






















































As we saw in the previous pages, redirection is one of the last operations undertaken by Bash to parse and prepare the command line that will lead to the execution of a command. But what is a redirection? You can easily guess from your everyday experience. It means taking a stream that goes from one point to another and making it go somewhere else, like changing the flow of a river and making it go somewhere else. In Linux and Unix, it is quite the same, just keep in mind the following two principles:
- In Unix, each process, except for daemons, is supposed to be connected to a standard input, standard output, and standard error device
- Every device in Unix is represented by a file
You can also think of these devices as streams:
- Standard input, named stdin, is the intaking stream from which the process receives input data
- Standard output, named stdout, is the outbound stream where the process writes its output data
- Standard error, named stderr, is the stream where the process writes its error messages
These streams are also identified by a standard POSIX file descriptor, which is an integer used by the kernel as a handler to refer to them, as you can see in the following table:
|
Device |
Mode |
File descriptor |
|
stdin |
read |
0 |
|
stdout |
write |
1 |
|
stderr |
write |
2 |
So, tinkering with the file descriptors for the three main streams means that we can redirect the flows between stdin and stdout, but also stderr, from one process to the other. So, we can make different processes communicate with each other, and this is actually a form of IPC, inter-process communication, which we will look at it in more detail later in this book.
How do we redirect the Input/Output (I/O), from one process to another? We can get to this goal making use of some special characters:
>
Let's start stating that the default output of a process, usually, is the stdout. Whatever it returns is returned on the stdout which, again usually, is the monitor or the terminal. Using the > character, we can divert this flow and make it go to a file. If the file does not exist, it is created, and if it exists, it is flattened and its content is overwritten with the output stream of the process.
A simple example will clarify how the redirection to a file works:
gzarrelli:~$ echo "This is some content"
This is some content
We used the command echo to print a message on the stdout, and so we see the message written, in our case, to the text terminal that is usually connected to the shell:
gzarrelli:~$ ls -lah
total 0
drwxr-xr-x 2 zarrelli gzarrelli 68B 20 Jan 07:43 .
drwxr-xr-x+ 47 zarrelli gzarrelli 1.6K 20 Jan 07:43 ..
There is nothing on the filesystem, so the output went straight to the terminal, but the underlying directory was not affected. Now, time for a redirection:
gzarrelli:~$ echo "This is some content" > output_file.txt
Well, nothing to the screen; no output at all:
gzarrelli:~$ ls -lah
total 8
drwxr-xr-x 3 gzarrelli gzarrelli 102B 20 Jan 07:44 .
drwxr-xr-x+ 47 gzarrelli gzarrelli 1.6K 20 Jan 07:43 ..
-rw-r--r-- 1 gzarrelli gzarrelli 21B 20 Jan 07:44
output_file.txt
Actually, as you can see, the output did not vanish; it was simply redirected to a file on the current directory which got created and filled in:
gzarrelli:~$ cat output_file.txt
This is some content
Here we have something interesting. The cat command takes the content of the output_file.txt and sends it on the stdout. What we can see is that the output from the former command was redirected from the terminal and written to a file.
>>
This double mark answers a requirement we often face: How can we add more content coming from a process to a file without overwriting anything? Using this double character, which means no file is already in place, create a new one; if it already exists, just append the new data. Let's take the previous file and add some content to it:
gzarrelli:~$ echo "This is some other content" >> output_file.txt
gzarrelli:~$ cat output_file.txt
This is some content
This is some other content
Bingo, the file was not overwritten and the new content from the echo command was added to the old. Now, we know how to write to a file, but what about reading from somewhere else other than the stdin?
<
If the text terminal is the stdin, the keyboard is the standard input for a process, where it expects some data from. Again, we can divert the flow or data reading and get the process read from a file. For our example, we start creating a file containing a set of unordered numbers:
gzarrelli:~$ echo -e '5\n9\n4\n1\n0\n6\n2' > to_sort
And let us verify its content, as follows:
gzarrelli:~$ cat to_sort
5
9
4
1
0
6
2
Now we can have the sort command read this file into its stdin, as follows:
gzarrelli:~$ sort < to_sort
0
1
2
4
5
6
9
Nice, our numbers are now in sequence, but we can do something more interesting:
gzarrelli:~$ sort < to_sort > sorted
What did we do? We simply gave the file to_sort to the command sort into its standard input, and at the same time, we concatenated a second redirection so that the output of sort is written into the file sorted:
gzarrelli:~$ cat sorted
0
1
2
4
5
6
9
So, we can concatenate multiple redirections and have some interesting results, but we can do something even trickier, that is, chaining together inputs and outputs, not on files but on processes, as we will see now.
|
The pipe character does exactly what its name suggests, pipes the stream; could be the stdout or stderr, from one process to another, creating a simple interprocess communication facility:
gzarrelli:~$
ps aux | awk '{print $2, $3, $4}' | grep -v [A-Z] | sort -r -k 2
-g | head -n 3
95 0.0 0.0
94 0.0 0.0
93 0.0 0.0
In this example, we had a bit of fun, first getting a list of processes, then piping the output to the awk utility, which printed only the first, eleventh, and twelfth fields of the output of the first command, giving us the process ID, CPU percentage, and memory percentage columns. Then, we got rid of the heading PID %CPU %MEM, piping the awk output to the input of grep, which performed a reverse pattern matching on any strings containing a character, not a number. In the next stage, we piped the output to the sort command, which reverse-ordered the data based on the values in the second column. Finally, we wanted only the three lines, and so we got the PID of the first three heaviest processes relying on CPU occupation.
Redirection can also be used for some kind of fun or useful stuff, as you can see in the following screenshot:
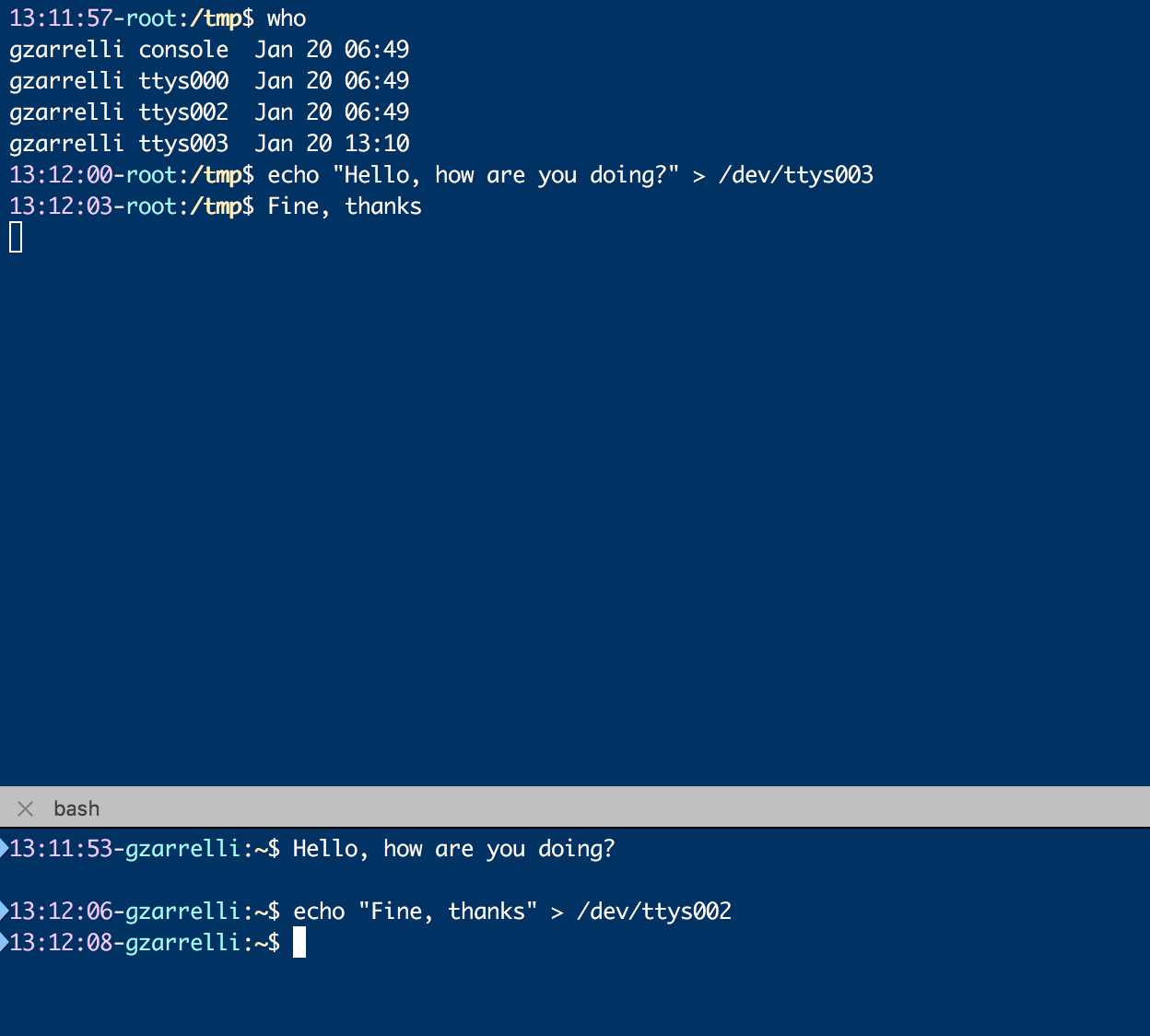
As you can see, there are two users on the same machine on different terminals, and remember that each user has to be connected to a terminal. To be able to write to any user's terminal, you must be root or, as in this example, the same user on two different terminals. With the who command we can identify which terminal (ttys) the user is connected to, also known as reads from, and we simply redirect the output from an echo command to his terminal. Because its session is connected to the terminal, he will read what we send to the stdin of his terminal device (hence, /dev/ttysxxx).
Everything in Unix is represented by a file, be it a device, a terminal, or anything we need access to. We also have some special files, such as /dev/null, which is a sinkhole - whatever you send to it gets lost:
gzarrelli:~$ echo "Hello" > /dev/null
gzarrelli:~$
And have a look at the following example too:
root:~$ ls
output_file.txtsortedto_sort
root:~$ mv output_file.txt /dev/null
root:~$ ls
to_sort
Great, there is enough to have fun, but it is just the beginning. There is a whole lot more to do with the file descriptors.






