






















































A computation graph is the basic unit of computation in TensorFlow. A computation graph consists of nodes and edges. Each node represents an instance of tf.Operation, while each edge represents an instance of tf.Tensor that gets transferred between the nodes.
A model in TensorFlow contains a computation graph. First, you must create the graph with the nodes representing variables, constants, placeholders, and operations, and then provide the graph to the TensorFlow execution engine. The TensorFlow execution engine finds the first set of nodes that it can execute. The execution of these nodes starts the execution of the nodes that follow the sequence of the computation graph.
Thus, TensorFlow-based programs are made up of performing two types of activities on computation graphs:
- Defining the computation graph
- Executing the computation graph
A TensorFlow program starts execution with a default graph. Unless another graph is explicitly specified, a new node gets implicitly added to the default graph. Explicit access to the default graph can be obtained using the following command:
graph = tf.get_default_graph()
For example, the following computation graph represents the addition of three inputs to produce the output, that is,  :
:
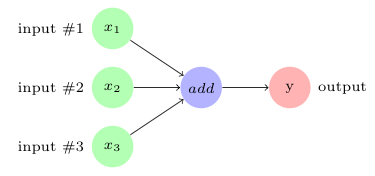
In TensorFlow, the add operation node in the preceding diagram would correspond to the code y = tf.add( x1 + x2 + x3 ).
The variables, constants, and placeholders get added to the graph as and when they are created. After defining the computation graph, a session object is instantiated that executes the operation objects and evaluates the tensor objects.
Let's define and execute a computation graph to calculate  , just like we saw in the preceding example:
, just like we saw in the preceding example:
# Linear Model y = w * x + b
# Define the model parameters
w = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
# Define model input and output
x = tf.placeholder(tf.float32)
y = w * x + b
output = 0
with tf.Session() as tfs:
# initialize and print the variable y
tf.global_variables_initializer().run()
output = tfs.run(y,{x:[1,2,3,4]})
print('output : ',output)
Creating and using a session in the with block ensures that the session is automatically closed when the block is finished. Otherwise, the session has to be explicitly closed with the tfs.close() command, where tfs is the session name.






















