






















































The fundamentals of data analysis
Data analysis is a highly iterative process involving collection, preparation (wrangling), exploratory data analysis (EDA), and drawing conclusions. During an analysis, we will frequently revisit each of these steps. The following diagram depicts a generalized workflow:
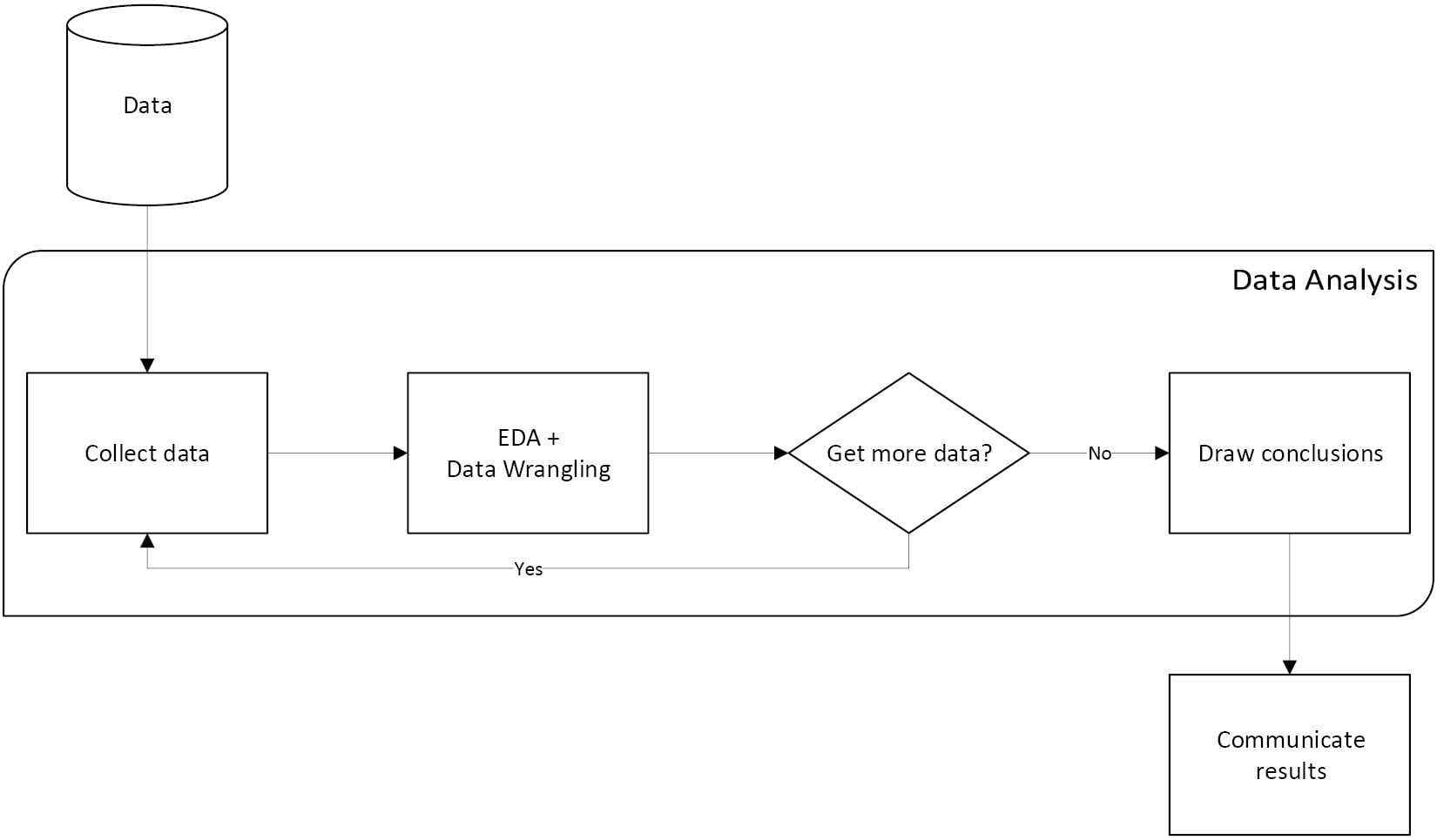
Figure 1.2 – The data analysis workflow
Over the next few sections, we will get an overview of each of these steps, starting with data collection. In practice, this process is heavily skewed toward the data preparation side. Surveys have found that although data scientists enjoy the data preparation side of their job the least, it makes up 80% of their work (https://www.forbes.com/sites/gilpress/2016/03/23/data-preparation-most-time-consuming-least-enjoyable-data-science-task-survey-says/). This data preparation step is where pandas really shines.
Data collection
Data collection is the natural first step for any data analysis—we can't analyze data we don't have. In reality, our analysis can begin even before we have the data. When we decide what we want to investigate or analyze, we have to think about what kind of data we can collect that will be useful for our analysis. While data can come from anywhere, we will explore the following sources throughout this book:
- Web scraping to extract data from a website's HTML (often with Python packages such as
selenium,requests,scrapy, andbeautifulsoup) - Application programming interfaces (APIs) for web services from which we can collect data with HTTP requests (perhaps using
cURLor therequestsPython package) - Databases (data can be extracted with SQL or another database-querying language)
- Internet resources that provide data for download, such as government websites or Yahoo! Finance
- Log files
Important note
Chapter 2, Working with Pandas DataFrames, will give us the skills we need to work with the aforementioned data sources. Chapter 12, The Road Ahead, provides numerous resources for finding data sources.
We are surrounded by data, so the possibilities are limitless. It is important, however, to make sure that we are collecting data that will help us draw conclusions. For example, if we are trying to determine whether hot chocolate sales are higher when the temperature is lower, we should collect data on the amount of hot chocolate sold and the temperatures each day. While it might be interesting to see how far people traveled to get the hot chocolate, it's not relevant to our analysis.
Don't worry too much about finding the perfect data before beginning an analysis. Odds are, there will always be something we want to add/remove from the initial dataset, reformat, merge with other data, or change in some way. This is where data wrangling comes into play.
Data wrangling
Data wrangling is the process of preparing the data and getting it into a format that can be used for analysis. The unfortunate reality of data is that it is often dirty, meaning that it requires cleaning (preparation) before it can be used. The following are some issues we may encounter with our data:
- Human errors: Data is recorded (or even collected) incorrectly, such as putting
100instead of1000, or typos. In addition, there may be multiple versions of the same entry recorded, such asNew York City,NYC, andnyc. - Computer error: Perhaps we weren't recording entries for a while (missing data).
- Unexpected values: Maybe whoever was recording the data decided to use a question mark for a missing value in a numeric column, so now all the entries in the column will be treated as text instead of numeric values.
- Incomplete information: Think of a survey with optional questions; not everyone will answer them, so we will have missing data, but not due to computer or human error.
- Resolution: The data may have been collected per second, while we need hourly data for our analysis.
- Relevance of the fields: Often, data is collected or generated as a product of some process rather than explicitly for our analysis. In order to get it to a usable state, we will have to clean it up.
- Format of the data: Data may be recorded in a format that isn't conducive to analysis, which will require us to reshape it.
- Misconfigurations in the data-recording process: Data coming from sources such as misconfigured trackers and/or webhooks may be missing fields or passed in the wrong order.
Most of these data quality issues can be remedied, but some cannot, such as when the data is collected daily and we need it on an hourly resolution. It is our responsibility to carefully examine our data and handle any issues so that our analysis doesn't get distorted. We will cover this process in depth in Chapter 3, Data Wrangling with Pandas, and Chapter 4, Aggregating Pandas DataFrames.
Once we have performed an initial cleaning of the data, we are ready for EDA. Note that during EDA, we may need some additional data wrangling: these two steps are highly intertwined.
Exploratory data analysis
During EDA, we use visualizations and summary statistics to get a better understanding of the data. Since the human brain excels at picking out visual patterns, data visualization is essential to any analysis. In fact, some characteristics of the data can only be observed in a plot. Depending on our data, we may create plots to see how a variable of interest has evolved over time, compare how many observations belong to each category, find outliers, look at distributions of continuous and discrete variables, and much more. In Chapter 5, Visualizing Data with Pandas and Matplotlib, and Chapter 6, Plotting with Seaborn and Customization Techniques, we will learn how to create these plots for both EDA and presentation.
Important note
Data visualizations are very powerful; unfortunately, they can often be misleading. One common issue stems from the scale of the y-axis because most plotting tools will zoom in by default to show the pattern up close. It would be difficult for software to know what the appropriate axis limits are for every possible plot; therefore, it is our job to properly adjust the axes before presenting our results. You can read about some more ways that plots can be misleading at https://venngage.com/blog/misleading-graphs/.
In the workflow diagram we saw earlier (Figure 1.2), EDA and data wrangling shared a box. This is because they are closely tied:
- Data needs to be prepped before EDA.
- Visualizations that are created during EDA may indicate the need for additional data cleaning.
- Data wrangling uses summary statistics to look for potential data issues, while EDA uses them to understand the data. Improper cleaning will distort the findings when we're conducting EDA. In addition, data wrangling skills will be required to get summary statistics across subsets of the data.
When calculating summary statistics, we must keep the type of data we collected in mind. Data can be quantitative (measurable quantities) or categorical (descriptions, groupings, or categories). Within these classes of data, we have further subdivisions that let us know what types of operations we can perform on them.
For example, categorical data can be nominal, where we assign a numeric value to each level of the category, such as on = 1/off = 0. Note that the fact that on is greater than off is meaningless because we arbitrarily chose those numbers to represent the states on and off. When there is a ranking among the categories, they are ordinal, meaning that we can order the levels (for instance, we can have low < medium < high).
Quantitative data can use an interval scale or a ratio scale. The interval scale includes things such as temperature. We can measure temperatures in Celsius and compare the temperatures of two cities, but it doesn't mean anything to say one city is twice as hot as the other. Therefore, interval scale values can be meaningfully compared using addition/subtraction, but not multiplication/division. The ratio scale, then, are those values that can be meaningfully compared with ratios (using multiplication and division). Examples of the ratio scale include prices, sizes, and counts.
When we complete our EDA, we can decide on the next steps by drawing conclusions.
Drawing conclusions
After we have collected the data for our analysis, cleaned it up, and performed some thorough EDA, it is time to draw conclusions. This is where we summarize our findings from EDA and decide the next steps:
- Did we notice any patterns or relationships when visualizing the data?
- Does it look like we can make accurate predictions from our data? Does it make sense to move to modeling the data?
- Should we handle missing data points? How?
- How is the data distributed?
- Does the data help us answer the questions we have or give insight into the problem we are investigating?
- Do we need to collect new or additional data?
If we decide to model the data, this falls under machine learning and statistics. While not technically data analysis, it is usually the next step, and we will cover it in Chapter 9, Getting Started with Machine Learning in Python, and Chapter 10, Making Better Predictions – Optimizing Models. In addition, we will see how this entire process will work in practice in Chapter 11, Machine Learning Anomaly Detection. As a reference, in the Machine learning workflow section in the Appendix, there is a workflow diagram depicting the full process from data analysis to machine learning. Chapter 7, Financial Analysis – Bitcoin and the Stock Market, and Chapter 8, Rule-Based Anomaly Detection, will focus on drawing conclusions from data analysis, rather than building models.
The next section will be a review of statistics; those with knowledge of statistics can skip ahead to the Setting up a virtual environment section.











