






















































Compiling code
As mentioned earlier, if the code contains chip-incomprehensible strings or text-based functions, the compiler must first convert them to absolute addresses that the chip can understand and then store them in separate sections. It is also necessary to translate the textual script into native code or machine code that the chip can recognize. How does this work in practice?
In the case of Windows x86, the instructions executed on the assembly code are translated according to the x86 instruction set. The textual instructions are translated and encoded into machine code that the chip understands. Interested readers can search for x86 Instruction Set on Google to find the full instruction table or even encode it manually without relying on a compiler.
Once the compiler has completed the aforementioned block packaging, the next stage is to extract and encode the textual instructions from the script, one by one, according to the x86 instruction set, and write them into the .text section that is used to store the machine code.
As shown in Figure 1.3, the dashed box is the assembly code in the text type obtained from compiling the C/C++ code:
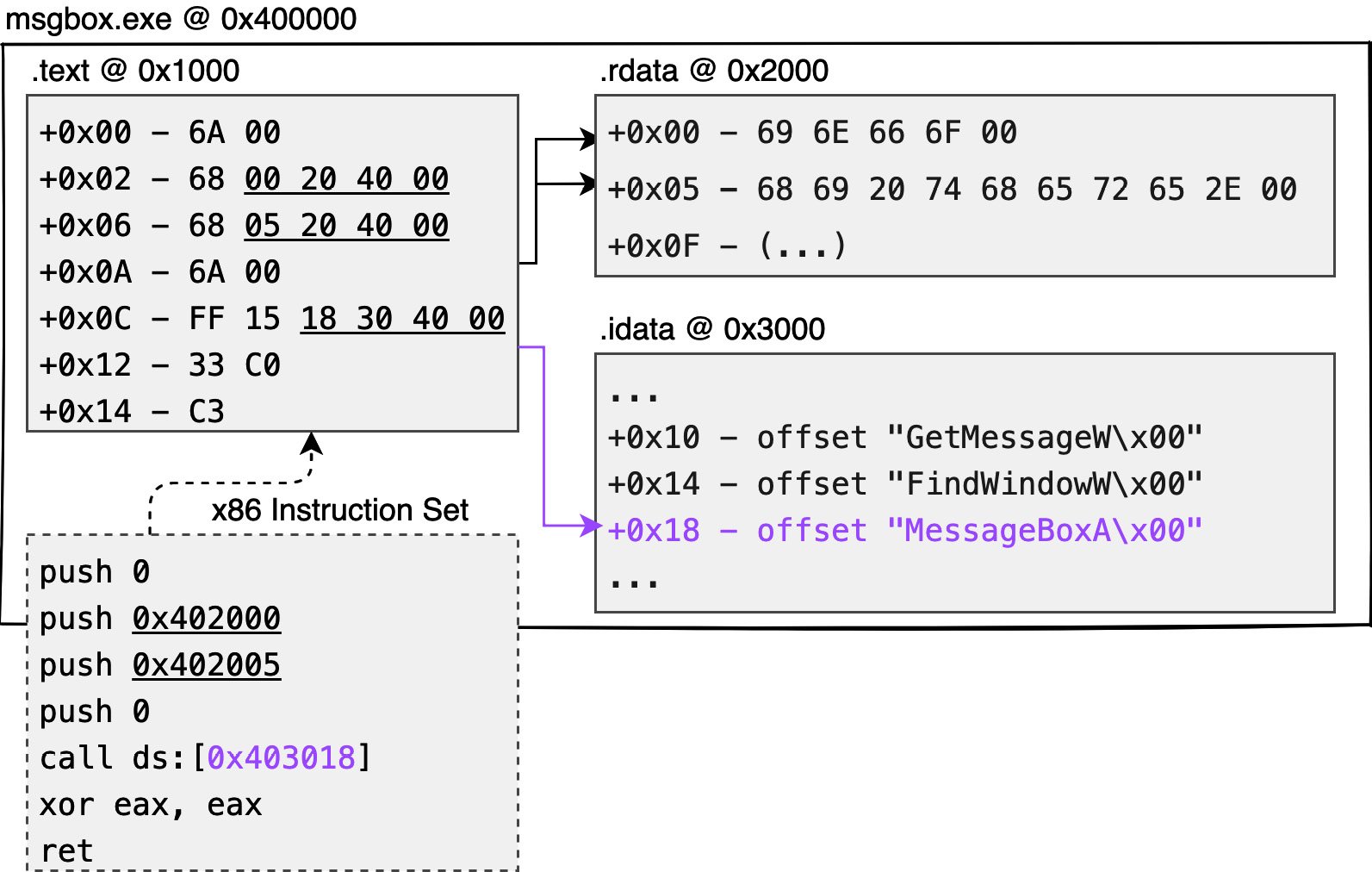
Figure 1.3 – Native code generation
You can see the first instruction is push 0, which pushes 1 byte of data onto the stack (saved as 4 bytes), and 6A 00 is used to represent this instruction. The push 0x402005 instruction pushes 4 bytes onto the stack at once, so push 68 50 20 40 00 is used to achieve a longer push. call ds:[0x403018] is the address of the 4 bytes, and the long call of machine code, FF 15 18 30 40 00, is used to represent this instruction.
Although Figure 1.3 shows the memory distribution of the dynamic msgbox.exe file, the file produced by the compiler is not yet an executable PE file. Rather, it is a file called a Common Object File Format (COFF) or an object file, as some people call it, which is a wrapper file specifically designed to record the various sections produced by the compiler. The following figure shows the COFF file obtained by compiling and assembling the source code with the gcc -c command, and viewing its structure with a well-known tool, PEview.
As shown in Figure 1.4, there is an IMAGE_FILE_HEADER structure at the beginning of the COFF file to record how many sections are included:
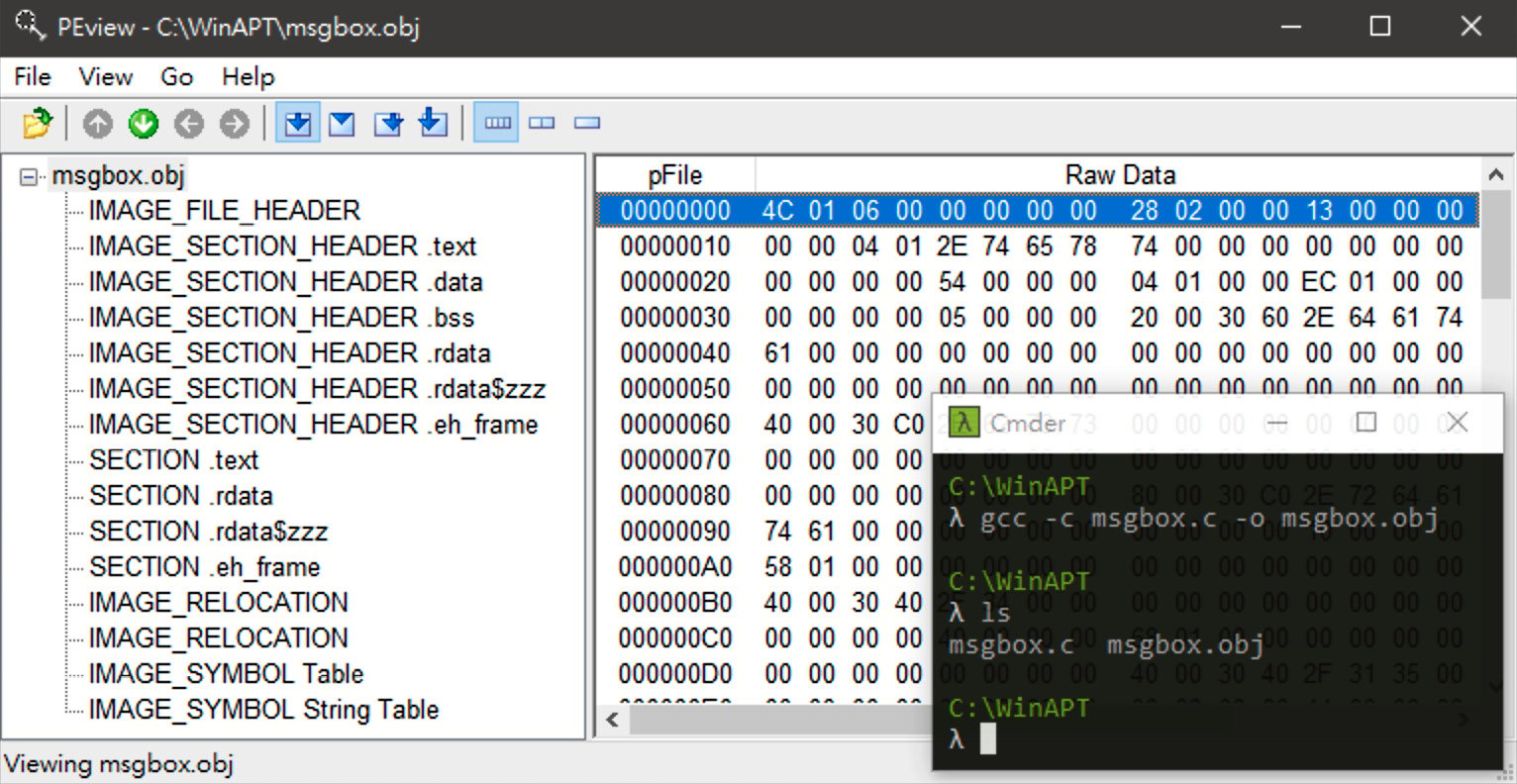
Figure 1.4 – COFF
At the end of this structure is a whole array of IMAGE_SECTION_HEADER to record the current location and size of the content of each section in the file. Closely attached at the end of this array is the substantive content of each section. In practice, the first section will usually be the content of the .text section.
In the next stage, the Linker is responsible for adding an extra piece of the COFF file to the application loader, which will become our common EXE program.
Important note
In the case of x86 chip systems, it is customary to reverse the pointer and digit per bit into the memory when encoding. This practice is called little-endian, as opposed to a string or array that should be arranged from lowest to highest address. The data arrangement of multiple bytes varies according to the chip architecture. Interested readers can refer to the article How to write endian-independent code in C (https://developer.ibm.com/articles/au-endianc/).
In this section, we learned about the COFF, which is used to record the contents in the memory of the various sections recorded by the compiler.


