






















































Move semantics explained
Move semantics is a concept introduced in C++11 that, in my experience, is quite hard to grasp, even by experienced programmers. Therefore, I will try to give you an in-depth explanation of how it works, when the compiler utilizes it, and, most importantly, why it is needed.
Essentially, the reason C++ even has the concept of move semantics, whereas most other languages don't, is a result of it being a value-based language, as discussed in Chapter 1, A Brief Introduction to C++. If C++ did not have move semantics built in, the advantages of value-based semantics would get lost in many cases and programmers would have to perform one of the following trade-offs:
- Performing redundant deep-cloning operations with high performance costs
- Using pointers for objects like Java does, losing the robustness of value semantics
- Performing error-prone swapping operations at the cost of readability
We do not want any of these, so let's have a look at how move semantics help us.
Copy-construction, swap, and move
Before we go into the details of move, I will first explain and illustrate the differences between copy-constructing an object, swapping two objects, and move-constructing an object.
Copy-constructing an object
When copying an object handling a resource, a new resource needs to be allocated, and the resource from the source object needs to be copied so that the two objects are completely separated. Imagine that we have a class, Widget, that references some sort of resource that needs to be allocated on construction. The following code default-constructs a Widget object and then copy-constructs a new instance:
auto a = Widget{};
auto b = a; // Copy-construction
The resource allocations that are carried out are illustrated in the following figure:
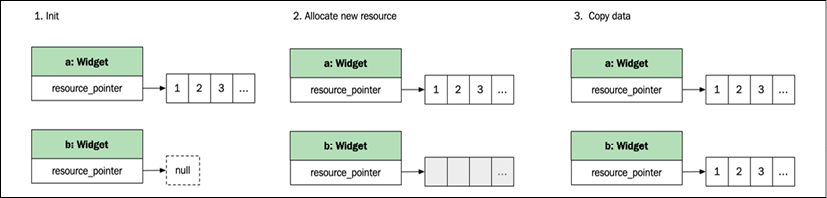
Figure 2.1: Copying an object with resources
The allocation and copying are slow processes, and, in many cases, the source object isn't needed anymore. With move semantics, the compiler detects cases like these where the old object is not tied to a variable, and instead performs a move operation.
Swapping two objects
Before move semantics were added in C++11, swapping the content of two objects was a common way to transfer data without allocating and copying. As shown next, objects simply swap their content with each other:
auto a = Widget{};
auto b = Widget{};
std::swap(a, b);
The following figure illustrates the process:
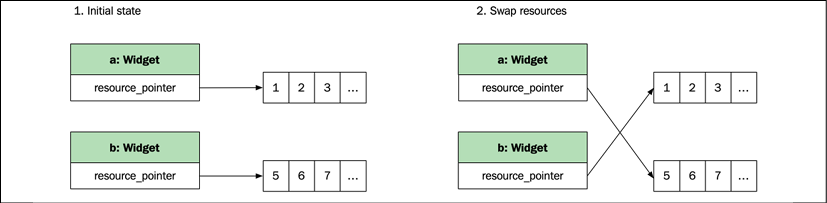
Figure 2.2: Swapping resources between two objects
The std::swap() function is a simple but useful utility used in the copy-and-swap idiom covered later in this chapter.
Move-constructing an object
When moving an object, the destination object steals the resource straight from the source object, and the source object is reset.
As you can see, it is very similar to swapping, except that the moved-from object does not have to receive the resources from the moved-to object:
auto a = Widget{};
auto b = std::move(a); // Tell the compiler to move the resource into b
The following figure illustrates the process:
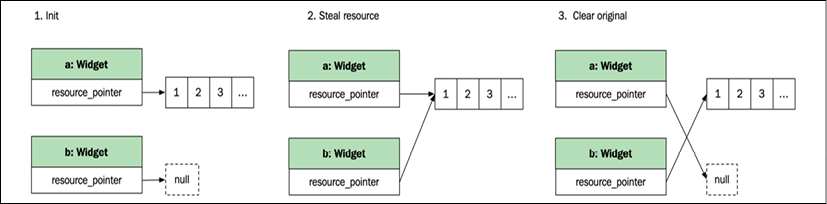
Figure 2.3: Moving resources from one object to another
Although the source object is reset, it's still in a valid state. This resetting of the source object is not something that the compiler does automatically for us. Instead, we need to implement the resetting in the move constructor to ensure that the object is in a valid state that can be destroyed or assigned to. We will talk more about valid states later on in this chapter.
Moving objects only makes sense if the object type owns a resource of some sort (the most common case being heap-allocated memory). If all data is contained within the object, the most efficient way to move an object is to just copy it.
Now that you have a basic grasp of move semantics, let's go into the details.
Resource acquisition and the rule of five
To fully understand move semantics, we need to go back to the basics of classes and resource acquisition in C++. One of the basic concepts in C++ is that a class should completely handle its resources. This means that when a class is copied, moved, copy-assigned, move-assigned, or destructed, the class should make sure its resources are handled accordingly. The necessity of implementing these five functions is commonly referred to as the rule of five.
Let's have a look at how the rule of five can be implemented in a class handling an allocated resource. In the Buffer class defined in the following code snippet, the allocated resource is an array of floats pointed at by the raw pointer ptr_:
class Buffer {
public:
// Constructor
Buffer(const std::initializer_list<float>& values) : size_{values.size()} {
ptr_ = new float[values.size()];
std::copy(values.begin(), values.end(), ptr_);
}
auto begin() const { return ptr_; }
auto end() const { return ptr_ + size_; }
/* The 5 special functions are defined below */
private:
size_t size_{0};
float* ptr_{nullptr};
};
In this case, the handled resource is a block of memory allocated in the constructor of the Buffer class. Memory is probably the most common resource for classes to handle, but a resource can be so much more: a mutex, a handle for a texture on the graphics card, a thread handle, and so on.
The five functions that are referred to in the rule of five have been left out and will follow next. We will begin with the copy-constructor, copy-assignment, and destructor, which all need to be involved in the resource handling:
// 1. Copy constructor
Buffer::Buffer(const Buffer& other) : size_{other.size_} {
ptr_ = new float[size_];
std::copy(other.ptr_, other.ptr_ + size_, ptr_);
}
// 2. Copy assignment
auto& Buffer::operator=(const Buffer& other) {
delete [] ptr_;
ptr_ = new float[other.size_];
size_ = other.size_;
std::copy(other.ptr_, other.ptr_ + size_, ptr_);
return *this;
}
// 3. Destructor
Buffer::~Buffer() {
delete [] ptr_; // OK, it is valid to delete a nullptr
ptr_ = nullptr;
}
Before the introduction of move semantics in C++11, these three functions were usually referred to as the rule of three. The copy-constructor, copy-assignment, and destructor are invoked in the following cases:
auto func() {
// Construct
auto b0 = Buffer({0.0f, 0.5f, 1.0f, 1.5f});
// 1. Copy-construct
auto b1 = b0;
// 2. Copy-assignment as b0 is already initialized
b0 = b1;
} // 3. End of scope, the destructors are automatically invoked
Although a correct implementation of these three functions is all that is required for a class to handle its internal resources, two problems arise:
- Resources that cannot be copied: In the
Bufferclass example, our resource can be copied, but there are other types of resources where a copy wouldn't make sense. For example, the resource contained in a class might be astd::thread, a network connection, or something else that it's not possible to copy. In these cases, we cannot pass around the object. - Unnecessary copies: If we return our
Bufferclass from a function, the entire array needs to be copied. (The compiler optimizes away the copy in some cases, though, but let's ignore that for now.)
The solution to these problems is move semantics. In addition to the copy-constructor and copy-assignment, we can add a move-constructor and a move-assignment operator to our class. Instead of taking a const reference (const Buffer&) as a parameter, the move versions accept a Buffer&& object.
The && modifier indicates that the parameter is an object that we intend to move from instead of copying it. Speaking in C++ terms, this is called an rvalue, and we will talk a little bit more about those later.
Whereas the copy() functions copy an object, the move equivalents are intended to move resources from one object to another, freeing the moved-from object from the resource.
This is how we would extend our Buffer class with the move-constructor and move-assignment. As you can see, these functions will not throw any exceptions and can therefore be marked as noexcept. This is because, as opposed to the copy-constructor/copy-assignment, they do not allocate memory or do something that might throw exceptions:
// 4. Move constructor
Buffer::Buffer(Buffer&& other) noexcept : size_{other.size_}, ptr_{other.ptr_} {
other.ptr_ = nullptr;
other.size_ = 0;
}
// 5. Move assignment
auto& Buffer::operator=(Buffer&& other) noexcept {
ptr_ = other.ptr_;
size_ = other.size_;
other.ptr_ = nullptr;
other.size_ = 0;
return *this;
}
Now, when the compiler detects that we perform what seems to be a copy, such as returning a Buffer from a function, but the copied-from value isn't used anymore, it will utilize the no-throw move-constructor/move-assignment instead of copying.
This is pretty sweet; the interface remains as clear as when copying but, under the hood, the compiler has performed a simple move. Thus, the programmer does not need to use any esoteric pointers or out-parameters in order to avoid a copy; as the class has move semantics implemented, the compiler handles this automatically.
Do not forget to mark your move-constructors and move-assignment operators as noexcept (unless they might throw an exception, of course). Not marking them noexcept prevents standard library containers and algorithms from utilizing them, instead resorting to using a regular copy/assignment under certain conditions.
To be able to know when the compiler is allowed to move an object instead of copying, an understanding of rvalues is necessary.
Named variables and rvalues
So, when is the compiler allowed to move objects instead of copying? As a short answer, the compiler moves an object when the object can be categorized as an rvalue. The term rvalue might sound complicated, but in essence it is just an object that is not tied to a named variable, for either of the following reasons:
- It's coming straight out of a function
- We make a variable an rvalue by using
std::move()
The following example demonstrates both of these scenarios:
// The object returned by make_buffer is not tied to a variable
x = make_buffer(); // move-assigned
// The variable "x" is passed into std::move()
y = std::move(x); // move-assigned
I will also use the terms lvalue and named variable interchangeably in this book. An lvalue corresponds to objects that we can refer to by name in our code.
Now we will make this a little more advanced by using a member variable of type std::string in a class. The following Button class will serve as an example:
class Button {
public:
Button() {}
auto set_title(const std::string& s) {
title_ = s;
}
auto set_title(std::string&& s) {
title_ = std::move(s);
}
std::string title_;
};
We also need a free function returning a title and a Button variable:
auto get_ok() {
return std::string("OK");
}
auto button = Button{};
Given these prerequisites, let's look at a few cases of copying and moving in detail:
- Case 1:
Button::title_is copy-assigned because thestringobject is tied to the variablestr:auto str = std::string{"OK"}; button.set_title(str); // copy-assigned - Case 2:
Button::title_is move-assigned becausestris passed throughstd::move():auto str = std::string{"OK"}; button.set_title(std::move(str)); // move-assigned - Case 3:
Button::title_is move-assigned because the newstd::stringobject is coming straight out of a function:button.set_title(get_ok()); // move-assigned - Case 4:
Button::title_is copy-assigned because thestringobject is tied tos(this is the same as Case 1):auto str = get_ok(); button.set_title(str); // copy-assigned - Case 5:
Button::title_is copy-assigned becausestris declaredconstand therefore is not allowed to mutate:const auto str = get_ok(); button.set_title(std::move(str)); // copy-assigned
As you can see, determining whether an object is moved or copied is quite simple. If it has a variable name, it is copied; otherwise, it is moved. If you are using std::move() to move a named object, the object cannot be declared const.
Default move semantics and the rule of zero
This section discusses automatically generated copy-assignment operators. It's important to know that the generated function does not have strong exception guarantees. Therefore, if an exception is thrown during the copy-assignment, the object might end up in a state where it is only partially copied.
As with the copy-constructor and copy-assignment, the move-constructor and move-assignment can be generated by the compiler. Although some compilers allow themselves to automatically generate these functions under certain conditions (more about this later), we can simply force the compiler to generate them by using the default keyword.
In the case of the Button class, which doesn't manually handle any resources, we can simply extend it like this:
class Button {
public:
Button() {} // Same as before
// Copy-constructor/copy-assignment
Button(const Button&) = default;
auto operator=(const Button&) -> Button& = default;
// Move-constructor/move-assignment
Button(Button&&) noexcept = default;
auto operator=(Button&&) noexcept -> Button& = default;
// Destructor
~Button() = default;
// ...
};
To make it even simpler, if we do not declare any custom copy-constructor/copy-assignment or destructor, the move-constructors/move-assignments are implicitly declared, meaning that the first Button class actually handles everything:
class Button {
public:
Button() {} // Same as before
// Nothing here, the compiler generates everything automatically!
// ...
};
It's easy to forget that adding just one of the five functions prevents the compiler from generating the other ones. The following version of the Button class has a custom destructor. As a result, the move operators are not generated, and the class will always be copied:
class Button {
public:
Button() {}
~Button()
std::cout << "destructed\n"
}
// ...
};
Let's see how we can use this insight into generated functions when implementing application classes.
Rule of zero in a real code base
In practice, the cases where you have to write your own copy/move-constructors, copy/move-assignments, and constructors should be very few. Writing your classes so that they don't require any of these special member functions to be explicitly written (or default - declared) is often referred to as the rule of zero. This means that if a class in the application code base is required to have any of these functions written explicitly, that piece of code would probably be better off in the library part of your code base.
Later on in this book, we will discuss std::optional, which is a handy utility class for dealing with optional members when applying the rule of zero.
A note on empty destructors
Writing an empty destructor can prevent the compiler from implementing certain optimizations. As you can see in the following snippets, copying an array of a trivial class with an empty destructor yields the same (non-optimized) assembler code as copying with a handcrafted for-loop. The first version uses an empty destructor with std::copy():
struct Point {
int x_, y_;
~Point() {} // Empty destructor, don't use!
};
auto copy(Point* src, Point* dst) {
std::copy(src, src+64, dst);
}
The second version uses a Point class with no destructor but with a handcrafted for-loop:
struct Point {
int x_, y_;
};
auto copy(Point* src, Point* dst) {
const auto end = src + 64;
for (; src != end; ++src, ++dst) {
*dst = *src;
}
}
Both versions generate the following x86 assembler, which corresponds to a simple loop:
xor eax, eax
.L2:
mov rdx, QWORD PTR [rdi+rax]
mov QWORD PTR [rsi+rax], rdx
add rax, 8
cmp rax, 512
jne .L2
rep ret
However, if we remove the destructor or declare the destructor default, the compiler optimizes std::copy() to utilize memmove() instead of a loop:
struct Point {
int x_, y_;
~Point() = default; // OK: Use default or no constructor at all
};
auto copy(Point* src, Point* dst) {
std::copy(src, src+64, dst);
}
The preceding code generates the following x86 assembler, with the memmove() optimization:
mov rax, rdi
mov edx, 512
mov rdi, rsi
mov rsi, rax
jmp memmove
The assembler was generated using GCC 7.1 in Compiler Explorer, which is available at https://godbolt.org/.
To summarize, use default destructors or no destructors at all in favor of empty destructors to squeeze a little bit more performance out of your application.
A common pitfall – moving non-resources
There is one common pitfall when using default-created move-assignments: classes that mix fundamental types with more advanced compound types. As opposed to compound types, fundamental types (such as int, float, and bool) are simply copied when moved, as they don't handle any resources.
When a simple type is mixed with a resource-owning type, the move-assignment becomes a mixture of move and copy.
Here is an example of a class that will fail:
class Menu {
public:
Menu(const std::initializer_list<std::string>& items) : items_{items} {}
auto select(int i) {
index_ = i;
}
auto selected_item() const {
return index_ != -1 ? items_[index_] : "";
}
// ...
private:
int index_{-1}; // Currently selected item
std::vector<std::string> items_;
};
The Menu class will have undefined behavior if it's used like this:
auto a = Menu{"New", "Open", "Close", "Save"};
a.select(2);
auto b = std::move(a);
auto selected = a.selected_item(); // crash
The undefined behavior happens as the items_ vector is moved and is therefore empty. The index_, on the other hand, is copied, and therefore still has the value 2 in the moved-from object a. When selected_item() is called, the function will try to access items_ at index 2 and the program will crash.
In these cases, the move-constructor/assignment is better implemented by simply swapping the members, like this:
Menu(Menu&& other) noexcept {
std::swap(items_, other.items_);
std::swap(index_, other.index_);
}
auto& operator=(Menu&& other) noexcept {
std::swap(items_, other.items_);
std::swap(index_, other.index_);
return *this;
}
This way, the Menu class can be safely moved while still preserving the no-throw guarantee. In Chapter 8, Compile-Time Programming, you will learn how to take advantage of reflection techniques in C++ in order to automate the process of creating move-constructor/assignment functions that swap the elements.
Applying the && modifier to class member functions
In addition to being applied to objects, you can also add the && modifier to a member function of a class, just as you can apply a const modifier to a member function. As with the const modifier, a member function that has the && modifier will only be considered by overload resolution if the object is an rvalue:
struct Foo {
auto func() && {}
};
auto a = Foo{};
a.func(); // Doesn't compile, 'a' is not an rvalue
std::move(a).func(); // Compiles
Foo{}.func(); // Compiles
It might seem odd that anyone would ever want this behavior, but there are use cases. We will investigate one of them in Chapter 10, Proxy Objects and Lazy Evaluation.
Don't move when copies are elided anyway
It might be tempting to use std::move() when returning a value from a function, like this:
auto func() {
auto x = X{};
// ...
return std::move(x); // Don't, RVO is prevented
}
However, unless x is a move-only type, you shouldn't be doing this. This usage of std::move() prevents the compiler from using return value optimization (RVO) and thereby completely elides the copying of x, which is more efficient than moving it. So, when returning a newly created object by value, don't use std::move(); instead, just return the object:
auto func() {
auto x = X{};
// ...
return x; // OK
}
This particular example where a named object is elided is usually called NRVO, or Named-RVO. RVO and NRVO are implemented by all major C++ compilers today. If you want to read more about RVO and copy elision, you can find a detailed summary at https://en.cppreference.com/w/cpp/language/copy_elision.
Pass by value when applicable
Consider a function that converts a std::string to lowercase. In order to use the move-constructor where applicable, and the copy-constructor otherwise, it may seem like two functions are required:
// Argument s is a const reference
auto str_to_lower(const std::string& s) -> std::string {
auto clone = s;
for (auto& c: clone) c = std::tolower(c);
return clone;
}
// Argument s is an rvalue reference
auto str_to_lower(std ::string&& s) -> std::string {
for (auto& c: s) c = std::tolower(c);
return s;
}
However, by taking the std::string by value instead, we can write one function that covers both cases:
auto str_to_lower(std::string s) -> std::string {
for (auto& c: s) c = std::tolower(c);
return s;
}
Let's see why this implementation of str_to_lower() avoids unnecessary copying where possible. When passed a regular variable, shown as follows, the content of str is copy-constructed into s prior to the function call, and then move-assigned back to str when the functions returns:
auto str = std::string{"ABC"};
str = str_to_lower(str);
When passed an rvalue, as shown below, the content of str is move-constructed into s prior to the function call, and then move-assigned back to str when the function returns. Therefore, no copy is made through the function call:
auto str = std::string{"ABC"};
str = str_to_lower(std::move(str));
At first sight, it seems like this technique could be applicable to all parameters. However, this pattern is not always optimal, as you will see next.
Cases where pass-by-value is not applicable
Sometimes this pattern of accept-by-value-then-move is actually a pessimization. For example, consider the following class where the function set_data() will keep a copy of the argument passed to it:
class Widget {
std::vector<int> data_{};
// ...
public:
void set_data(std::vector<int> x) {
data_ = std::move(x);
}
};
Assume we call set_data() and pass it an lvalue, like this:
auto v = std::vector<int>{1, 2, 3, 4};
widget.set_data(v); // Pass an lvalue
Since we are passing a named object, v, the code will copy-construct a new std::vector object, x, and then move-assign that object into the data_ member. Unless we pass an empty vector object to set_data(), the std::vector copy-constructor will perform a heap allocation for its internal buffer.
Now compare this with the following version of set_data() optimized for lvalues:
void set_data(const std::vector<int>& x) {
data_ = x; // Reuse internal buffer in data_ if possible
}
Here, there will only be a heap allocation inside the assignment operator if the capacity of the current vector, data_, is smaller than the size of the source object, x. In other words, the internal pre-allocated buffer of data_ can be reused in the assignment operator in many cases and save us from an extra heap allocation.
If we find it necessary to optimize set_data() for lvalues and rvalues, it's better, in this case, to provide two overloads:
void set_data(const std::vector<int>& x) {
data_ = x;
}
void set_data(std::vector<int>&& x) noexcept {
data_ = std::move(x);
}
The first version is optimal for lvalues and the second version for rvalues.
Finally, we will now look at a scenario where we can safely pass by value without worrying about the pessimization just demonstrated.
Moving constructor parameters
When initializing class members in a constructor, we can safely use the pass-by-value-then-move pattern. During the construction of a new object, there is no chance that there are pre-allocated buffers that could have been utilized to avoid heap allocations. What follows is an example of a class with one std::vector member and a constructor to demonstrate this pattern:
class Widget {
std::vector<int> data_;
public:
Widget(std::vector<int> x) // By value
: data_{std::move(x)} {} // Move-construct
// ...
};
We will now shift our focus to a topic that cannot be considered modern C++ but is frequently discussed even today.











