






















































Some PostgreSQL vendors provide proprietary extended functionality that makes it possible for a cluster to contain multiple writable Primary nodes simultaneously. Users of this kind of software can expect certain enhanced capabilities, though concessions are often necessary. This recipe will explore how PostgreSQL multi-master can influence cluster topology.
Incorporating multi-master
Getting ready
This recipe will require some knowledge of where the nodes are likely to reside on a global scale. Will some PostgreSQL nodes be in Dubai, while others are in Cairo or Toronto? We will also need to have a very basic understanding of how the application operates. This may mean interacting with application developers or designers to derive a rough approximation of queries required for basic operation.
How to do it...
When considering deploying multiple writable PostgreSQL nodes, utilize these guiding questions:
- Is there significant geographical distance between nodes?
- Does the application use multiple transactions or queries per operation?
- Are accounts or users likely to operate primarily in a certain region?
How it works...
Probably the most obvious benefit arising from using multiple writable PostgreSQL nodes is one of reduced write latency. Consider an initial cluster that may resemble this diagram:

Each write to Tokyo or Sydney must first cross thousands of miles before being committed. And due to how replication works, the local replicas in those regions will have to wait for the transaction to be replayed before it will be visible there. These times can be considerable. Consider this table of round-trip-times for network traffic for the locations we've chosen:
|
Dallas |
Sydney |
Tokyo |
|
|
Dallas |
X |
205 ms |
145 ms |
|
Sydney |
200 ms |
X |
195 ms |
|
Tokyo |
145 ms |
195 ms |
X |
Each write may require over 200 ms simply to reach the primary node. Then, the same data must be transmitted from the Primary to each Standby, doubling the time necessary before the transaction may be visible in the continent where it originated. Since many application actions can invoke multiple transactions, this can cause a time amplification effect that could last for several minutes in extreme cases.
This is why we ask whether or not an application performs multiple actions per task. Displaying a web page may require a dozen queries. Submitting a credit application can mean several writes and polling for results. With competition around every corner, every second of waiting increases the chances a user may simply use another application without such latency issues. If each of those nodes were a Primary, the transaction write overhead would be effectively zero.
The last question we should answer is one of expandability. As the usage volume of the cluster increases, we will inevitably require further nodes. A popular method of addressing this is to regionalize the primary nodes, but otherwise follow standard replication concepts. As an example, imagine we needed a further two nodes in each region to fulfill read traffic. It could look something like this:
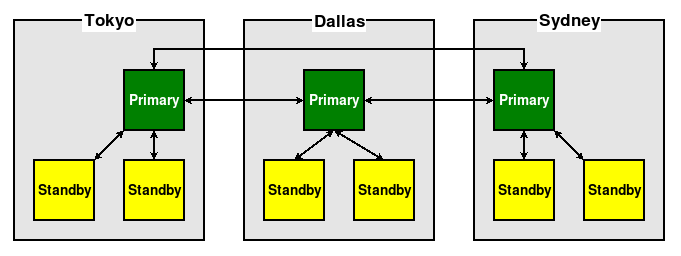
This Hub + Spoke model helps ensure each region can keep up with demand, without adding latency by including nodes outside of a particular region. Note also that, when using these multi-master clusters, all nodes often require direct connections to each other.
There's more...
These types of multi-master PostgreSQL clusters often require two direct connections between all participating nodes, one for each direction of communication. This is called a Mesh topology, and is considered by some to be a source of excessive communication overhead. If we think about it, that's a valid criticism given that every transaction in the cluster must eventually be acknowledged by every other primary node. In very active systems, the impact could be significant.
A scenario along the lines of the following diagram, for example, may present complications:

By merely adding three more primary nodes, we've increased the number of communication channels to 30. In fact, the general formula for this can be expressed for PostgreSQL multi-master as follows:
C = N * (N - 1)
So, if we have 3 nodes, we can expect 6 channels, but if we have 10 nodes, there are 90 instead. This is one major reason for the Hub + Spoke model, since the local Replica nodes do not need to be primary nodes and contribute to the topology communication overhead.
Consider the potential impact of this before simply embracing the benefits of operating in multiple locations simultaneously.
See also
If interested, feel free to explore some of these concepts in greater depth using the resources listed here: https://wondernetwork.com/pings/


