Developers of Power BI content should become familiar with the settings available in Power BI options and data source settings as these configurations determine available functionality, user interface options, default behaviors, performance, and the security of the data being accessed.
Figure 4: Power BI Desktop Options (July 2017)
GLOBAL options are applied to all Power BI Desktop files created or accessed by the user, while CURRENT FILE options must be defined for each Power BI Desktop file. The following steps are recommended for GLOBAL options.
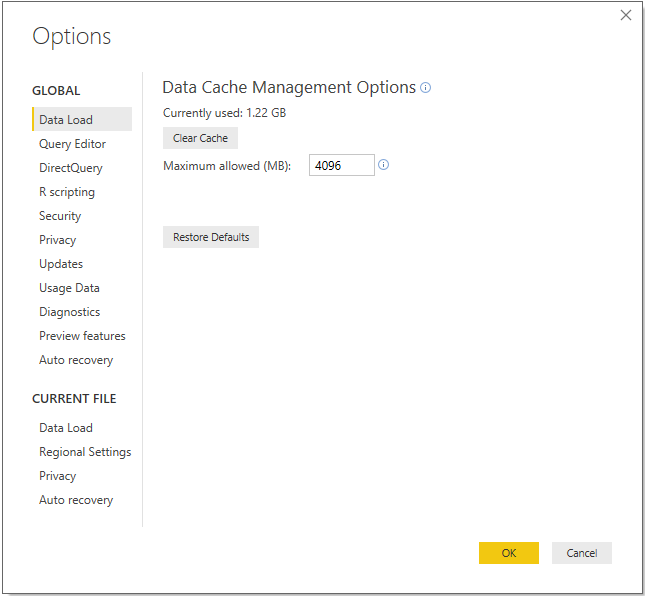
- On the Data Load tab, confirm that the currently used data cache is below the Maximum allowed (MB) setting. If it is near the limit and local disk space is available, increase the value of the Maximum allowed (MB). Do not clear the cache unless local disk space is unavailable as this will require additional, often unnecessary, queries to be executed at design time.
Figure 5: Global Data Load options
- On the Query Editor tab, display both the query settings pane and the formula bar. This will allow for greater visibility to the structure and specific M functions utilized by individual queries.
Figure 6: Global Query Editor options
- On the DirectQuery tab, enable the Allow unrestricted measures in DirectQuery mode setting.
Figure 7: Global DirectQuery options
This enables additional DAX functions to be used in metrics against DirectQuery data models that are necessary to meet many common requirements. Although all DAX functions are supported for DirectQuery models, certain functions are not optimized for DirectQuery; they may not generate an efficient SQL query and may require local, single-threaded resources to execute. For this reason, among others discussed in Chapter 3, Building a Power BI Data Model, the default Import mode is often a better option than DirectQuery for more complex data models.
- On the Security tab, select the option to require user approval for new native database queries. Native queries are the user-specified SQL statements passed to data sources as opposed to the queries Power BI generates internally.
Figure 8: Security Option for Native Database Queries
- Optionally, set Show security warning when adding a custom visual to a report as well.
From a security standpoint, custom visuals can be divided between those developed by Microsoft, those developed by third parties but available in the Office Store, and finally those developed by third parties but available exclusively from sources outside the Office Store. Custom visuals developed by Microsoft have been thoroughly tested for safety. Third-party custom visuals available in the Office Store have been through a validation process though there is no guarantee that all code paths have been tested. Third-party visuals not available in the Office Store should therefore be used with caution and it's recommended to establish a policy regarding the use of custom visuals.
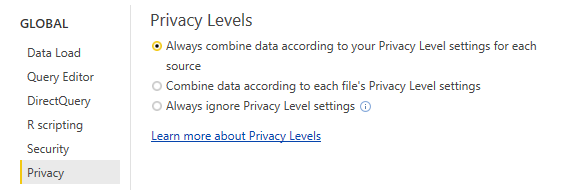
- On the privacy tab, configure the privacy levels for all data sources and enable the option to Always combine data according to your Privacy Level settings for each source. See How it Works... for details on these settings.
Figure 9: Global Privacy Level Options
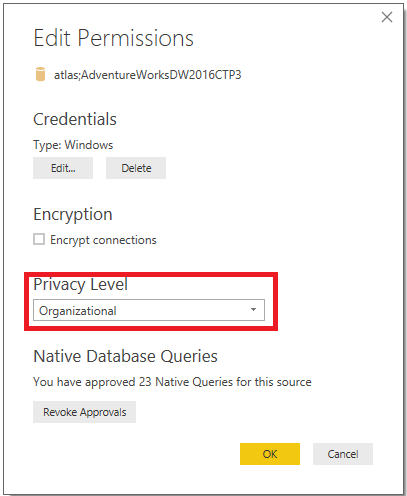
- From the Data Source settings, select an individual source and choose Edit Permissions to configure the privacy level:
Figure 10: Edit Permissions of a Data Source
The Edit Permissions dialog is also required to update credentials as data source system credentials expire or password resets are required.
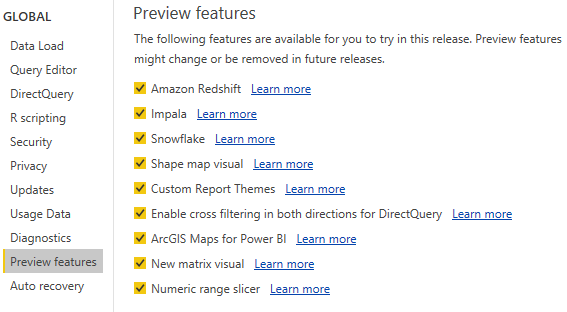
- Enable Preview features for evaluation purposes:
Figure 11: Preview Features available with the March 2017 Release of Power BI Desktop
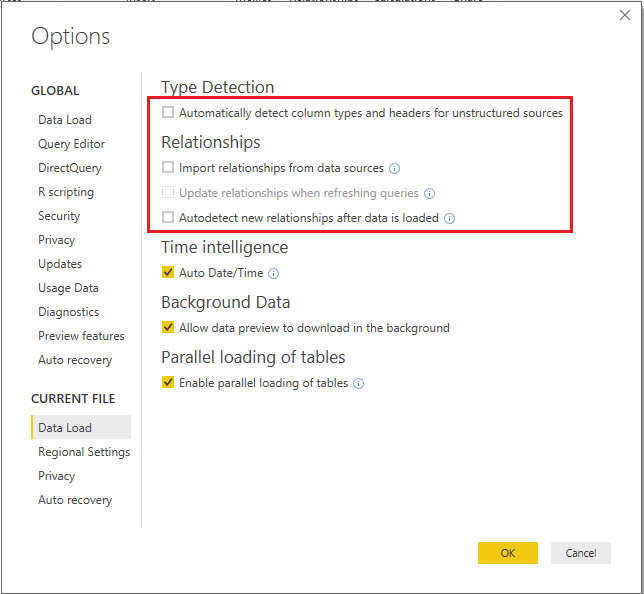
- On the Data Load tab for the CURRENT FILE, disable the automatic detection of column types and relationships. These model design decisions should be implemented explicitly by the Power BI developer with knowledge of the source data.
Figure 12: Disabled Relationships Options for the Current File
- As the current file options, it's necessary to apply these settings with each Power BI Desktop file to avoid default behaviors.
For example, the default detection of column types from unstructured sources such as text or Excel files will create a hardcoded dependency on the column names in the source file. Additionally, this default transformation will be applied prior to any filter expression and thus can require more time and resources to perform the refresh.