takes the length of the side. Finally, we create the RegularHexagon and Square classes, which both inherit from RegularPolygon.
This structure is quite long, but hopefully gives you an idea of how to specialize the classification of your objects when you design the code.
Now, please take a look at the last eight lines. Note that when I call the area method on hexagon and square, I get the correct area for both. This is because they both provide the correct implementation logic for it. Also, I can call get_geometric_type on both of them, even though it is not defined on their classes, and Python has to go all the way up to Shape to find an implementation for it. Note that, even though the implementation is provided in the Shape class, the self.geometric_type used for the return value is correctly taken from the caller instance.
The plot method calls are also interesting, and show you how you can enrich your objects with capabilities they wouldn't otherwise have. This technique is very popular in web frameworks such as Django (which we'll explore in two later chapters), which provides special classes called mixins, whose capabilities you can just use out of the box. All you have to do is to define the desired mixin as one the base classes for your own, and that's it.
Multiple inheritance is powerful, but can also get really messy, so we need to make sure we understand what happens when we use it.
Method resolution order
By now, we know that when you ask for someobject.attribute, and attribute is not found on that object, Python starts searching in the class someobject was created from. If it's not there either, Python searches up the inheritance chain until either attribute is found or the object class is reached. This is quite simple to understand if the inheritance chain is only comprised of single inheritance steps, which means that classes have only one parent. However, when multiple inheritance is involved, there are cases when it's not straightforward to predict what will be the next class that will be searched for if an attribute is not found.
Python provides a way to always know what is the order in which classes are searched on attribute lookup: the method resolution order.
Note
The method resolution order (MRO) is the order in which base classes are searched for a member during lookup. From version 2.3 Python uses an algorithm called C3, which guarantees monotonicity.
In Python 2.2, new-style classes were introduced. The way you write a new-style class in Python 2.* is to define it with an explicit object base class. Classic classes were not explicitly inheriting from object and have been removed in Python 3.
One of the differences between classic and new style-classes in Python 2.* is that new-style classes are searched with the new MRO.
With regards to the previous example, let's see what is the MRO for the Square class:
oop/multiple.inheritance.py
print(square.__class__.__mro__)
# prints:
# (<class '__main__.Square'>, <class '__main__.RegularPolygon'>,
# <class '__main__.Polygon'>, <class '__main__.Shape'>,
# <class '__main__.Plotter'>, <class 'object'>)To get to the MRO of a class, we can go from the instance to its __class__ attribute and from that to its __mro__ attribute. Alternatively, we could have called Square.__mro__, or Square.mro() directly, but if you have to do it dynamically, it's more likely you will have an object in your hands rather than a class.
Note that the only point of doubt is the bisection after Polygon, where the inheritance chain breaks into two ways, one leads to Shape and the other to Plotter. We know by scanning the MRO for the Square class that Shape is searched before Plotter.
Why is this important? Well, imagine the following code:
oop/mro.simple.py
class A:
label = 'a'
class B(A):
label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # Hypothetically this could be either 'b' or 'c'Both B and C inherit from A, and D inherits from both B and C. This means that the lookup for the label attribute can reach the top (A) through both B or C. According to which is reached first, we get a different result.
So, in the preceding example we get 'b', which is what we were expecting, since B is the leftmost one amongst base classes of D. But what happens if I remove the label attribute from B? This would be the confusing situation: Will the algorithm go all the way up to A or will it get to C first? Let's find out!
oop/mro.py
class A:
label = 'a'
class B(A):
pass # was: label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # 'c'
print(d.__class__.mro()) # notice another way to get the MRO
# prints:
# [<class '__main__.D'>, <class '__main__.B'>,
# <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]So, we learn that the MRO is D-B-C-A-(object), which means when we ask for d.label, we get 'c', which is correct.
In day to day programming, it is not quite common to have to deal with the MRO, but the first time you fight against some mixin from a framework, I promise you'll be glad I spent a paragraph explaining it.
Static and class methods
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
Private methods and name mangling
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Initializing an instance
Have you noticed how, before calling p1.final_price(...), we had to assign net_price to p1? There is a better way to do it. In other languages, this would be called a constructor, but in Python, it's not. It is actually an initializer, since it works on an already created instance, and therefore it's called __init__. It's a magic method, which is run right after the object is created. Python objects also have a __new__ method, which is the actual constructor. In practice, it's not so common to have to override it though, it's a practice that is mostly used when coding metaclasses, which is a fairly advanced topic that we won't explore in the book.
oop/class.init.py
class Rectangle():
def __init__(self, sideA, sideB):
self.sideA = sideA
self.sideB = sideB
def area(self):
return self.sideA * self.sideB
r1 = Rectangle(10, 4)
print(r1.sideA, r1.sideB) # 10 4
print(r1.area()) # 40
r2 = Rectangle(7, 3)
print(r2.area()) # 21Things are finally starting to take shape. When an object is created, the __init__ method is automatically run for us. In this case, I coded it so that when we create an object (by calling the class name like a function), we pass arguments to the creation call, like we would on any regular function call. The way we pass parameters follows the signature of the __init__ method, and therefore, in the two creation statements, 10 and 7 will be sideA for r1 and r2 respectively, while 4 and 3 will be sideB. You can see that the call to area() from r1 and r2 reflects that they have different instance arguments.
Setting up objects in this way is much nicer and convenient.
OOP is about code reuse
By now it should be pretty clear: OOP is all about code reuse. We define a class, we create instances, and those instances use methods that are defined only in the class. They will behave differently according to how the instances have been set up by the initializer.
Inheritance and composition
But this is just half of the story, OOP is much more powerful. We have two main design constructs to exploit: inheritance and composition.
Inheritance means that two objects are related by means of an Is-A type of relationship. On the other hand, composition means that two objects are related by means of a Has-A type of relationship. It's all very easy to explain with an example:
oop/class.inheritance.py
class Engine(): def start(self): pass def stop(self): pass class ElectricEngine(Engine): # Is-A Engine pass class V8Engine(Engine): # Is-A Engine pass class Car(): engine_cls = Engine def __init__(self): self.engine = self.engine_cls() # Has-A Engine def start(self): print( 'Starting engine {0} for car {1}... Wroom, wroom!' .format( self.engine.__class__.__name__, self.__class__.__name__) ) self.engine.start() def stop(self): self.engine.stop() class RaceCar(Car): # Is-A Car engine_cls = V8Engine class CityCar(Car): # Is-A Car engine_cls = ElectricEngine class F1Car(RaceCar): # Is-A RaceCar and also Is-A Car engine_cls = V8Engine car = Car() racecar = RaceCar() citycar = CityCar() f1car = F1Car() cars = [car, racecar, citycar, f1car] for car in cars: car.start() """ Prints: Starting engine Engine for car Car... Wroom, wroom! Starting engine V8Engine for car RaceCar... Wroom, wroom! Starting engine ElectricEngine for car CityCar... Wroom, wroom! Starting engine V8Engine for car F1Car... Wroom, wroom! """
The preceding example shows you both the Is-A and Has-A types of relationships between objects. First of all, let's consider Engine. It's a simple class that has two methods, start and stop. We then define ElectricEngine and V8Engine, which both inherit from Engine. You can see that by the fact that when we define them, we put Engine within the braces after the class name.
This means that both ElectricEngine and V8Engine inherit attributes and methods from the Engine class, which is said to be their base class.
The same happens with cars. Car is a base class for both RaceCar and CityCar. RaceCar is also the base class for F1Car. Another way of saying this is that F1Car inherits from RaceCar, which inherits from Car. Therefore, F1Car Is-A RaceCar and RaceCar Is-A Car. Because of the transitive property, we can say that F1Car Is-A Car as well. CityCar too, Is-A Car.
When we define class A(B): pass, we say A is the child of B, and B is the parent of A. parent and base are synonyms, as well as child and derived. Also, we say that a class inherits from another class, or that it extends it.
This is the inheritance mechanism.
On the other hand, let's go back to the code. Each class has a class attribute, engine_cls, which is a reference to the engine class we want to assign to each type of car. Car has a generic Engine, while the two race cars have a powerful V8 engine, and the city car has an electric one.
When a car is created in the initializer method __init__, we create an instance of whatever engine class is assigned to the car, and set it as engine instance attribute.
It makes sense to have engine_cls shared amongst all class instances because it's quite likely that the same instances of a car will have the same kind of engine. On the other hand, it wouldn't be good to have one single engine (an instance of any Engine class) as a class attribute, because we would be sharing one engine amongst all instances, which is incorrect.
The type of relationship between a car and its engine is a Has-A type. A car Has-A engine. This is called composition, and reflects the fact that objects can be made of many other objects. A car Has-A engine, gears, wheels, a frame, doors, seats, and so on.
When designing OOP code, it is of vital importance to describe objects in this way so that we can use inheritance and composition correctly to structure our code in the best way.
Before we leave this paragraph, let's check if I told you the truth with another example:
oop/class.issubclass.isinstance.py
car = Car()
racecar = RaceCar()
f1car = F1Car()
cars = [(car, 'car'), (racecar, 'racecar'), (f1car, 'f1car')]
car_classes = [Car, RaceCar, F1Car]
for car, car_name in cars:
for class_ in car_classes:
belongs = isinstance(car, class_)
msg = 'is a' if belongs else 'is not a'
print(car_name, msg, class_.__name__)
""" Prints:
car is a Car
car is not a RaceCar
car is not a F1Car
racecar is a Car
racecar is a RaceCar
racecar is not a F1Car
f1car is a Car
f1car is a RaceCar
f1car is a F1Car
"""As you can see, car is just an instance of Car, while racecar is an instance of RaceCar (and of Car by extension) and f1car is an instance of F1Car (and of both RaceCar and Car, by extension). A banana is an instance of Banana. But, also, it is a Fruit. Also, it is Food, right? This is the same concept.
To check if an object is an instance of a class, use the isinstance method. It is recommended over sheer type comparison (type(object) == Class).
Let's also check inheritance, same setup, with different for loops:
oop/class.issubclass.isinstance.py
for class1 in car_classes:
for class2 in car_classes:
is_subclass = issubclass(class1, class2)
msg = '{0} a subclass of'.format(
'is' if is_subclass else 'is not')
print(class1.__name__, msg, class2.__name__)
""" Prints:
Car is a subclass of Car
Car is not a subclass of RaceCar
Car is not a subclass of F1Car
RaceCar is a subclass of Car
RaceCar is a subclass of RaceCar
RaceCar is not a subclass of F1Car
F1Car is a subclass of Car
F1Car is a subclass of RaceCar
F1Car is a subclass of F1Car
"""Interestingly, we learn that a class is a subclass of itself. Check the output of the preceding example to see that it matches the explanation I provided.
Note
One thing to notice about conventions is that class names are always written using CapWords, which means ThisWayIsCorrect, as opposed to functions and methods, which are written this_way_is_correct. Also, when in the code you want to use a name which is a Python-reserved keyword or built-in function or class, the convention is to add a trailing underscore to the name. In the first for loop example, I'm looping through the class names using for class_ in ..., because class is a reserved word. But you already knew all this because you have thoroughly studied PEP8, right?
To help you picture the difference between Is-A and Has-A, take a look at the following diagram:
Accessing a base class
We've already seen class declarations like class ClassA: pass and class ClassB(BaseClassName): pass. When we don't specify a base class explicitly, Python will set the special object class as the base class for the one we're defining. Ultimately, all classes derive from object. Note that, if you don't specify a base class, braces are optional.
Therefore, writing class A: pass or class A(): pass or class A(object): pass is exactly the same thing. object is a special class in that it has the methods that are common to all Python classes, and it doesn't allow you to set any attributes on it.
Let's see how we can access a base class from within a class.
oop/super.duplication.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
self.title = title
self.publisher = publisher
self.pages = pages
self.format_ = format_Take a look at the preceding code. I highlighted the part of Ebook initialization that is duplicated from its base class Book. This is quite bad practice because we now have two sets of instructions that are doing the same thing. Moreover, any change in the signature of Book.__init__ will not reflect in Ebook. We know that Ebook Is-A Book, and therefore we would probably want changes to be reflected in the children classes.
Let's see one way to fix this issue:
oop/super.explicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
Book.__init__(self, title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFNow, that's better. We have removed that nasty duplication. Basically, we tell Python to call the __init__ method of the Book class, and we feed self to the call, making sure that we bind that call to the present instance.
If we modify the logic within the __init__ method of Book, we don't need to touch Ebook, it will auto adapt to the change.
This approach is good, but we can still do a bit better. Say that we change Book's name to Liber, because we've fallen in love with Latin. We have to change the __init__ method of Ebook to reflect the change. This can be avoided by using super.
oop/super.implicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
super().__init__(title, publisher, pages)
# Another way to do the same thing is:
# super(Ebook, self).__init__(title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFsuper is a function that returns a proxy object that delegates method calls to a parent or sibling class. In this case, it will delegate that call to __init__ to the Book class, and the beauty of this method is that now we're even free to change Book to Liber without having to touch the logic in the __init__ method of Ebook.
Now that we know how to access a base class from a child, let's explore Python's multiple inheritance.
Multiple inheritance
Apart from composing a class using more than one base class, what is of interest here is how an attribute search is performed. Take a look at the following diagram:
As you can see, Shape and Plotter act as base classes for all the others. Polygon inherits directly from them, RegularPolygon inherits from Polygon, and both RegularHexagon and Square inherit from RegulaPolygon. Note also that Shape and Plotter implicitly inherit from object, therefore we have what is called a diamond or, in simpler terms, more than one path to reach a base class. We'll see why this matters in a few moments. Let's translate it into some simple code:
oop/multiple.inheritance.py
class Shape: geometric_type = 'Generic Shape' def area(self): # This acts as placeholder for the interface raise NotImplementedError def get_geometric_type(self): return self.geometric_type class Plotter: def plot(self, ratio, topleft): # Imagine some nice plotting logic here... print('Plotting at {}, ratio {}.'.format( topleft, ratio)) class Polygon(Shape, Plotter): # base class for polygons geometric_type = 'Polygon' class RegularPolygon(Polygon): # Is-A Polygon geometric_type = 'Regular Polygon' def __init__(self, side): self.side = side class RegularHexagon(RegularPolygon): # Is-A RegularPolygon geometric_type = 'RegularHexagon' def area(self): return 1.5 * (3 ** .5 * self.side ** 2) class Square(RegularPolygon): # Is-A RegularPolygon geometric_type = 'Square' def area(self): return self.side * self.side hexagon = RegularHexagon(10) print(hexagon.area()) # 259.8076211353316 print(hexagon.get_geometric_type()) # RegularHexagon hexagon.plot(0.8, (75, 77)) # Plotting at (75, 77), ratio 0.8. square = Square(12) print(square.area()) # 144 print(square.get_geometric_type()) # Square square.plot(0.93, (74, 75)) # Plotting at (74, 75), ratio 0.93.
Take a look at the preceding code: the class Shape has one attribute, geometric_type, and two methods: area and get_geometric_type. It's quite common to use base classes (like Shape, in our example) to define an interface: methods for which children must provide an implementation. There are different and better ways to do this, but I want to keep this example as simple as possible.
We also have the Plotter class, which adds the plot method, thereby providing plotting capabilities for any class that inherits from it. Of course, the plot implementation is just a dummy print in this example. The first interesting class is Polygon, which inherits from both Shape and Plotter.
There are many types of polygons, one of which is the regular one, which is both equiangular (all angles are equal) and equilateral (all sides are equal), so we create the RegularPolygon class that inherits from Polygon. Because for a regular polygon, all sides are equal, we can implement a simple __init__ method on RegularPolygon, which takes the length of the side. Finally, we create the RegularHexagon and Square classes, which both inherit from RegularPolygon.
This structure is quite long, but hopefully gives you an idea of how to specialize the classification of your objects when you design the code.
Now, please take a look at the last eight lines. Note that when I call the area method on hexagon and square, I get the correct area for both. This is because they both provide the correct implementation logic for it. Also, I can call get_geometric_type on both of them, even though it is not defined on their classes, and Python has to go all the way up to Shape to find an implementation for it. Note that, even though the implementation is provided in the Shape class, the self.geometric_type used for the return value is correctly taken from the caller instance.
The plot method calls are also interesting, and show you how you can enrich your objects with capabilities they wouldn't otherwise have. This technique is very popular in web frameworks such as Django (which we'll explore in two later chapters), which provides special classes called mixins, whose capabilities you can just use out of the box. All you have to do is to define the desired mixin as one the base classes for your own, and that's it.
Multiple inheritance is powerful, but can also get really messy, so we need to make sure we understand what happens when we use it.
Method resolution order
By now, we know that when you ask for someobject.attribute, and attribute is not found on that object, Python starts searching in the class someobject was created from. If it's not there either, Python searches up the inheritance chain until either attribute is found or the object class is reached. This is quite simple to understand if the inheritance chain is only comprised of single inheritance steps, which means that classes have only one parent. However, when multiple inheritance is involved, there are cases when it's not straightforward to predict what will be the next class that will be searched for if an attribute is not found.
Python provides a way to always know what is the order in which classes are searched on attribute lookup: the method resolution order.
Note
The method resolution order (MRO) is the order in which base classes are searched for a member during lookup. From version 2.3 Python uses an algorithm called C3, which guarantees monotonicity.
In Python 2.2, new-style classes were introduced. The way you write a new-style class in Python 2.* is to define it with an explicit object base class. Classic classes were not explicitly inheriting from object and have been removed in Python 3.
One of the differences between classic and new style-classes in Python 2.* is that new-style classes are searched with the new MRO.
With regards to the previous example, let's see what is the MRO for the Square class:
oop/multiple.inheritance.py
print(square.__class__.__mro__)
# prints:
# (<class '__main__.Square'>, <class '__main__.RegularPolygon'>,
# <class '__main__.Polygon'>, <class '__main__.Shape'>,
# <class '__main__.Plotter'>, <class 'object'>)To get to the MRO of a class, we can go from the instance to its __class__ attribute and from that to its __mro__ attribute. Alternatively, we could have called Square.__mro__, or Square.mro() directly, but if you have to do it dynamically, it's more likely you will have an object in your hands rather than a class.
Note that the only point of doubt is the bisection after Polygon, where the inheritance chain breaks into two ways, one leads to Shape and the other to Plotter. We know by scanning the MRO for the Square class that Shape is searched before Plotter.
Why is this important? Well, imagine the following code:
oop/mro.simple.py
class A:
label = 'a'
class B(A):
label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # Hypothetically this could be either 'b' or 'c'Both B and C inherit from A, and D inherits from both B and C. This means that the lookup for the label attribute can reach the top (A) through both B or C. According to which is reached first, we get a different result.
So, in the preceding example we get 'b', which is what we were expecting, since B is the leftmost one amongst base classes of D. But what happens if I remove the label attribute from B? This would be the confusing situation: Will the algorithm go all the way up to A or will it get to C first? Let's find out!
oop/mro.py
class A:
label = 'a'
class B(A):
pass # was: label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # 'c'
print(d.__class__.mro()) # notice another way to get the MRO
# prints:
# [<class '__main__.D'>, <class '__main__.B'>,
# <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]So, we learn that the MRO is D-B-C-A-(object), which means when we ask for d.label, we get 'c', which is correct.
In day to day programming, it is not quite common to have to deal with the MRO, but the first time you fight against some mixin from a framework, I promise you'll be glad I spent a paragraph explaining it.
Static and class methods
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
Private methods and name mangling
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
OOP is about code reuse
By now it should be pretty clear: OOP is all about code reuse. We define a class, we create instances, and those instances use methods that are defined only in the class. They will behave differently according to how the instances have been set up by the initializer.
Inheritance and composition
But this is just half of the story, OOP is much more powerful. We have two main design constructs to exploit: inheritance and composition.
Inheritance means that two objects are related by means of an Is-A type of relationship. On the other hand, composition means that two objects are related by means of a Has-A type of relationship. It's all very easy to explain with an example:
oop/class.inheritance.py
class Engine(): def start(self): pass def stop(self): pass class ElectricEngine(Engine): # Is-A Engine pass class V8Engine(Engine): # Is-A Engine pass class Car(): engine_cls = Engine def __init__(self): self.engine = self.engine_cls() # Has-A Engine def start(self): print( 'Starting engine {0} for car {1}... Wroom, wroom!' .format( self.engine.__class__.__name__, self.__class__.__name__) ) self.engine.start() def stop(self): self.engine.stop() class RaceCar(Car): # Is-A Car engine_cls = V8Engine class CityCar(Car): # Is-A Car engine_cls = ElectricEngine class F1Car(RaceCar): # Is-A RaceCar and also Is-A Car engine_cls = V8Engine car = Car() racecar = RaceCar() citycar = CityCar() f1car = F1Car() cars = [car, racecar, citycar, f1car] for car in cars: car.start() """ Prints: Starting engine Engine for car Car... Wroom, wroom! Starting engine V8Engine for car RaceCar... Wroom, wroom! Starting engine ElectricEngine for car CityCar... Wroom, wroom! Starting engine V8Engine for car F1Car... Wroom, wroom! """
The preceding example shows you both the Is-A and Has-A types of relationships between objects. First of all, let's consider Engine. It's a simple class that has two methods, start and stop. We then define ElectricEngine and V8Engine, which both inherit from Engine. You can see that by the fact that when we define them, we put Engine within the braces after the class name.
This means that both ElectricEngine and V8Engine inherit attributes and methods from the Engine class, which is said to be their base class.
The same happens with cars. Car is a base class for both RaceCar and CityCar. RaceCar is also the base class for F1Car. Another way of saying this is that F1Car inherits from RaceCar, which inherits from Car. Therefore, F1Car Is-A RaceCar and RaceCar Is-A Car. Because of the transitive property, we can say that F1Car Is-A Car as well. CityCar too, Is-A Car.
When we define class A(B): pass, we say A is the child of B, and B is the parent of A. parent and base are synonyms, as well as child and derived. Also, we say that a class inherits from another class, or that it extends it.
This is the inheritance mechanism.
On the other hand, let's go back to the code. Each class has a class attribute, engine_cls, which is a reference to the engine class we want to assign to each type of car. Car has a generic Engine, while the two race cars have a powerful V8 engine, and the city car has an electric one.
When a car is created in the initializer method __init__, we create an instance of whatever engine class is assigned to the car, and set it as engine instance attribute.
It makes sense to have engine_cls shared amongst all class instances because it's quite likely that the same instances of a car will have the same kind of engine. On the other hand, it wouldn't be good to have one single engine (an instance of any Engine class) as a class attribute, because we would be sharing one engine amongst all instances, which is incorrect.
The type of relationship between a car and its engine is a Has-A type. A car Has-A engine. This is called composition, and reflects the fact that objects can be made of many other objects. A car Has-A engine, gears, wheels, a frame, doors, seats, and so on.
When designing OOP code, it is of vital importance to describe objects in this way so that we can use inheritance and composition correctly to structure our code in the best way.
Before we leave this paragraph, let's check if I told you the truth with another example:
oop/class.issubclass.isinstance.py
car = Car()
racecar = RaceCar()
f1car = F1Car()
cars = [(car, 'car'), (racecar, 'racecar'), (f1car, 'f1car')]
car_classes = [Car, RaceCar, F1Car]
for car, car_name in cars:
for class_ in car_classes:
belongs = isinstance(car, class_)
msg = 'is a' if belongs else 'is not a'
print(car_name, msg, class_.__name__)
""" Prints:
car is a Car
car is not a RaceCar
car is not a F1Car
racecar is a Car
racecar is a RaceCar
racecar is not a F1Car
f1car is a Car
f1car is a RaceCar
f1car is a F1Car
"""As you can see, car is just an instance of Car, while racecar is an instance of RaceCar (and of Car by extension) and f1car is an instance of F1Car (and of both RaceCar and Car, by extension). A banana is an instance of Banana. But, also, it is a Fruit. Also, it is Food, right? This is the same concept.
To check if an object is an instance of a class, use the isinstance method. It is recommended over sheer type comparison (type(object) == Class).
Let's also check inheritance, same setup, with different for loops:
oop/class.issubclass.isinstance.py
for class1 in car_classes:
for class2 in car_classes:
is_subclass = issubclass(class1, class2)
msg = '{0} a subclass of'.format(
'is' if is_subclass else 'is not')
print(class1.__name__, msg, class2.__name__)
""" Prints:
Car is a subclass of Car
Car is not a subclass of RaceCar
Car is not a subclass of F1Car
RaceCar is a subclass of Car
RaceCar is a subclass of RaceCar
RaceCar is not a subclass of F1Car
F1Car is a subclass of Car
F1Car is a subclass of RaceCar
F1Car is a subclass of F1Car
"""Interestingly, we learn that a class is a subclass of itself. Check the output of the preceding example to see that it matches the explanation I provided.
Note
One thing to notice about conventions is that class names are always written using CapWords, which means ThisWayIsCorrect, as opposed to functions and methods, which are written this_way_is_correct. Also, when in the code you want to use a name which is a Python-reserved keyword or built-in function or class, the convention is to add a trailing underscore to the name. In the first for loop example, I'm looping through the class names using for class_ in ..., because class is a reserved word. But you already knew all this because you have thoroughly studied PEP8, right?
To help you picture the difference between Is-A and Has-A, take a look at the following diagram:
Accessing a base class
We've already seen class declarations like class ClassA: pass and class ClassB(BaseClassName): pass. When we don't specify a base class explicitly, Python will set the special object class as the base class for the one we're defining. Ultimately, all classes derive from object. Note that, if you don't specify a base class, braces are optional.
Therefore, writing class A: pass or class A(): pass or class A(object): pass is exactly the same thing. object is a special class in that it has the methods that are common to all Python classes, and it doesn't allow you to set any attributes on it.
Let's see how we can access a base class from within a class.
oop/super.duplication.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
self.title = title
self.publisher = publisher
self.pages = pages
self.format_ = format_Take a look at the preceding code. I highlighted the part of Ebook initialization that is duplicated from its base class Book. This is quite bad practice because we now have two sets of instructions that are doing the same thing. Moreover, any change in the signature of Book.__init__ will not reflect in Ebook. We know that Ebook Is-A Book, and therefore we would probably want changes to be reflected in the children classes.
Let's see one way to fix this issue:
oop/super.explicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
Book.__init__(self, title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFNow, that's better. We have removed that nasty duplication. Basically, we tell Python to call the __init__ method of the Book class, and we feed self to the call, making sure that we bind that call to the present instance.
If we modify the logic within the __init__ method of Book, we don't need to touch Ebook, it will auto adapt to the change.
This approach is good, but we can still do a bit better. Say that we change Book's name to Liber, because we've fallen in love with Latin. We have to change the __init__ method of Ebook to reflect the change. This can be avoided by using super.
oop/super.implicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
super().__init__(title, publisher, pages)
# Another way to do the same thing is:
# super(Ebook, self).__init__(title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFsuper is a function that returns a proxy object that delegates method calls to a parent or sibling class. In this case, it will delegate that call to __init__ to the Book class, and the beauty of this method is that now we're even free to change Book to Liber without having to touch the logic in the __init__ method of Ebook.
Now that we know how to access a base class from a child, let's explore Python's multiple inheritance.
Multiple inheritance
Apart from composing a class using more than one base class, what is of interest here is how an attribute search is performed. Take a look at the following diagram:
As you can see, Shape and Plotter act as base classes for all the others. Polygon inherits directly from them, RegularPolygon inherits from Polygon, and both RegularHexagon and Square inherit from RegulaPolygon. Note also that Shape and Plotter implicitly inherit from object, therefore we have what is called a diamond or, in simpler terms, more than one path to reach a base class. We'll see why this matters in a few moments. Let's translate it into some simple code:
oop/multiple.inheritance.py
class Shape: geometric_type = 'Generic Shape' def area(self): # This acts as placeholder for the interface raise NotImplementedError def get_geometric_type(self): return self.geometric_type class Plotter: def plot(self, ratio, topleft): # Imagine some nice plotting logic here... print('Plotting at {}, ratio {}.'.format( topleft, ratio)) class Polygon(Shape, Plotter): # base class for polygons geometric_type = 'Polygon' class RegularPolygon(Polygon): # Is-A Polygon geometric_type = 'Regular Polygon' def __init__(self, side): self.side = side class RegularHexagon(RegularPolygon): # Is-A RegularPolygon geometric_type = 'RegularHexagon' def area(self): return 1.5 * (3 ** .5 * self.side ** 2) class Square(RegularPolygon): # Is-A RegularPolygon geometric_type = 'Square' def area(self): return self.side * self.side hexagon = RegularHexagon(10) print(hexagon.area()) # 259.8076211353316 print(hexagon.get_geometric_type()) # RegularHexagon hexagon.plot(0.8, (75, 77)) # Plotting at (75, 77), ratio 0.8. square = Square(12) print(square.area()) # 144 print(square.get_geometric_type()) # Square square.plot(0.93, (74, 75)) # Plotting at (74, 75), ratio 0.93.
Take a look at the preceding code: the class Shape has one attribute, geometric_type, and two methods: area and get_geometric_type. It's quite common to use base classes (like Shape, in our example) to define an interface: methods for which children must provide an implementation. There are different and better ways to do this, but I want to keep this example as simple as possible.
We also have the Plotter class, which adds the plot method, thereby providing plotting capabilities for any class that inherits from it. Of course, the plot implementation is just a dummy print in this example. The first interesting class is Polygon, which inherits from both Shape and Plotter.
There are many types of polygons, one of which is the regular one, which is both equiangular (all angles are equal) and equilateral (all sides are equal), so we create the RegularPolygon class that inherits from Polygon. Because for a regular polygon, all sides are equal, we can implement a simple __init__ method on RegularPolygon, which takes the length of the side. Finally, we create the RegularHexagon and Square classes, which both inherit from RegularPolygon.
This structure is quite long, but hopefully gives you an idea of how to specialize the classification of your objects when you design the code.
Now, please take a look at the last eight lines. Note that when I call the area method on hexagon and square, I get the correct area for both. This is because they both provide the correct implementation logic for it. Also, I can call get_geometric_type on both of them, even though it is not defined on their classes, and Python has to go all the way up to Shape to find an implementation for it. Note that, even though the implementation is provided in the Shape class, the self.geometric_type used for the return value is correctly taken from the caller instance.
The plot method calls are also interesting, and show you how you can enrich your objects with capabilities they wouldn't otherwise have. This technique is very popular in web frameworks such as Django (which we'll explore in two later chapters), which provides special classes called mixins, whose capabilities you can just use out of the box. All you have to do is to define the desired mixin as one the base classes for your own, and that's it.
Multiple inheritance is powerful, but can also get really messy, so we need to make sure we understand what happens when we use it.
Method resolution order
By now, we know that when you ask for someobject.attribute, and attribute is not found on that object, Python starts searching in the class someobject was created from. If it's not there either, Python searches up the inheritance chain until either attribute is found or the object class is reached. This is quite simple to understand if the inheritance chain is only comprised of single inheritance steps, which means that classes have only one parent. However, when multiple inheritance is involved, there are cases when it's not straightforward to predict what will be the next class that will be searched for if an attribute is not found.
Python provides a way to always know what is the order in which classes are searched on attribute lookup: the method resolution order.
Note
The method resolution order (MRO) is the order in which base classes are searched for a member during lookup. From version 2.3 Python uses an algorithm called C3, which guarantees monotonicity.
In Python 2.2, new-style classes were introduced. The way you write a new-style class in Python 2.* is to define it with an explicit object base class. Classic classes were not explicitly inheriting from object and have been removed in Python 3.
One of the differences between classic and new style-classes in Python 2.* is that new-style classes are searched with the new MRO.
With regards to the previous example, let's see what is the MRO for the Square class:
oop/multiple.inheritance.py
print(square.__class__.__mro__)
# prints:
# (<class '__main__.Square'>, <class '__main__.RegularPolygon'>,
# <class '__main__.Polygon'>, <class '__main__.Shape'>,
# <class '__main__.Plotter'>, <class 'object'>)To get to the MRO of a class, we can go from the instance to its __class__ attribute and from that to its __mro__ attribute. Alternatively, we could have called Square.__mro__, or Square.mro() directly, but if you have to do it dynamically, it's more likely you will have an object in your hands rather than a class.
Note that the only point of doubt is the bisection after Polygon, where the inheritance chain breaks into two ways, one leads to Shape and the other to Plotter. We know by scanning the MRO for the Square class that Shape is searched before Plotter.
Why is this important? Well, imagine the following code:
oop/mro.simple.py
class A:
label = 'a'
class B(A):
label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # Hypothetically this could be either 'b' or 'c'Both B and C inherit from A, and D inherits from both B and C. This means that the lookup for the label attribute can reach the top (A) through both B or C. According to which is reached first, we get a different result.
So, in the preceding example we get 'b', which is what we were expecting, since B is the leftmost one amongst base classes of D. But what happens if I remove the label attribute from B? This would be the confusing situation: Will the algorithm go all the way up to A or will it get to C first? Let's find out!
oop/mro.py
class A:
label = 'a'
class B(A):
pass # was: label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # 'c'
print(d.__class__.mro()) # notice another way to get the MRO
# prints:
# [<class '__main__.D'>, <class '__main__.B'>,
# <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]So, we learn that the MRO is D-B-C-A-(object), which means when we ask for d.label, we get 'c', which is correct.
In day to day programming, it is not quite common to have to deal with the MRO, but the first time you fight against some mixin from a framework, I promise you'll be glad I spent a paragraph explaining it.
Static and class methods
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
Private methods and name mangling
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Inheritance and composition
But this is just half of the story, OOP is much more powerful. We have two main design constructs to exploit: inheritance and composition.
Inheritance means that two objects are related by means of an Is-A type of relationship. On the other hand, composition means that two objects are related by means of a Has-A type of relationship. It's all very easy to explain with an example:
oop/class.inheritance.py
class Engine(): def start(self): pass def stop(self): pass class ElectricEngine(Engine): # Is-A Engine pass class V8Engine(Engine): # Is-A Engine pass class Car(): engine_cls = Engine def __init__(self): self.engine = self.engine_cls() # Has-A Engine def start(self): print( 'Starting engine {0} for car {1}... Wroom, wroom!' .format( self.engine.__class__.__name__, self.__class__.__name__) ) self.engine.start() def stop(self): self.engine.stop() class RaceCar(Car): # Is-A Car engine_cls = V8Engine class CityCar(Car): # Is-A Car engine_cls = ElectricEngine class F1Car(RaceCar): # Is-A RaceCar and also Is-A Car engine_cls = V8Engine car = Car() racecar = RaceCar() citycar = CityCar() f1car = F1Car() cars = [car, racecar, citycar, f1car] for car in cars: car.start() """ Prints: Starting engine Engine for car Car... Wroom, wroom! Starting engine V8Engine for car RaceCar... Wroom, wroom! Starting engine ElectricEngine for car CityCar... Wroom, wroom! Starting engine V8Engine for car F1Car... Wroom, wroom! """
The preceding example shows you both the Is-A and Has-A types of relationships between objects. First of all, let's consider Engine. It's a simple class that has two methods, start and stop. We then define ElectricEngine and V8Engine, which both inherit from Engine. You can see that by the fact that when we define them, we put Engine within the braces after the class name.
This means that both ElectricEngine and V8Engine inherit attributes and methods from the Engine class, which is said to be their base class.
The same happens with cars. Car is a base class for both RaceCar and CityCar. RaceCar is also the base class for F1Car. Another way of saying this is that F1Car inherits from RaceCar, which inherits from Car. Therefore, F1Car Is-A RaceCar and RaceCar Is-A Car. Because of the transitive property, we can say that F1Car Is-A Car as well. CityCar too, Is-A Car.
When we define class A(B): pass, we say A is the child of B, and B is the parent of A. parent and base are synonyms, as well as child and derived. Also, we say that a class inherits from another class, or that it extends it.
This is the inheritance mechanism.
On the other hand, let's go back to the code. Each class has a class attribute, engine_cls, which is a reference to the engine class we want to assign to each type of car. Car has a generic Engine, while the two race cars have a powerful V8 engine, and the city car has an electric one.
When a car is created in the initializer method __init__, we create an instance of whatever engine class is assigned to the car, and set it as engine instance attribute.
It makes sense to have engine_cls shared amongst all class instances because it's quite likely that the same instances of a car will have the same kind of engine. On the other hand, it wouldn't be good to have one single engine (an instance of any Engine class) as a class attribute, because we would be sharing one engine amongst all instances, which is incorrect.
The type of relationship between a car and its engine is a Has-A type. A car Has-A engine. This is called composition, and reflects the fact that objects can be made of many other objects. A car Has-A engine, gears, wheels, a frame, doors, seats, and so on.
When designing OOP code, it is of vital importance to describe objects in this way so that we can use inheritance and composition correctly to structure our code in the best way.
Before we leave this paragraph, let's check if I told you the truth with another example:
oop/class.issubclass.isinstance.py
car = Car()
racecar = RaceCar()
f1car = F1Car()
cars = [(car, 'car'), (racecar, 'racecar'), (f1car, 'f1car')]
car_classes = [Car, RaceCar, F1Car]
for car, car_name in cars:
for class_ in car_classes:
belongs = isinstance(car, class_)
msg = 'is a' if belongs else 'is not a'
print(car_name, msg, class_.__name__)
""" Prints:
car is a Car
car is not a RaceCar
car is not a F1Car
racecar is a Car
racecar is a RaceCar
racecar is not a F1Car
f1car is a Car
f1car is a RaceCar
f1car is a F1Car
"""As you can see, car is just an instance of Car, while racecar is an instance of RaceCar (and of Car by extension) and f1car is an instance of F1Car (and of both RaceCar and Car, by extension). A banana is an instance of Banana. But, also, it is a Fruit. Also, it is Food, right? This is the same concept.
To check if an object is an instance of a class, use the isinstance method. It is recommended over sheer type comparison (type(object) == Class).
Let's also check inheritance, same setup, with different for loops:
oop/class.issubclass.isinstance.py
for class1 in car_classes:
for class2 in car_classes:
is_subclass = issubclass(class1, class2)
msg = '{0} a subclass of'.format(
'is' if is_subclass else 'is not')
print(class1.__name__, msg, class2.__name__)
""" Prints:
Car is a subclass of Car
Car is not a subclass of RaceCar
Car is not a subclass of F1Car
RaceCar is a subclass of Car
RaceCar is a subclass of RaceCar
RaceCar is not a subclass of F1Car
F1Car is a subclass of Car
F1Car is a subclass of RaceCar
F1Car is a subclass of F1Car
"""Interestingly, we learn that a class is a subclass of itself. Check the output of the preceding example to see that it matches the explanation I provided.
Note
One thing to notice about conventions is that class names are always written using CapWords, which means ThisWayIsCorrect, as opposed to functions and methods, which are written this_way_is_correct. Also, when in the code you want to use a name which is a Python-reserved keyword or built-in function or class, the convention is to add a trailing underscore to the name. In the first for loop example, I'm looping through the class names using for class_ in ..., because class is a reserved word. But you already knew all this because you have thoroughly studied PEP8, right?
To help you picture the difference between Is-A and Has-A, take a look at the following diagram:
We've already seen class declarations like class ClassA: pass and class ClassB(BaseClassName): pass. When we don't specify a base class explicitly, Python will set the special object class as the base class for the one we're defining. Ultimately, all classes derive from object. Note that, if you don't specify a base class, braces are optional.
Therefore, writing class A: pass or class A(): pass or class A(object): pass is exactly the same thing. object is a special class in that it has the methods that are common to all Python classes, and it doesn't allow you to set any attributes on it.
Let's see how we can access a base class from within a class.
oop/super.duplication.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
self.title = title
self.publisher = publisher
self.pages = pages
self.format_ = format_Take a look at the preceding code. I highlighted the part of Ebook initialization that is duplicated from its base class Book. This is quite bad practice because we now have two sets of instructions that are doing the same thing. Moreover, any change in the signature of Book.__init__ will not reflect in Ebook. We know that Ebook Is-A Book, and therefore we would probably want changes to be reflected in the children classes.
Let's see one way to fix this issue:
oop/super.explicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
Book.__init__(self, title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFNow, that's better. We have removed that nasty duplication. Basically, we tell Python to call the __init__ method of the Book class, and we feed self to the call, making sure that we bind that call to the present instance.
If we modify the logic within the __init__ method of Book, we don't need to touch Ebook, it will auto adapt to the change.
This approach is good, but we can still do a bit better. Say that we change Book's name to Liber, because we've fallen in love with Latin. We have to change the __init__ method of Ebook to reflect the change. This can be avoided by using super.
oop/super.implicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
super().__init__(title, publisher, pages)
# Another way to do the same thing is:
# super(Ebook, self).__init__(title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFsuper is a function that returns a proxy object that delegates method calls to a parent or sibling class. In this case, it will delegate that call to __init__ to the Book class, and the beauty of this method is that now we're even free to change Book to Liber without having to touch the logic in the __init__ method of Ebook.
Now that we know how to access a base class from a child, let's explore Python's multiple inheritance.
Apart from composing a class using more than one base class, what is of interest here is how an attribute search is performed. Take a look at the following diagram:
As you can see, Shape and Plotter act as base classes for all the others. Polygon inherits directly from them, RegularPolygon inherits from Polygon, and both RegularHexagon and Square inherit from RegulaPolygon. Note also that Shape and Plotter implicitly inherit from object, therefore we have what is called a diamond or, in simpler terms, more than one path to reach a base class. We'll see why this matters in a few moments. Let's translate it into some simple code:
oop/multiple.inheritance.py
class Shape: geometric_type = 'Generic Shape' def area(self): # This acts as placeholder for the interface raise NotImplementedError def get_geometric_type(self): return self.geometric_type class Plotter: def plot(self, ratio, topleft): # Imagine some nice plotting logic here... print('Plotting at {}, ratio {}.'.format( topleft, ratio)) class Polygon(Shape, Plotter): # base class for polygons geometric_type = 'Polygon' class RegularPolygon(Polygon): # Is-A Polygon geometric_type = 'Regular Polygon' def __init__(self, side): self.side = side class RegularHexagon(RegularPolygon): # Is-A RegularPolygon geometric_type = 'RegularHexagon' def area(self): return 1.5 * (3 ** .5 * self.side ** 2) class Square(RegularPolygon): # Is-A RegularPolygon geometric_type = 'Square' def area(self): return self.side * self.side hexagon = RegularHexagon(10) print(hexagon.area()) # 259.8076211353316 print(hexagon.get_geometric_type()) # RegularHexagon hexagon.plot(0.8, (75, 77)) # Plotting at (75, 77), ratio 0.8. square = Square(12) print(square.area()) # 144 print(square.get_geometric_type()) # Square square.plot(0.93, (74, 75)) # Plotting at (74, 75), ratio 0.93.
Take a look at the preceding code: the class Shape has one attribute, geometric_type, and two methods: area and get_geometric_type. It's quite common to use base classes (like Shape, in our example) to define an interface: methods for which children must provide an implementation. There are different and better ways to do this, but I want to keep this example as simple as possible.
We also have the Plotter class, which adds the plot method, thereby providing plotting capabilities for any class that inherits from it. Of course, the plot implementation is just a dummy print in this example. The first interesting class is Polygon, which inherits from both Shape and Plotter.
There are many types of polygons, one of which is the regular one, which is both equiangular (all angles are equal) and equilateral (all sides are equal), so we create the RegularPolygon class that inherits from Polygon. Because for a regular polygon, all sides are equal, we can implement a simple __init__ method on RegularPolygon, which takes the length of the side. Finally, we create the RegularHexagon and Square classes, which both inherit from RegularPolygon.
This structure is quite long, but hopefully gives you an idea of how to specialize the classification of your objects when you design the code.
Now, please take a look at the last eight lines. Note that when I call the area method on hexagon and square, I get the correct area for both. This is because they both provide the correct implementation logic for it. Also, I can call get_geometric_type on both of them, even though it is not defined on their classes, and Python has to go all the way up to Shape to find an implementation for it. Note that, even though the implementation is provided in the Shape class, the self.geometric_type used for the return value is correctly taken from the caller instance.
The plot method calls are also interesting, and show you how you can enrich your objects with capabilities they wouldn't otherwise have. This technique is very popular in web frameworks such as Django (which we'll explore in two later chapters), which provides special classes called mixins, whose capabilities you can just use out of the box. All you have to do is to define the desired mixin as one the base classes for your own, and that's it.
Multiple inheritance is powerful, but can also get really messy, so we need to make sure we understand what happens when we use it.
Method resolution order
By now, we know that when you ask for someobject.attribute, and attribute is not found on that object, Python starts searching in the class someobject was created from. If it's not there either, Python searches up the inheritance chain until either attribute is found or the object class is reached. This is quite simple to understand if the inheritance chain is only comprised of single inheritance steps, which means that classes have only one parent. However, when multiple inheritance is involved, there are cases when it's not straightforward to predict what will be the next class that will be searched for if an attribute is not found.
Python provides a way to always know what is the order in which classes are searched on attribute lookup: the method resolution order.
Note
The method resolution order (MRO) is the order in which base classes are searched for a member during lookup. From version 2.3 Python uses an algorithm called C3, which guarantees monotonicity.
In Python 2.2, new-style classes were introduced. The way you write a new-style class in Python 2.* is to define it with an explicit object base class. Classic classes were not explicitly inheriting from object and have been removed in Python 3.
One of the differences between classic and new style-classes in Python 2.* is that new-style classes are searched with the new MRO.
With regards to the previous example, let's see what is the MRO for the Square class:
oop/multiple.inheritance.py
print(square.__class__.__mro__)
# prints:
# (<class '__main__.Square'>, <class '__main__.RegularPolygon'>,
# <class '__main__.Polygon'>, <class '__main__.Shape'>,
# <class '__main__.Plotter'>, <class 'object'>)To get to the MRO of a class, we can go from the instance to its __class__ attribute and from that to its __mro__ attribute. Alternatively, we could have called Square.__mro__, or Square.mro() directly, but if you have to do it dynamically, it's more likely you will have an object in your hands rather than a class.
Note that the only point of doubt is the bisection after Polygon, where the inheritance chain breaks into two ways, one leads to Shape and the other to Plotter. We know by scanning the MRO for the Square class that Shape is searched before Plotter.
Why is this important? Well, imagine the following code:
oop/mro.simple.py
class A:
label = 'a'
class B(A):
label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # Hypothetically this could be either 'b' or 'c'Both B and C inherit from A, and D inherits from both B and C. This means that the lookup for the label attribute can reach the top (A) through both B or C. According to which is reached first, we get a different result.
So, in the preceding example we get 'b', which is what we were expecting, since B is the leftmost one amongst base classes of D. But what happens if I remove the label attribute from B? This would be the confusing situation: Will the algorithm go all the way up to A or will it get to C first? Let's find out!
oop/mro.py
class A:
label = 'a'
class B(A):
pass # was: label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # 'c'
print(d.__class__.mro()) # notice another way to get the MRO
# prints:
# [<class '__main__.D'>, <class '__main__.B'>,
# <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]So, we learn that the MRO is D-B-C-A-(object), which means when we ask for d.label, we get 'c', which is correct.
In day to day programming, it is not quite common to have to deal with the MRO, but the first time you fight against some mixin from a framework, I promise you'll be glad I spent a paragraph explaining it.
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Accessing a base class
We've already seen class declarations like class ClassA: pass and class ClassB(BaseClassName): pass. When we don't specify a base class explicitly, Python will set the special object class as the base class for the one we're defining. Ultimately, all classes derive from object. Note that, if you don't specify a base class, braces are optional.
Therefore, writing class A: pass or class A(): pass or class A(object): pass is exactly the same thing. object is a special class in that it has the methods that are common to all Python classes, and it doesn't allow you to set any attributes on it.
Let's see how we can access a base class from within a class.
oop/super.duplication.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
self.title = title
self.publisher = publisher
self.pages = pages
self.format_ = format_Take a look at the preceding code. I highlighted the part of Ebook initialization that is duplicated from its base class Book. This is quite bad practice because we now have two sets of instructions that are doing the same thing. Moreover, any change in the signature of Book.__init__ will not reflect in Ebook. We know that Ebook Is-A Book, and therefore we would probably want changes to be reflected in the children classes.
Let's see one way to fix this issue:
oop/super.explicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
Book.__init__(self, title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFNow, that's better. We have removed that nasty duplication. Basically, we tell Python to call the __init__ method of the Book class, and we feed self to the call, making sure that we bind that call to the present instance.
If we modify the logic within the __init__ method of Book, we don't need to touch Ebook, it will auto adapt to the change.
This approach is good, but we can still do a bit better. Say that we change Book's name to Liber, because we've fallen in love with Latin. We have to change the __init__ method of Ebook to reflect the change. This can be avoided by using super.
oop/super.implicit.py
class Book:
def __init__(self, title, publisher, pages):
self.title = title
self.publisher = publisher
self.pages = pages
class Ebook(Book):
def __init__(self, title, publisher, pages, format_):
super().__init__(title, publisher, pages)
# Another way to do the same thing is:
# super(Ebook, self).__init__(title, publisher, pages)
self.format_ = format_
ebook = Ebook('Learning Python', 'Packt Publishing', 360, 'PDF')
print(ebook.title) # Learning Python
print(ebook.publisher) # Packt Publishing
print(ebook.pages) # 360
print(ebook.format_) # PDFsuper is a function that returns a proxy object that delegates method calls to a parent or sibling class. In this case, it will delegate that call to __init__ to the Book class, and the beauty of this method is that now we're even free to change Book to Liber without having to touch the logic in the __init__ method of Ebook.
Now that we know how to access a base class from a child, let's explore Python's multiple inheritance.
Multiple inheritance
Apart from composing a class using more than one base class, what is of interest here is how an attribute search is performed. Take a look at the following diagram:
As you can see, Shape and Plotter act as base classes for all the others. Polygon inherits directly from them, RegularPolygon inherits from Polygon, and both RegularHexagon and Square inherit from RegulaPolygon. Note also that Shape and Plotter implicitly inherit from object, therefore we have what is called a diamond or, in simpler terms, more than one path to reach a base class. We'll see why this matters in a few moments. Let's translate it into some simple code:
oop/multiple.inheritance.py
class Shape: geometric_type = 'Generic Shape' def area(self): # This acts as placeholder for the interface raise NotImplementedError def get_geometric_type(self): return self.geometric_type class Plotter: def plot(self, ratio, topleft): # Imagine some nice plotting logic here... print('Plotting at {}, ratio {}.'.format( topleft, ratio)) class Polygon(Shape, Plotter): # base class for polygons geometric_type = 'Polygon' class RegularPolygon(Polygon): # Is-A Polygon geometric_type = 'Regular Polygon' def __init__(self, side): self.side = side class RegularHexagon(RegularPolygon): # Is-A RegularPolygon geometric_type = 'RegularHexagon' def area(self): return 1.5 * (3 ** .5 * self.side ** 2) class Square(RegularPolygon): # Is-A RegularPolygon geometric_type = 'Square' def area(self): return self.side * self.side hexagon = RegularHexagon(10) print(hexagon.area()) # 259.8076211353316 print(hexagon.get_geometric_type()) # RegularHexagon hexagon.plot(0.8, (75, 77)) # Plotting at (75, 77), ratio 0.8. square = Square(12) print(square.area()) # 144 print(square.get_geometric_type()) # Square square.plot(0.93, (74, 75)) # Plotting at (74, 75), ratio 0.93.
Take a look at the preceding code: the class Shape has one attribute, geometric_type, and two methods: area and get_geometric_type. It's quite common to use base classes (like Shape, in our example) to define an interface: methods for which children must provide an implementation. There are different and better ways to do this, but I want to keep this example as simple as possible.
We also have the Plotter class, which adds the plot method, thereby providing plotting capabilities for any class that inherits from it. Of course, the plot implementation is just a dummy print in this example. The first interesting class is Polygon, which inherits from both Shape and Plotter.
There are many types of polygons, one of which is the regular one, which is both equiangular (all angles are equal) and equilateral (all sides are equal), so we create the RegularPolygon class that inherits from Polygon. Because for a regular polygon, all sides are equal, we can implement a simple __init__ method on RegularPolygon, which takes the length of the side. Finally, we create the RegularHexagon and Square classes, which both inherit from RegularPolygon.
This structure is quite long, but hopefully gives you an idea of how to specialize the classification of your objects when you design the code.
Now, please take a look at the last eight lines. Note that when I call the area method on hexagon and square, I get the correct area for both. This is because they both provide the correct implementation logic for it. Also, I can call get_geometric_type on both of them, even though it is not defined on their classes, and Python has to go all the way up to Shape to find an implementation for it. Note that, even though the implementation is provided in the Shape class, the self.geometric_type used for the return value is correctly taken from the caller instance.
The plot method calls are also interesting, and show you how you can enrich your objects with capabilities they wouldn't otherwise have. This technique is very popular in web frameworks such as Django (which we'll explore in two later chapters), which provides special classes called mixins, whose capabilities you can just use out of the box. All you have to do is to define the desired mixin as one the base classes for your own, and that's it.
Multiple inheritance is powerful, but can also get really messy, so we need to make sure we understand what happens when we use it.
Method resolution order
By now, we know that when you ask for someobject.attribute, and attribute is not found on that object, Python starts searching in the class someobject was created from. If it's not there either, Python searches up the inheritance chain until either attribute is found or the object class is reached. This is quite simple to understand if the inheritance chain is only comprised of single inheritance steps, which means that classes have only one parent. However, when multiple inheritance is involved, there are cases when it's not straightforward to predict what will be the next class that will be searched for if an attribute is not found.
Python provides a way to always know what is the order in which classes are searched on attribute lookup: the method resolution order.
Note
The method resolution order (MRO) is the order in which base classes are searched for a member during lookup. From version 2.3 Python uses an algorithm called C3, which guarantees monotonicity.
In Python 2.2, new-style classes were introduced. The way you write a new-style class in Python 2.* is to define it with an explicit object base class. Classic classes were not explicitly inheriting from object and have been removed in Python 3.
One of the differences between classic and new style-classes in Python 2.* is that new-style classes are searched with the new MRO.
With regards to the previous example, let's see what is the MRO for the Square class:
oop/multiple.inheritance.py
print(square.__class__.__mro__)
# prints:
# (<class '__main__.Square'>, <class '__main__.RegularPolygon'>,
# <class '__main__.Polygon'>, <class '__main__.Shape'>,
# <class '__main__.Plotter'>, <class 'object'>)To get to the MRO of a class, we can go from the instance to its __class__ attribute and from that to its __mro__ attribute. Alternatively, we could have called Square.__mro__, or Square.mro() directly, but if you have to do it dynamically, it's more likely you will have an object in your hands rather than a class.
Note that the only point of doubt is the bisection after Polygon, where the inheritance chain breaks into two ways, one leads to Shape and the other to Plotter. We know by scanning the MRO for the Square class that Shape is searched before Plotter.
Why is this important? Well, imagine the following code:
oop/mro.simple.py
class A:
label = 'a'
class B(A):
label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # Hypothetically this could be either 'b' or 'c'Both B and C inherit from A, and D inherits from both B and C. This means that the lookup for the label attribute can reach the top (A) through both B or C. According to which is reached first, we get a different result.
So, in the preceding example we get 'b', which is what we were expecting, since B is the leftmost one amongst base classes of D. But what happens if I remove the label attribute from B? This would be the confusing situation: Will the algorithm go all the way up to A or will it get to C first? Let's find out!
oop/mro.py
class A:
label = 'a'
class B(A):
pass # was: label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # 'c'
print(d.__class__.mro()) # notice another way to get the MRO
# prints:
# [<class '__main__.D'>, <class '__main__.B'>,
# <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]So, we learn that the MRO is D-B-C-A-(object), which means when we ask for d.label, we get 'c', which is correct.
In day to day programming, it is not quite common to have to deal with the MRO, but the first time you fight against some mixin from a framework, I promise you'll be glad I spent a paragraph explaining it.
Static and class methods
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
Private methods and name mangling
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Multiple inheritance
Apart from composing a class using more than one base class, what is of interest here is how an attribute search is performed. Take a look at the following diagram:
As you can see, Shape and Plotter act as base classes for all the others. Polygon inherits directly from them, RegularPolygon inherits from Polygon, and both RegularHexagon and Square inherit from RegulaPolygon. Note also that Shape and Plotter implicitly inherit from object, therefore we have what is called a diamond or, in simpler terms, more than one path to reach a base class. We'll see why this matters in a few moments. Let's translate it into some simple code:
oop/multiple.inheritance.py
class Shape: geometric_type = 'Generic Shape' def area(self): # This acts as placeholder for the interface raise NotImplementedError def get_geometric_type(self): return self.geometric_type class Plotter: def plot(self, ratio, topleft): # Imagine some nice plotting logic here... print('Plotting at {}, ratio {}.'.format( topleft, ratio)) class Polygon(Shape, Plotter): # base class for polygons geometric_type = 'Polygon' class RegularPolygon(Polygon): # Is-A Polygon geometric_type = 'Regular Polygon' def __init__(self, side): self.side = side class RegularHexagon(RegularPolygon): # Is-A RegularPolygon geometric_type = 'RegularHexagon' def area(self): return 1.5 * (3 ** .5 * self.side ** 2) class Square(RegularPolygon): # Is-A RegularPolygon geometric_type = 'Square' def area(self): return self.side * self.side hexagon = RegularHexagon(10) print(hexagon.area()) # 259.8076211353316 print(hexagon.get_geometric_type()) # RegularHexagon hexagon.plot(0.8, (75, 77)) # Plotting at (75, 77), ratio 0.8. square = Square(12) print(square.area()) # 144 print(square.get_geometric_type()) # Square square.plot(0.93, (74, 75)) # Plotting at (74, 75), ratio 0.93.
Take a look at the preceding code: the class Shape has one attribute, geometric_type, and two methods: area and get_geometric_type. It's quite common to use base classes (like Shape, in our example) to define an interface: methods for which children must provide an implementation. There are different and better ways to do this, but I want to keep this example as simple as possible.
We also have the Plotter class, which adds the plot method, thereby providing plotting capabilities for any class that inherits from it. Of course, the plot implementation is just a dummy print in this example. The first interesting class is Polygon, which inherits from both Shape and Plotter.
There are many types of polygons, one of which is the regular one, which is both equiangular (all angles are equal) and equilateral (all sides are equal), so we create the RegularPolygon class that inherits from Polygon. Because for a regular polygon, all sides are equal, we can implement a simple __init__ method on RegularPolygon, which takes the length of the side. Finally, we create the RegularHexagon and Square classes, which both inherit from RegularPolygon.
This structure is quite long, but hopefully gives you an idea of how to specialize the classification of your objects when you design the code.
Now, please take a look at the last eight lines. Note that when I call the area method on hexagon and square, I get the correct area for both. This is because they both provide the correct implementation logic for it. Also, I can call get_geometric_type on both of them, even though it is not defined on their classes, and Python has to go all the way up to Shape to find an implementation for it. Note that, even though the implementation is provided in the Shape class, the self.geometric_type used for the return value is correctly taken from the caller instance.
The plot method calls are also interesting, and show you how you can enrich your objects with capabilities they wouldn't otherwise have. This technique is very popular in web frameworks such as Django (which we'll explore in two later chapters), which provides special classes called mixins, whose capabilities you can just use out of the box. All you have to do is to define the desired mixin as one the base classes for your own, and that's it.
Multiple inheritance is powerful, but can also get really messy, so we need to make sure we understand what happens when we use it.
Method resolution order
By now, we know that when you ask for someobject.attribute, and attribute is not found on that object, Python starts searching in the class someobject was created from. If it's not there either, Python searches up the inheritance chain until either attribute is found or the object class is reached. This is quite simple to understand if the inheritance chain is only comprised of single inheritance steps, which means that classes have only one parent. However, when multiple inheritance is involved, there are cases when it's not straightforward to predict what will be the next class that will be searched for if an attribute is not found.
Python provides a way to always know what is the order in which classes are searched on attribute lookup: the method resolution order.
Note
The method resolution order (MRO) is the order in which base classes are searched for a member during lookup. From version 2.3 Python uses an algorithm called C3, which guarantees monotonicity.
In Python 2.2, new-style classes were introduced. The way you write a new-style class in Python 2.* is to define it with an explicit object base class. Classic classes were not explicitly inheriting from object and have been removed in Python 3.
One of the differences between classic and new style-classes in Python 2.* is that new-style classes are searched with the new MRO.
With regards to the previous example, let's see what is the MRO for the Square class:
oop/multiple.inheritance.py
print(square.__class__.__mro__)
# prints:
# (<class '__main__.Square'>, <class '__main__.RegularPolygon'>,
# <class '__main__.Polygon'>, <class '__main__.Shape'>,
# <class '__main__.Plotter'>, <class 'object'>)To get to the MRO of a class, we can go from the instance to its __class__ attribute and from that to its __mro__ attribute. Alternatively, we could have called Square.__mro__, or Square.mro() directly, but if you have to do it dynamically, it's more likely you will have an object in your hands rather than a class.
Note that the only point of doubt is the bisection after Polygon, where the inheritance chain breaks into two ways, one leads to Shape and the other to Plotter. We know by scanning the MRO for the Square class that Shape is searched before Plotter.
Why is this important? Well, imagine the following code:
oop/mro.simple.py
class A:
label = 'a'
class B(A):
label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # Hypothetically this could be either 'b' or 'c'Both B and C inherit from A, and D inherits from both B and C. This means that the lookup for the label attribute can reach the top (A) through both B or C. According to which is reached first, we get a different result.
So, in the preceding example we get 'b', which is what we were expecting, since B is the leftmost one amongst base classes of D. But what happens if I remove the label attribute from B? This would be the confusing situation: Will the algorithm go all the way up to A or will it get to C first? Let's find out!
oop/mro.py
class A:
label = 'a'
class B(A):
pass # was: label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # 'c'
print(d.__class__.mro()) # notice another way to get the MRO
# prints:
# [<class '__main__.D'>, <class '__main__.B'>,
# <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]So, we learn that the MRO is D-B-C-A-(object), which means when we ask for d.label, we get 'c', which is correct.
In day to day programming, it is not quite common to have to deal with the MRO, but the first time you fight against some mixin from a framework, I promise you'll be glad I spent a paragraph explaining it.
Static and class methods
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
Private methods and name mangling
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Method resolution order
By now, we know that when you ask for someobject.attribute, and attribute is not found on that object, Python starts searching in the class someobject was created from. If it's not there either, Python searches up the inheritance chain until either attribute is found or the object class is reached. This is quite simple to understand if the inheritance chain is only comprised of single inheritance steps, which means that classes have only one parent. However, when multiple inheritance is involved, there are cases when it's not straightforward to predict what will be the next class that will be searched for if an attribute is not found.
Python provides a way to always know what is the order in which classes are searched on attribute lookup: the method resolution order.
Note
The method resolution order (MRO) is the order in which base classes are searched for a member during lookup. From version 2.3 Python uses an algorithm called C3, which guarantees monotonicity.
In Python 2.2, new-style classes were introduced. The way you write a new-style class in Python 2.* is to define it with an explicit object base class. Classic classes were not explicitly inheriting from object and have been removed in Python 3.
One of the differences between classic and new style-classes in Python 2.* is that new-style classes are searched with the new MRO.
With regards to the previous example, let's see what is the MRO for the Square class:
oop/multiple.inheritance.py
print(square.__class__.__mro__)
# prints:
# (<class '__main__.Square'>, <class '__main__.RegularPolygon'>,
# <class '__main__.Polygon'>, <class '__main__.Shape'>,
# <class '__main__.Plotter'>, <class 'object'>)To get to the MRO of a class, we can go from the instance to its __class__ attribute and from that to its __mro__ attribute. Alternatively, we could have called Square.__mro__, or Square.mro() directly, but if you have to do it dynamically, it's more likely you will have an object in your hands rather than a class.
Note that the only point of doubt is the bisection after Polygon, where the inheritance chain breaks into two ways, one leads to Shape and the other to Plotter. We know by scanning the MRO for the Square class that Shape is searched before Plotter.
Why is this important? Well, imagine the following code:
oop/mro.simple.py
class A:
label = 'a'
class B(A):
label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # Hypothetically this could be either 'b' or 'c'Both B and C inherit from A, and D inherits from both B and C. This means that the lookup for the label attribute can reach the top (A) through both B or C. According to which is reached first, we get a different result.
So, in the preceding example we get 'b', which is what we were expecting, since B is the leftmost one amongst base classes of D. But what happens if I remove the label attribute from B? This would be the confusing situation: Will the algorithm go all the way up to A or will it get to C first? Let's find out!
oop/mro.py
class A:
label = 'a'
class B(A):
pass # was: label = 'b'
class C(A):
label = 'c'
class D(B, C):
pass
d = D()
print(d.label) # 'c'
print(d.__class__.mro()) # notice another way to get the MRO
# prints:
# [<class '__main__.D'>, <class '__main__.B'>,
# <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]So, we learn that the MRO is D-B-C-A-(object), which means when we ask for d.label, we get 'c', which is correct.
In day to day programming, it is not quite common to have to deal with the MRO, but the first time you fight against some mixin from a framework, I promise you'll be glad I spent a paragraph explaining it.
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Static and class methods
Until now, we have coded classes with attributes in the form of data and instance methods, but there are two other types of methods that we can place inside a class: static methods and class methods.
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
Private methods and name mangling
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Static methods
As you may recall, when you create a class object, Python assigns a name to it. That name acts as a namespace, and sometimes it makes sense to group functionalities under it. Static methods are perfect for this use case since unlike instance methods, they are not passed any special argument. Let's look at an example of an imaginary String class.
oop/static.methods.py
class String:
@staticmethod
def is_palindrome(s, case_insensitive=True):
# we allow only letters and numbers
s = ''.join(c for c in s if c.isalnum()) # Study this!
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome(
'Radar', case_insensitive=False)) # False: Case Sensitive
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('Never Odd, Or Even!')) # True
print(String.is_palindrome(
'In Girum Imus Nocte Et Consumimur Igni') # Latin! Show-off!
) # True
print(String.get_unique_words(
'I love palindromes. I really really love them!'))
# {'them!', 'really', 'palindromes.', 'I', 'love'}The preceding code is quite interesting. First of all, we learn that static methods are created by simply applying the staticmethod decorator to them. You can see that they aren't passed any special argument so, apart from the decoration, they really just look like functions.
We have a class, String, which acts as a container for functions. Another approach would be to have a separate module with functions inside. It's really a matter of preference most of the time.
The logic inside is_palindrome should be straightforward for you to understand by now, but, just in case, let's go through it. First we remove all characters from s that are not either letters or numbers. In order to do this, we use the join method of a string object (an empty string object, in this case). By calling join on an empty string, the result is that all elements in the iterable you pass to join will be concatenated together. We feed join a generator expression that says, take any character from s if the character is either alphanumeric or a number. I hope you have been able to find that out by yourself, maybe using the inside-out technique I showed you in one of the preceding chapters.
We then lowercase s if case_insensitive is True, and then we proceed to check if it is a palindrome. In order to do this, we compare the first and last characters, then the second and the second to last, and so on. If at any point we find a difference, it means the string isn't a palindrome and therefore we can return False. On the other hand, if we exit the for loop normally, it means no differences were found, and we can therefore say the string is a palindrome.
Notice that this code works correctly regardless of the length of the string, that is, if the length is odd or even. len(s) // 2 reaches half of s, and if s is an odd amount of characters long, the middle one won't be checked (like in RaDaR, D is not checked), but we don't care; it would be compared with itself so it's always passing that check.
get_unique_words is much simpler, it just returns a set to which we feed a list with the words from a sentence. The set class removes any duplication for us, therefore we don't need to do anything else.
The String class provides us a nice container namespace for methods that are meant to work on strings. I could have coded a similar example with a Math class, and some static methods to work on numbers, but I wanted to show you something different.
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Class methods
Class methods are slightly different from instance methods in that they also take a special first argument, but in this case, it is the class object itself. Two very common use cases for coding class methods are to provide factory capability to a class and to allow breaking up static methods (which you have to then call using the class name) without having to hardcode the class name in your logic. Let's look at an example of both of them.
oop/class.methods.factory.py
class Point: def __init__(self, x, y): self.x = x self.y = y @classmethod def from_tuple(cls, coords): # cls is Point return cls(*coords) @classmethod def from_point(cls, point): # cls is Point return cls(point.x, point.y) p = Point.from_tuple((3, 7)) print(p.x, p.y) # 3 7 q = Point.from_point(p) print(q.x, q.y) # 3 7
In the preceding code, I showed you how to use a class method to create a factory for the class. In this case, we want to create a Point instance by passing both coordinates (regular creation p = Point(3, 7)), but we also want to be able to create an instance by passing a tuple (Point.from_tuple) or another instance (Point.from_point).
Within the two class methods, the cls argument refers to the Point class. As with instance method, which take self as the first argument, class method take a cls argument. Both self and cls are named after a convention that you are not forced to follow but are strongly encouraged to respect. This is something that no Python coder would change because it is so strong a convention that parsers, linters, and any tool that automatically does something with your code would expect, so it's much better to stick to it.
Let's look at an example of the other use case: splitting a static method.
oop/class.methods.split.py
class String:
@classmethod
def is_palindrome(cls, s, case_insensitive=True):
s = cls._strip_string(s)
# For case insensitive comparison, we lower-case s
if case_insensitive:
s = s.lower()
return cls._is_palindrome(s)
@staticmethod
def _strip_string(s):
return ''.join(c for c in s if c.isalnum())
@staticmethod
def _is_palindrome(s):
for c in range(len(s) // 2):
if s[c] != s[-c -1]:
return False
return True
@staticmethod
def get_unique_words(sentence):
return set(sentence.split())
print(String.is_palindrome('A nut for a jar of tuna')) # True
print(String.is_palindrome('A nut for a jar of beans')) # FalseCompare this code with the previous version. First of all note that even though is_palindrome is now a class method, we call it in the same way we were calling it when it was a static one. The reason why we changed it to a class method is that after factoring out a couple of pieces of logic (_strip_string and _is_palindrome), we need to get a reference to them and if we have no cls in our method, the only option would be to call them like this: String._strip_string(...) and String._is_palindrome(...), which is not good practice, because we would hardcode the class name in the is_palindrome method, thereby putting ourselves in the condition of having to modify it whenever we would change the class name. Using cls will act as the class name, which means our code won't need any amendments.
Note also that, by naming the factored-out methods with a leading underscore, I am hinting that those methods are not supposed to be called from outside the class, but this will be the subject of the next paragraph.
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Private methods and name mangling
If you have any background with languages like Java, C#, C++, or similar, then you know they allow the programmer to assign a privacy status to attributes (both data and methods). Each language has its own slightly different flavor for this, but the gist is that public attributes are accessible from any point in the code, while private ones are accessible only within the scope they are defined in.
In Python, there is no such thing. Everything is public; therefore, we rely on conventions and on a mechanism called name mangling.
The convention is as follows: if an attribute's name has no leading underscores it is considered public. This means you can access it and modify it freely. When the name has one leading underscore, the attribute is considered private, which means it's probably meant to be used internally and you should not use it or modify it from the outside. A very common use case for private attributes are helper methods that are supposed to be used by public ones (possibly in call chains in conjunction with other methods), and internal data, like scaling factors, or any other data that ideally we would put in a constant (a variable that cannot change, but, surprise, surprise, Python doesn't have those either).
This characteristic usually scares people from other backgrounds off; they feel threatened by the lack of privacy. To be honest, in my whole professional experience with Python, I've never heard anyone screaming Oh my God, we have a terrible bug because Python lacks private attributes! Not once, I swear.
That said, the call for privacy actually makes sense because without it, you risk introducing bugs into your code for real. Let's look at a simple example:
oop/private.attrs.py
class A:
def __init__(self, factor):
self._factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self._factor))
class B(A):
def op2(self, factor):
self._factor = factor
print('Op2 with factor {}...'.format(self._factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 42... <- This is BAD
In the preceding code, we have an attribute called _factor, and let's pretend it's very important that it isn't modified at runtime after the instance is created, because op1 depends on it to function correctly. We've named it with a leading underscore, but the issue here is that when we call obj.op2(42), we modify it, and this reflects in subsequent calls to op1.
Let's fix this undesired behavior by adding another leading underscore:
oop/private.attrs.fixed.py
class A:
def __init__(self, factor):
self.__factor = factor
def op1(self):
print('Op1 with factor {}...'.format(self.__factor))
class B(A):
def op2(self, factor):
self.__factor = factor
print('Op2 with factor {}...'.format(self.__factor))
obj = B(100)
obj.op1() # Op1 with factor 100...
obj.op2(42) # Op2 with factor 42...
obj.op1() # Op1 with factor 100... <- Wohoo! Now it's GOOD!
Wow, look at that! Now it's working as desired. Python is kind of magic and in this case, what is happening is that the name mangling mechanism has kicked in.
Name mangling means that any attribute name that has at least two leading underscores and at most one trailing underscore, like __my_attr, is replaced with a name that includes an underscore and the class name before the actual name, like _ClassName__my_attr.
This means that when you inherit from a class, the mangling mechanism gives your private attribute two different names in the base and child classes so that name collision is avoided. Every class and instance object stores references to their attributes in a special attribute called __dict__, so let's inspect obj.__dict__ to see name mangling in action:
oop/private.attrs.py
print(obj.__dict__.keys()) # dict_keys(['_factor'])
This is the _factor attribute that we find in the problematic version of this example. But look at the one that is using __factor:
oop/private.attrs.fixed.py
print(obj.__dict__.keys()) # dict_keys(['_A__factor', '_B__factor'])
See? obj has two attributes now, _A__factor (mangled within the A class), and _B__factor (mangled within the B class). This is the mechanism that makes possible that when you do obj.__factor = 42, __factor in A isn't changed, because you're actually touching _B__factor, which leaves _A__factor safe and sound.
If you're designing a library with classes that are meant to be used and extended by other developers, you will need to keep this in mind in order to avoid unintentional overriding of your attributes. Bugs like these can be pretty subtle and hard to spot.
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
The property decorator
Another thing that would be a crime not to mention is the property decorator. Imagine that you have an age attribute in a Person class and at some point you want to make sure that when you change its value, you're also checking that age is within a proper range, like [18, 99]. You can write accessor methods, like get_age() and set_age() (also called getters and setters) and put the logic there. get_age() will most likely just return age, while set_age() will also do the range check. The problem is that you may already have a lot of code accessing the age attribute directly, which means you're now up to some good (and potentially dangerous and tedious) refactoring. Languages like Java overcome this problem by using the accessor pattern basically by default. Many Java Integrated Development Environments (IDEs) autocomplete an attribute declaration by writing getter and setter accessor methods stubs for you on the fly.
Python is smarter, and does this with the property decorator. When you decorate a method with property, you can use the name of the method as if it was a data attribute. Because of this, it's always best to refrain from putting logic that would take a while to complete in such methods because, by accessing them as attributes, we are not expecting to wait.
Let's look at an example:
oop/property.py
class Person:
def __init__(self, age):
self.age = age # anyone can modify this freely
class PersonWithAccessors:
def __init__(self, age):
self._age = age
def get_age(self):
return self._age
def set_age(self):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
class PersonPythonic:
def __init__(self, age):
self._age = age
@property
def age(self):
return self._age
@age.setter
def age(self, age):
if 18 <= age <= 99:
self._age = age
else:
raise ValueError('Age must be within [18, 99]')
person = PersonPythonic(39)
print(person.age) # 39 - Notice we access as data attribute
person.age = 42 # Notice we access as data attribute
print(person.age) # 42
person.age = 100 # ValueError: Age must be within [18, 99]The Person class may be the first version we write. Then we realize we need to put the range logic in place so, with another language, we would have to rewrite Person as the PersonWithAccessors class, and refactor all the code that was using Person.age. In Python, we rewrite Person as PersonPythonic (you normally wouldn't change the name, of course) so that the age is stored in a private _age variable, and we define property getters and setters using that decoration, which allow us to keep using the person instances as we were before. A getter is a method that is called when we access an attribute for reading. On the other hand, a setter is a method that is called when we access an attribute to write it. In other languages, like Java for example, it's customary to define them as get_age() and set_age(int value), but I find the Python syntax much neater. It allows you to start writing simple code and refactor later on, only when you need it, there is no need to pollute your code with accessors only because they may be helpful in the future.
The property decorator also allows for read-only data (no setter) and for special actions when the attribute is deleted. Please refer to the official documentation to dig deeper.
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Operator overloading
I find Python's approach to operator overloading to be brilliant. To overload an operator means to give it a meaning according to the context in which it is used. For example, the + operator means addition when we deal with numbers, but concatenation when we deal with sequences.
In Python, when you use operators, you're most likely calling the special methods of some objects behind the scenes. For example, the call a[k] roughly translates to type(a).__getitem__(a, k).
As an example, let's create a class that stores a string and evaluates to True if '42' is part of that string, and False otherwise. Also, let's give the class a length property which corresponds to that of the stored string.
oop/operator.overloading.py
class Weird:
def __init__(self, s):
self._s = s
def __len__(self):
return len(self._s)
def __bool__(self):
return '42' in self._s
weird = Weird('Hello! I am 9 years old!')
print(len(weird)) # 24
print(bool(weird)) # False
weird2 = Weird('Hello! I am 42 years old!')
print(len(weird2)) # 25
print(bool(weird2)) # TrueThat was fun, wasn't it? For the complete list of magic methods that you can override in order to provide your custom implementation of operators for your classes, please refer to the Python data model in the official documentation.
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Polymorphism – a brief overview
The word polymorphism comes from the Greek polys (many, much) and morphē (form, shape), and its meaning is the provision of a single interface for entities of different types.
In our car example, we call engine.start(), regardless of what kind of engine it is. As long as it exposes the start method, we can call it. That's polymorphism in action.
In other languages, like Java, in order to give a function the ability to accept different types and call a method on them, those types need to be coded in such a way that they share an interface. In this way, the compiler knows that the method will be available regardless of the type of the object the function is fed (as long as it extends the proper interface, of course).
In Python, things are different. Polymorphism is implicit, nothing prevents you to call a method on an object, therefore, technically, there is no need to implement interfaces or other patterns.
There is a special kind of polymorphism called ad hoc polymorphism, which is what we saw in the last paragraph: operator overloading. The ability of an operator to change shape, according to the type of data it is fed.
I cannot spend too much time on polymorphism, but I encourage you to check it out by yourself, it will expand your understanding of OOP. Good luck!
Writing a custom iterator
Now we have all the tools to appreciate how we can write our own custom iterator. Let's first define what is an iterable and an iterator:
- Iterable: An object is said to be iterable if it's capable of returning its members one at a time. Lists, tuples, strings, dicts, are all iterables. Custom objects that define either of
__iter__or__getitem__methods are also iterables. - Iterator: An object is said to be an iterator if it represents a stream of data. A custom iterator is required to provide an implementation for
__iter__that returns the object itself, and an implementation for__next__, which returns the next item of the data stream until the stream is exhausted, at which point all successive calls to__next__simply raise theStopIterationexception. Built-in functions such asiterandnextare mapped to call__iter__and__next__on an object, behind the scenes.
Let's write an iterator that returns all the odd characters from a string first, and then the even ones.
iterators/iterator.py
class OddEven:
def __init__(self, data):
self._data = data
self.indexes = (list(range(0, len(data), 2)) +
list(range(1, len(data), 2)))
def __iter__(self):
return self
def __next__(self):
if self.indexes:
return self._data[self.indexes.pop(0)]
raise StopIteration
oddeven = OddEven('ThIsIsCoOl!')
print(''.join(c for c in oddeven)) # TIICO!hssol
oddeven = OddEven('HoLa') # or manually...
it = iter(oddeven) # this calls oddeven.__iter__ internally
print(next(it)) # H
print(next(it)) # L
print(next(it)) # o
print(next(it)) # aSo, we needed to provide an implementation for __iter__ which returned the object itself, and then one for __next__. Let's go through it. What needs to happen is that we return _data[0], _data[2], _data[4], ..., _data[1], _data[3], _data[5], ... until we have returned every item in the data. In order to do this, we prepare a list, indexes, like [0, 2, 4, 6, ..., 1, 3, 5, ...], and while there is at least an element in it, we pop the first one and return the element from the data that is at that position, thereby achieving our goal. When indexes is empty, we raise StopIteration, as required by the iterator protocol.
There are other ways to achieve the same result, so go ahead and try to code a different one yourself. Make sure the end result works for all edge cases, empty sequences, sequences of length 1, 2, and so on.
Summary
In this chapter, we saw decorators, discovered the reasons for having them, and a few examples using one or more at the same time. We also saw decorators that take arguments, which are usually used as decorator factories.
We scratched the surface of object-oriented programming in Python. We covered all the basics in a way that you should now be able to understand fairly easily the code that will come in future chapters. We talked about all kinds of methods and attributes that one can write in a class, we explored inheritance versus composition, method overriding, properties, operator overloading, and polymorphism.
At the end, we very briefly touched base on iterators, so now you have all the knowledge to also understand generators more deeply.
In the next chapter, we take a steep turn. It will start the second half of the book, which is much more project-oriented so, from now on, it will be less theory and more code, I hope you will enjoy following the examples and getting your hands dirty, very dirty.
They say that a smooth sea never made a skillful sailor, so keep exploring, break things, read the error messages as well as the documentation, and let's see if we can get to see that white rabbit.


