






















































We began our Bayesian journey with a very brief discussion about statistical modeling, probability theory, and the introduction of Bayes' theorem. We then used the coin-flipping problem as an excuse to introduce basic aspects of Bayesian modeling and data analysis. We used this classic example to convey some of the most important ideas of Bayesian statistics, such as using probability distributions to build models and represent uncertainties. We tried to demystify the use of priors and put them on an equal footing with other elements that are part of the modeling process, such as the likelihood, or even more meta-questions, such as why we are trying to solve a particular problem in the first place. We ended the chapter by discussing the interpretation and communication of the results of a Bayesian analysis.
Figure 1.8 is based on one from Sumio Watanabe and summarizes the Bayesian workflow as described in this chapter:
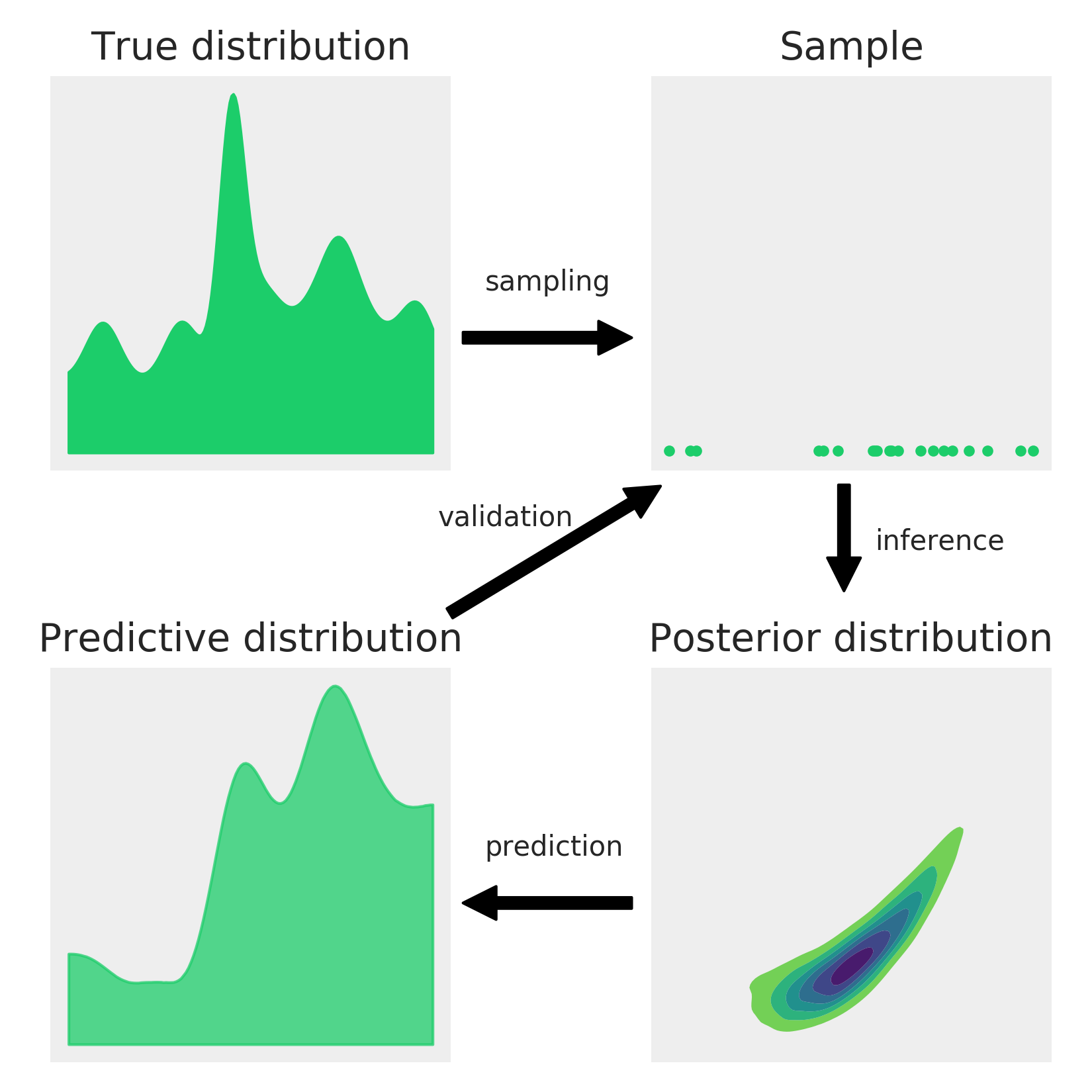
We assume there is a True distribution that in general is unknown (and in principle also unknowable), from which we get a finite sample, either by doing an experiment, a survey, an observation, or a simulation. In order to learn something from the True distribution, given that we have only observed a sample, we build a probabilistic model. A probabilistic model has two basic ingredients: a prior and a likelihood. Using the model and the sample, we perform Bayesian Inference and obtain a Posterior distribution; this distribution encapsulates all the information about a problem, given our model and data. From a Bayesian perspective, the posterior distribution is the main object of interest and everything else is derived from it, including predictions in the form of a Posterior Predictive Distribution. As the Posterior distribution (and any other derived quantity from it) is a consequence of the model and data, the usefulness of Bayesian inferences are restricted by the quality of models and data. One way to evaluate our model is by comparing the Posterior Predictive Distribution with the finite sample we got in the first place. Notice that the Posterior distribution is a distribution of the parameters in a model (conditioned on the observed samples), while the Posterior Predictive Distribution is a distribution of the predicted samples (averaged over the posterior distribution). The process of model validation is of crucial importance not because we want to be sure we have the right model, but because we know we almost never have the right model. We check models to evaluate whether they are useful enough in a specific context and, if not, to gain insight into how to improve them.
In this chapter, we have briefly summarized the main aspects of doing Bayesian data analysis. Throughout the rest of this book, we will revisit these ideas to really absorb them and use them as the scaffold of more advanced concepts. In the next chapter, we will introduce PyMC3, which is a Python library for Bayesian modeling and Probabilistic Machine Learning, and ArviZ, which is a Python library for the exploratory analysis of Bayesian models.















