























































Processing larger-than-RAM datasets
One of the outstanding features of Polars is its streaming mode. It’s part of the lazy API and it allows you to process data that is larger than the memory available on your machine. With streaming mode, you let your machine handle huge data by processing it in batches. You would not be able to process such large data otherwise.
One thing to keep in mind is that not all lazy operations are supported in streaming mode, as it’s still in development. You can still use any lazy operation in your query, but ultimately, the Polars engine will determine whether the operation can be executed in streaming or not. If the answer is no, then Polars runs the query using non-streaming mode. We can expect that this feature will include more lazy operations and become more sophisticated over time.
In this recipe, we’ll demonstrate how streaming mode works by creating a simple query to read a .csv file that’s larger than the available RAM on a machine and process it using streaming mode.
Getting ready
You’d need a dataset that’s larger than the available RAM on your machine to test streaming mode. I’m using a taxi trips dataset, which has over 80 GB on disk. You can download the dataset from this website: https://data.cityofchicago.org/Transportation/Taxi-Trips-2013-2023-/wrvz-psew/about_data.
How to do it...
Here are the steps for the recipe.
- Import the Polars library:
import polars as pl
- Read the csv file in streaming mode by adding a
streaming=Trueparameter inside.collect(). The file name string should specify where your file is located (mine is in myDownloadsfolder):taxi_trips = ( pl.scan_csv('~/Downloads/Taxi_Trips.csv') .collect(streaming=True) ) - Check the first five rows with
.head()to see what the data looks like:taxi_trips.head()
The preceding code will return the following output:
Figure 1.37 – The first five rows of the taxi trip dataset
How it works...
There are two things you should be aware of in the example code:
- It uses
.scan_read()instead of.read_csv() - A parameter is specified in
.collect(). It becomes.collect(streaming=True).
We will enable streaming mode by setting streaming=True inside the .collect() method. In this specific example, I’m only reading a .csv file, nothing complex. I’m using the .scan_read() method to read with lazy mode.
In theory, without streaming mode, I wouldn’t be able to process this dataset. This is because my laptop has 64 GB of RAM (yes, my laptop has a decent amount of memory!), which is lower than the size of the dataset on disk, which is more than 80 GB.
It took about two minutes for my laptop to process the data in streaming mode. Without streaming mode, I would get an out-of-memory error. You can confirm this by running your code without streaming=True in the .collect() method.
There’s more...
If you’re doing other operations other than reading the data, such as aggregations and filtering, then Polars (with LazyFrame) might be able to optimize your query so that it doesn’t need to read the whole dataset in memory. This means that you might not even need to utilize streaming mode to work with data larger than your RAM. Aggregations and filtering essentially summarize the data or reduce the number of rows, which leads to not needing to read in the whole dataset.
Let’s say that you apply a simple group by and aggregation over a column like the one in the following code. You’ll see that you can run it without using streaming mode (depending on your chosen dataset and the available RAM on your machine):
trip_total_by_pay_type = (
pl.scan_csv('~/Downloads/Taxi_Trips.csv')
.group_by('Payment Type')
.agg(pl.col('Trip Total').sum())
.collect()
)
trip_total_by_pay_type.head() The preceding code will return the following output:
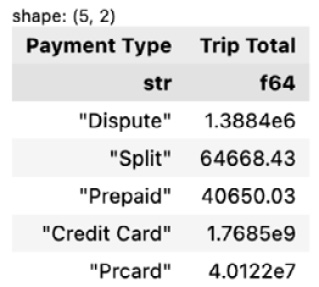
Figure 1.38 – Trip total by payment type
With that said, it may still be a good idea to use streaming=True when there is a possibility that the size of the dataset goes over your available RAM or that data may grow in size over time.
See also
Please refer to the streaming API page in Polars’s documentation: https://pola-rs.github.io/polars-book/user-guide/concepts/streaming/.










