






















































Creating, modifying, and deleting columns
The key methods we’ll cover in this recipe are .select(), .with_columns(), and .drop(). We’ve seen in the previous recipe that both .select() and .with_columns() are essential for column selection in Polars.
In this recipe, you’ll learn how to leverage those methods to create, modify, and delete columns using Polars’ expressions.
Getting ready
This recipe requires the titanic dataset. Read it into your code by typing the following:
df = pl.read_csv('../data/titanic_dataset.csv') How to do it...
Let’s dive into the recipe. Here are the steps:
- Create a column based on another column:
df.with_columns( pl.col('Fare').max().alias('Max Fare') ).head()The preceding code will return the following output:

Figure 1.25 – A DataFrame with a new column
We added a new column called max_fare. Its value is the max of the Fare column. We’ll cover aggregations in more detail in a later chapter.
You can name your column without using .alias(). You’ll need to specify the name at the beginning of your expression. Note that you won’t be able to use spaces in the column name with this approach:
df.with_columns(
max_fare=pl.col('Fare').max()
).head() The preceding code will return the following output:

Figure 1.26 – A different way to name a new column
If you don’t specify a new column name, then the base column will be overwritten:
df.with_columns(
pl.col('Fare').max()
).head() The preceding code will return the following output:
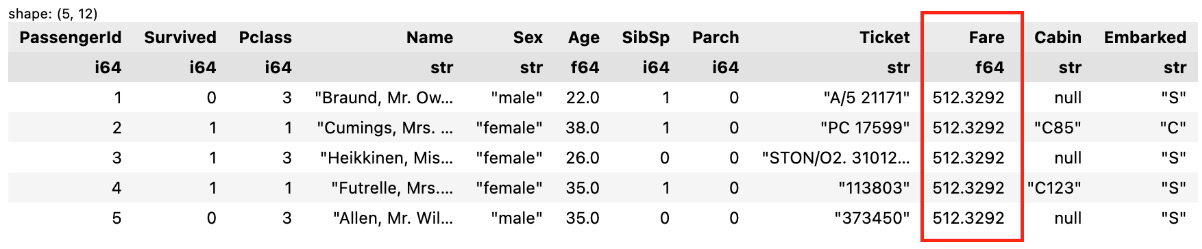
Figure 1.27 – A new column with the same name as the base column
To demonstrate how you can use multiple expressions for a column, let’s add another logic to this column:
df.with_columns(
(pl.col('Fare').max() - pl.col('Fare').mean()).alias('Max Fare - Avg Fare')
).head() The preceding code will return the following output:

Figure 1.28 – A new column with more complex expressions
We added a column that calculates the max and mean of the Fare column and does a subtraction. This is just one example of how you can use Polars’ expressions.
- Create a column with a literal value using the
pl.lit()method:df.with_columns(pl.lit('Titanic')).head()The preceding code will return the following output:

Figure 1.29 – The output with literal values
- Add a row count with
.with_row_index():df.with_row_index().head()
The preceding code will return the following output:

Figure 1.30 – The output with a row number
- Modify values in a column:
df.with_columns(pl.col('Sex').str.to_titlecase()).head()The preceding code will return the following output:
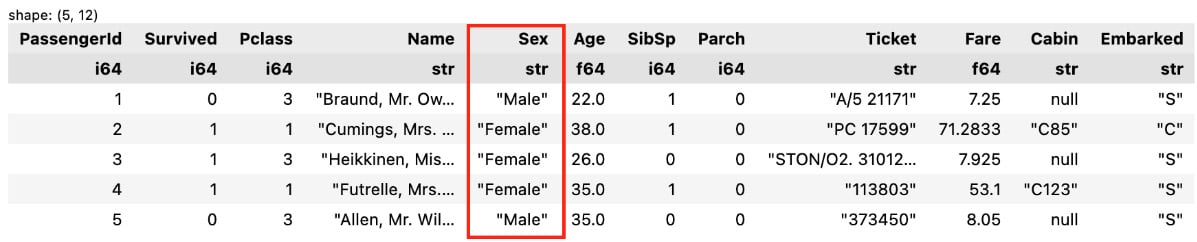
Figure 1.31 – The output of the modified column
We transformed the Sex column into title case .str is what gives you access to string methods in Polars, which we’ll cover in Chapter 6, Performing String Manipulations.
- You can delete a column with the help of the following code:
df.drop(['Pclass', 'Name', 'SibSp', 'Parch', 'Ticket', 'Cabin', 'Embarked']).head()
The preceding code will return the following output:
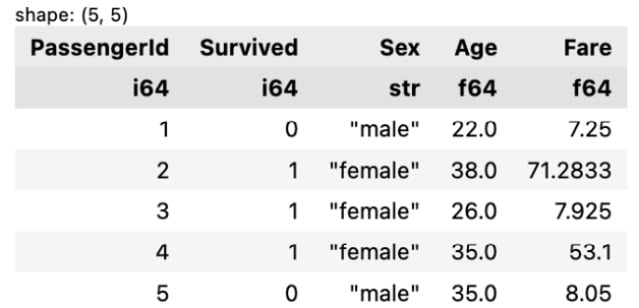
Figure 1.32 – The output after dropping columns
- You can use
.select()instead to choose the columns that you want to keep:df.select(['PassengerId', 'Survived', 'Sex', 'Age', 'Fare']).head()
The preceding code will return the following output:
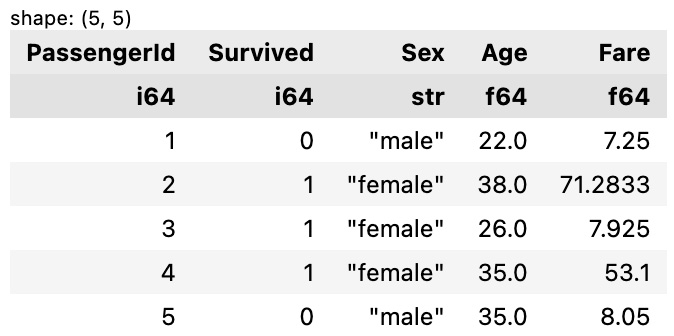
Figure 1.33 – DataFrame with selected columns
How it works...
The pl.lit() method can be used whenever you want to specify a literal or constant value. You can use not only a string value but also various data types such as integer, boolean, list, and so on.
When creating or adding a new column, there are three ways you can name it:
- Use
.alias(). - Define the column name at the beginning of your expression, like the one you saw earlier:
max_fare=pl.col('Fare').max(). You can’t use spaces in your column name. - Don’t specify the column name, which would replace the existing column if the new column were created based on another column. Alternatively, the column will be named
literalwhen usingpl.lit().
Both the.select() and .with_columns() methods can create and modify columns. The difference is in whether you keep the unspecified columns or drop them. Essentially, you can use the .select() method for dropping columns while adding new columns. That way, you may avoid using both the.with_columns() and .drop() methods in combination when .select() alone can do the job.
Also, note that new or modified columns don’t persist when using the .select() or .with_columns() methods. You’ll need to store the result into a variable if needed:
df = df.with_columns(
pl.col('Fare').max()
) There’s more...
For best practice, you should put all your expressions into one method where possible instead of using multiple .with_columns(), for example. This makes sure that expressions are executed in parallel, whereas if you use multiple .with_columns(), then Polars’s engine might not recognize that they run in parallel.
You should write your code like this:
best_practice = (
df.with_columns(
pl.col('Fare').max().alias('Max Fare'),
pl.lit('Titanic'),
pl.col('Sex').str.to_titlecase()
)
) Avoid writing your code like this:
not_so_good_practice = (
df
.with_columns(pl.col('Fare').max().alias('Max Fare'))
.with_columns(pl.lit('Titanic'))
.with_columns(pl.col('Sex').str.to_titlecase())
) Both of the preceding queries produce the following output:

Figure 1.34 – The output with new columns added
Note
You won’t be able to add a new column on top of another new column you’re trying to define in the same method (such as the .with_columns() method). The only time when you’ll need to use multiple methods is when your new column depends on another new column in your dataset that doesn’t yet exist.
See also
Please refer to these resources for more information:
- https://pola-rs.github.io/polars/user-guide/concepts/expressions/
- https://www.pola.rs/posts/the-expressions-api-in-polars-is-amazing/
- https://pola-rs.github.io/polars/user-guide/concepts/contexts/
- https://pola-rs.github.io/polars/py-polars/html/reference/expressions/api/polars.lit.html
- https://pola-rs.github.io/polars/py-polars/html/reference/expressions/api/polars.Expr.alias.html










