























































Sparse autoencoder
In this section, we will look at how adding sparsity to the cost function helps in reducing the cost of training. Most of the code remains the same, but the primary changes are in the way the cost function is calculated.
KL divergence
Let's first try to understand KL divergence, which is used to add sparsity to the cost function.
We can think of a neuron as active (or firing) if a neuron's output value is close to one, and inactive if its output value is close to zero. We would like to constrain the neurons to be inactive most of the time. This discussion assumes a sigmoid activation function. Recall that a(2)j denotes the activation of the hidden unit j in the autoencoder. This notation does not state explicitly what the input x was that led to this activation. We will write a(2)j(x) to denote the activation of the hidden unit when the network is given a specific input x. Further, let
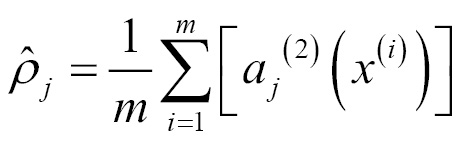
be the average activation of the hidden unit j (averaged over the training set). We would...






















