






















































Deep deterministic policy gradient
DDPG is an off-policy, model-free algorithm, designed for environments where the action space is continuous. In the previous chapter, we learned how the actor-critic method works. DDPG is an actor-critic method where the actor estimates the policy using the policy gradient, and the critic evaluates the policy produced by the actor using the Q function.
DDPG uses the policy network as an actor and deep Q network as a critic. One important difference between the DPPG and actor-critic algorithms we learned in the previous chapter is that DDPG tries to learn a deterministic policy instead of a stochastic policy.
First, we will get an intuitive understanding of how DDPG works and then we will look into the algorithm in detail.
An overview of DDPG
DDPG is an actor-critic method that takes advantage of both the policy-based method and the value-based method. It uses a deterministic policy  instead of a stochastic policy
instead of a stochastic policy 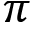 .
.




