






















































Keeping and representing data from a CSV file
Comma Separated Value (CSV) is a format to represent a table of values in plain text. It's often used to interact with data from spreadsheets. The specifications for CSV are described in RFC 4180, available at http://tools.ietf.org/html/rfc4180.
In this recipe, we will read a local CSV file called input.csv consisting of various names and their corresponding ages. Then, to do something useful with the data, we will find the oldest person.
Getting ready
Prepare a simple CSV file with a list of names and their corresponding ages. This can be done using a text editor or by exporting from a spreadsheet, as shown in the following figure:
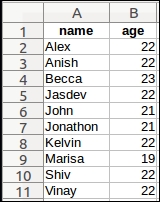
The raw input.csv file contains the following text:
$ cat input.csv name,age Alex,22 Anish,22 Becca,23 Jasdev,22 John,21 Jonathon,21 Kelvin,22 Marisa,19 Shiv,22 Vinay,22
The code also depends on the csv library. We may install the library through Cabal using the following command:
$ cabal install csv
How to do it...
- Import the
csvlibrary using the following line of code:import Text.CSV
- Define and implement
main, where we will read and parse the CSV file, as shown in the following code:main :: IO () main = do let fileName = "input.csv" input <- readFile fileName
- Apply
parseCSVto the filename to obtain a list of rows, representing the tabulated data. The output ofparseCSVisEither ParseError CSV, so ensure that we consider both theLeftandRightcases:let csv = parseCSV fileName input either handleError doWork csv handleError csv = putStrLn "error parsing" doWork csv = (print.findOldest.tail) csv
- Now we can work with the CSV data. In this example, we find and print the row containing the oldest person, as shown in the following code snippet:
findOldest :: [Record] -> Record findOldest [] = [] findOldest xs = foldl1 (\a x -> if age x > age a then x else a) xs age [a,b] = toInt a toInt :: String -> Int toInt = read - After running
main, the code should produce the following output:$ runhaskell Main.hs ["Becca", "23"]
Tip
We can also use the
parseCSVFromFilefunction to directly get the CSV representation from a filename instead of usingreadFilefollowedparseCSV.
How it works...
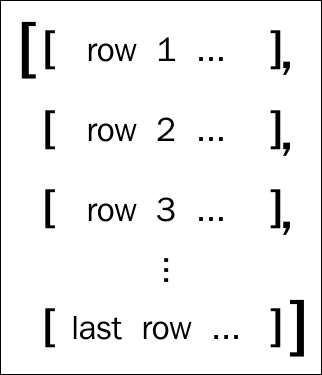
The CSV data structure in Haskell is represented as a list of records. Record is merely a list of Fields, and Field is a type synonym for String. In other words, it is a collection of rows representing a table, as shown in the following figure:
The parseCSV library function returns an Either type, with the Left side being a ParseError and the Right side being the list of lists. The Either l r data type is very similar to the Maybe a type which has the Just a or Nothing constructor.
We use the either function to handle the Left and Right cases. The Left case handles the error, and the Right case handles the actual work to be done on the data. In this recipe, the Right side is a Record. The fields in Record are accessible through any list operations such as head, last, !!, and so on.

