






















































Introduction
You have just come back from your yearly vacation. Being an avid social media user, you are busy uploading your photographs to your favorite social media app. When the photos get uploaded, you notice that the app automatically identifies your face and tags you in them almost instantly. In fact, it does that even in group photos. Even in some poorly lit photos, you notice that the app has, most of the time, tagged you correctly. How does the app learn how to do that?
To identify a person in a picture, the app requires accurate information on the person's facial structure, bone structure, eye color, and many other details. But when you used that photo app, you didn't have to feed all these details explicitly to the app. All you did was upload your photos, and the app automatically began identifying you in them. How did the app know all these details?
When you uploaded your first photo to the app, the app would have asked you to tag yourself. When you manually tagged yourself, the app automatically "learned" all the information it needed to know about your face. Then, every time you upload a photo, the app uses the information it learned to identify you. It improves when you manually tag yourself in photos in which the app incorrectly tagged you.
This ability of the app to learn new details and improve itself with minimal human intervention is possible due to the power of deep learning (DL). Deep learning is a part of artificial intelligence (AI) that helps a machine learn by recognizing patterns from labeled data. But wait a minute, isn't that what machine learning (ML) does? Then what is the difference between deep learning and machine learning? What is the point of confluence among domains such as AI, machine learning, and deep learning? Let's take a quick look.
AI, Machine Learning, and Deep Learning
Artificial intelligence is the branch of computer science aimed at developing machines that can simulate human intelligence. Human intelligence, in a simplified manner, can be explained as decisions that are taken based on the inputs received from our five senses – sight, hearing, touch, smell, and taste. AI is not a new field and has been in vogue since the 1950s. Since then, there have been multiple waves of ecstasy and agony within this domain. The 21st century has seen a resurgence in AI following the big strides made in computing, the availability of data, and a better understanding of theoretical underpinnings. Machine learning and deep learning are subfields of AI and are increasingly used interchangeably.
The following figure depicts the relationship between AI, ML, and DL:
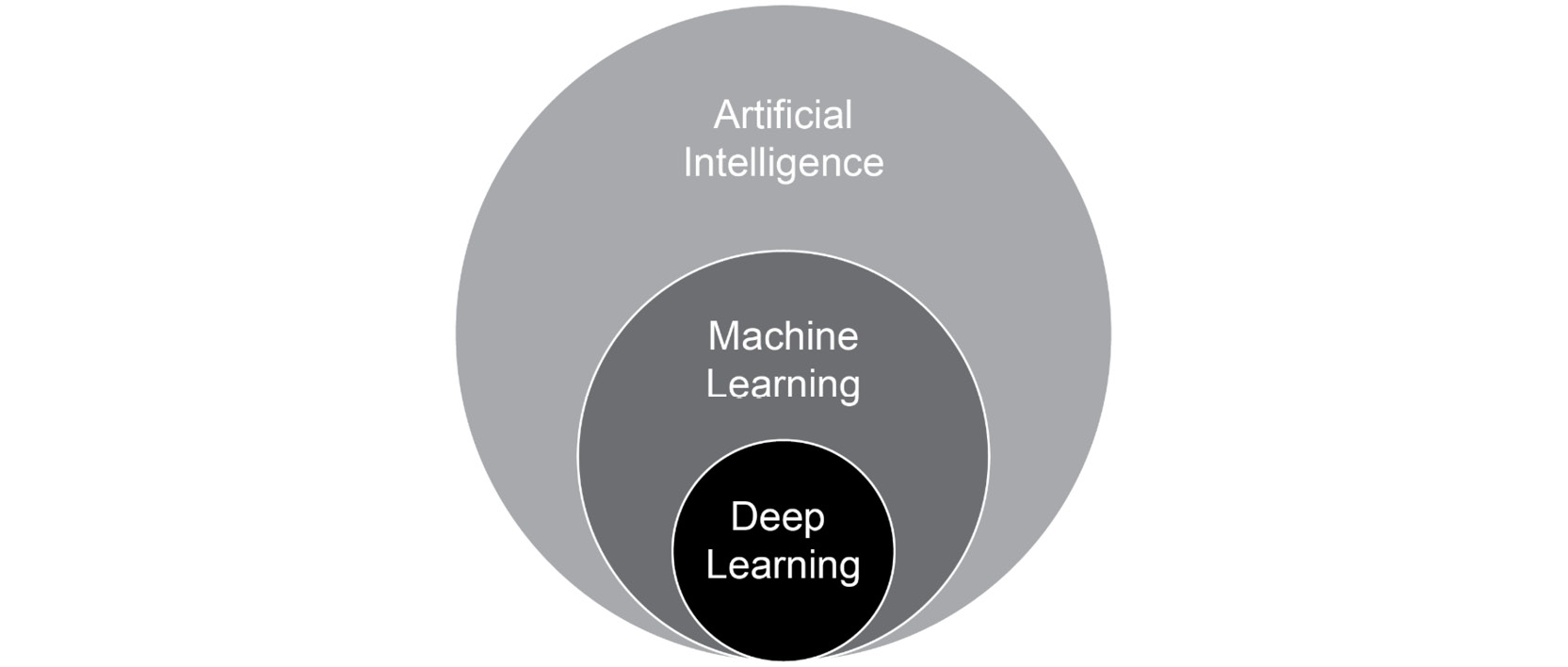
Figure 1.1: Relationship between AI, ML, and DL
Machine Learning
Machine learning is the subset of AI that performs specific tasks by identifying patterns within data and extracting inferences. The inferences that are derived from data are then used to predict outcomes on unseen data. Machine learning differs from traditional computer programming in its approach to solving specific tasks. In traditional computer programming, we write and execute specific business rules and heuristics to get the desired outcomes. However, in machine learning, the rules and heuristics are not explicitly written. These rules and heuristics are learned by providing a dataset. The dataset provided for learning the rules and heuristics is called a training dataset. The whole process of learning and inferring is called training.
Learning rules and heuristics is done using different algorithms that use statistical models for that purpose. These algorithms make use of many representations of data for learning. Each such representation of data is called an example. Each element within an example is called a feature. The following is an example of the famous IRIS dataset (https://archive.ics.uci.edu/ml/datasets/Iris). This dataset is a representation of different species of iris flowers based on different characteristics, such as the length and width of their sepals and petals:
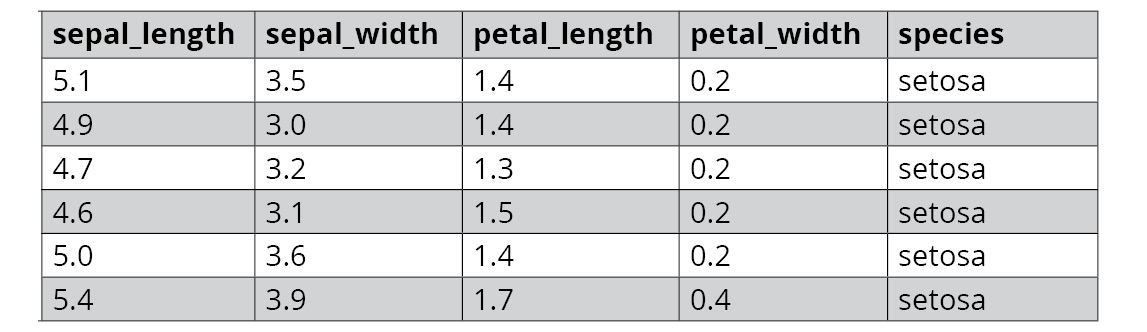
Figure 1.2: Sample data from the IRIS dataset
In the preceding dataset, each row of data represents an example, and each column is a feature. Machine learning algorithms make use of these features to draw inferences from the data. The veracity of the models, and thereby the outcomes that are predicted, depend a lot on the features of the data. If the features provided to the machine learning algorithm are a good representation of the problem statement, the chances of getting a good result are high. Some examples of machine learning algorithms are linear regression, logistic regression, support vector machines, random forest, and XGBoost.
Even though traditional machine learning algorithms are useful for a lot of use cases, they have a lot of dependence on the quality of the features to get superior outcomes. The creation of features is a time-consuming art and requires a lot of domain knowledge. However, even with comprehensive domain knowledge, there are still limitations on transferring that knowledge to derive features, thereby encapsulating the nuances of the data generating processes. Also, with the increasing complexity of the problems that are tackled with machine learning, particularly with the advent of unstructured data (images, voice, text, and so on), it can be almost impossible to create features that represent the complex functions, which, in turn, generate data. As a result, there is often a need to find a different approach to solving complex problems; that is where deep learning comes into play.
Deep Learning
Deep learning is a subset of machine learning and an extension of a certain kind of algorithm called Artificial Neural Networks (ANNs). Neural networks are not a new phenomenon. Neural networks were created in the first half of the 1940s. The development of neural networks was inspired by the knowledge of how the human brain works. Since then, there have been several ups and downs in this field. One defining moment that renewed enthusiasm around neural networks was the introduction of an algorithm called backpropagation by stalwarts in the field such as Geoffrey Hinton. For this reason, Hinton is widely regarded as the 'Godfather of Deep Learning'. We will be discussing neural networks in depth in Chapter 2, Neural Networks.
ANNs with multiple (deep) layers lie at the heart of deep learning. One defining characteristic of deep learning models is their ability to learn features from the input data. Unlike traditional machine learning, where there is the need to create features, deep learning excels in learning different hierarchies of features across multiple layers. Say, for example, we are using a deep learning model to detect faces. The initial layers of the model will learn low-level approximations of a face, such as the edges of the face, as shown in Figure 1.3. Each succeeding layer takes the lower layers' features and puts them together to form more complex features. In the case of face detection, if the initial layer has learned to detect edges, the subsequent layers will put these edges together to form parts of a face such as the nose or eyes. This process continues with each successive layer, with the final layer generating an image of a human face:

Figure 1.3: Deep learning model for detecting faces
Note
The preceding image is sourced from the popular research paper: Lee, Honglak & Grosse, Roger & Ranganath, Rajesh & Ng, Andrew. (2011). Unsupervised Learning of Hierarchical Representations with Convolutional Deep Belief Networks. Commun. ACM. 54. 95-103. 10.1145/2001269.2001295.
Deep learning techniques have made great strides over the past decade. There are different factors that have led to the exponential rise of deep learning techniques. At the top of the list is the availability of large quantities of data. The digital age, with its increasing web of connected devices, has generated lots of data, especially unstructured data. This, in turn, has fueled the large-scale adoption of deep learning techniques as they are well-suited to handle large unstructured data.
Another major factor that has led to the rise in deep learning is the strides that have been made in computing infrastructure. Deep learning models that have large numbers of layers and millions of parameters necessitate great computing power. The advances in computing layers such as Graphical Processing Units (GPUs) and Tensor Processing Units (TPUs) at an affordable cost has led to the large-scale adoption of deep learning.
The pervasiveness of deep learning was also accelerated by open sourcing different frameworks in order to build and implement deep learning models. In 2015, the Google Brain team open sourced the TensorFlow framework and since then TensorFlow has grown to be one of the most popular frameworks for deep learning. The other major frameworks available are PyTorch, MXNet, and Caffe. We will be using the TensorFlow framework in this book.
Before we dive deep into the building blocks of deep learning, let's get our hands dirty with a quick demo that illustrates the power of deep learning models. You don't need to know any of the code that is presented in this demo. Simply follow the instructions and you'll be able to get a quick glimpse of the basic capabilities of deep learning.
Using Deep Learning to Classify an Image
In the exercise that follows, we will classify an image of a pizza and convert the resulting class text into speech. To classify the image, we will be using a pre-trained model. The conversion of text into speech will be done using a freely available API called Google Text-to-Speech (gTTS). Before we get into it, let's understand some of the key building blocks of this demo.
Pre-Trained Models
Training a deep learning model requires a lot of computing infrastructure and time, with big datasets. However, to aid with research and learning, the deep learning community has also made models that have been trained on large datasets available. These pre-trained models can be downloaded and used for predictions or can be used for further training. In this demo, we will be using a pre-trained model called ResNet50. This model is available along with the Keras package. This pre-trained model can predict 1,000 different classes of objects that we encounter in our daily lives, such as birds, animals, automobiles, and more.
The Google Text-to-Speech API
Google has made its Text-to-Speech algorithm available for limited use. We will be using this algorithm to convert the predicted text into speech.
Prerequisite Packages for the Demo
For this demo to work, you will need the following packages installed on your machine:
- TensorFlow 2.0
- Keras
- gTTS
Please refer to the Preface to understand the process of installing the first two packages. Installing gTTS will be shown in the exercise. Let's dig into the demo.
Exercise 1.01: Image and Speech Recognition Demo
In this exercise, we will demonstrate image recognition and speech-to-text conversion using deep learning models. At this point, you will not be able to understand each and every line of the code. This will be explained later. For now, just execute the code and find out how easy it is to build deep learning and AI applications with TensorFlow. Follow these steps to complete this exercise:
- Open a Jupyter Notebook and name it Exercise 1.01. For details on how to start a Jupyter Notebook, please refer to the preface.
- Import all the required libraries:
from tensorflow.keras.preprocessing.image import load_img from tensorflow.keras.preprocessing.image import img_to_array from tensorflow.keras.applications.resnet50 import ResNet50 from tensorflow.keras.preprocessing import image from tensorflow.keras.applications.resnet50 \ import preprocess_input from tensorflow.keras.applications.resnet50 \ import decode_predictions
Note
The code snippet shown here uses a backslash (
\) to split the logic across multiple lines. When the code is executed, Python will ignore the backslash, and treat the code on the next line as a direct continuation of the current line.Here is a brief description of the packages we'll be importing:
load_img: Loads the image into the Jupyter Notebookimg_to_array: Converts the image into a NumPy array, which is the desired format for Keraspreprocess_input: Converts the input into a format that's acceptable for the modeldecode_predictions: Converts the numeric output of the model prediction into text labelsResnet50: This is the pre-trained image classification model - Create an instance of the pre-trained
Resnetmodel:mymodel = ResNet50()
You should get a message similar to the following as it downloads:

Figure 1.4: Loading Resnet50
Resnet50is a pre-trained image classification model. For first-time users, it will take some time to download the model into your environment. - Download an image of a pizza from the internet and store it in the same folder that you are running the Jupyter Notebook in. Name the image
im1.jpg.Note
You can also use the image we are using by downloading it from this link: https://packt.live/2AHTAC9
- Load the image to be classified using the following command:
myimage = load_img('im1.jpg', target_size=(224, 224))If you are storing the image in another folder, the complete path of the location where the image is located has to be given in place of the
im1.jpgcommand. For example, if the image is stored inD:/projects/demo, the code should be as follows:myimage = load_img('D:/projects/demo/im1.jpg', \ target_size=(224, 224)) - Let's display the image using the following command:
myimage
The output of the preceding command will be as follows:

Figure 1.5: Output displayed after loading the image
- Convert the image into a
numpyarray as the model expects it in this format:myimage = img_to_array(myimage)
- Reshape the image into a four-dimensional format since that's what is expected by the model:
myimage = myimage.reshape((1, 224, 224, 3))
- Prepare the image for submission by running the
preprocess_input()function:myimage = preprocess_input(myimage)
- Run the prediction:
myresult = mymodel.predict(myimage)
- The prediction results in a number that needs to be converted into the corresponding label in text format:
mylabel = decode_predictions(myresult)
- Next, type in the following code to display the label:
mylabel = mylabel[0][0]
- Print the label using the following code:
print("This is a : " + mylabel[1])If you have followed the steps correctly so far, the output will be as follows:
This is a : pizza
The model has successfully identified our image. Interesting, isn't it? In the next few steps, we'll take this a step further and convert this result into speech.
Tip
While we have used an image of a pizza here, you can use just about any image with this model. We urge you to try out this exercise multiple times with different images.
- Prepare the text to be converted into speech:
sayit="This is a "+mylabel[1]
- Install the
gttspackage, which is required for converting text into speech. This can be implemented in the Jupyter Notebook, as follows:!pip install gtts
- Import the required libraries:
from gtts import gTTS import os
The preceding code will import two libraries. One is
gTTS, that is, Google Text-to-Speech, which is a cloud-based open source API for converting text into speech. Another is theoslibrary that is used to play the resulting audio file. - Call the
gTTSAPI and pass the text as a parameter:myobj = gTTS(text=sayit)
Note
You need to be online while running the preceding step.
- Save the resulting audio file. This file will be saved in the home directory where the Jupyter Notebook is being run.
myobj.save("prediction.mp3")Note
You can also specify the path where you want it to be saved by including the absolute path in front of the name; for example,
(myobj.save('D:/projects/prediction.mp3'). - Play the audio file:
os.system("prediction.mp3")If you have correctly followed the preceding steps, you will hear the words
This is a pizzabeing spoken.Note
To access the source code for this specific section, please refer to https://packt.live/2ZPZx8B.
You can also run this example online at https://packt.live/326cRIu. You must execute the entire Notebook in order to get the desired result.
In this exercise, we learned how to build a deep learning model by making use of publicly available models using a few lines of code in TensorFlow. Now that you have got a taste of deep learning, let's move forward and learn about the different building blocks of deep learning.
Deep Learning Models
At the heart of most of the popular deep learning models are ANNs, which are inspired by our knowledge of how the brain works. Even though no single model can be called perfect, different models perform better in different scenarios. In the sections that follow, we will learn about some of the most prominent models.
The Multi-Layer Perceptron
The multi-layer perceptron (MLP) is a basic type of neural network. An MLP is also known as a feed-forward network. A representation of an MLP can be seen in the following figure:
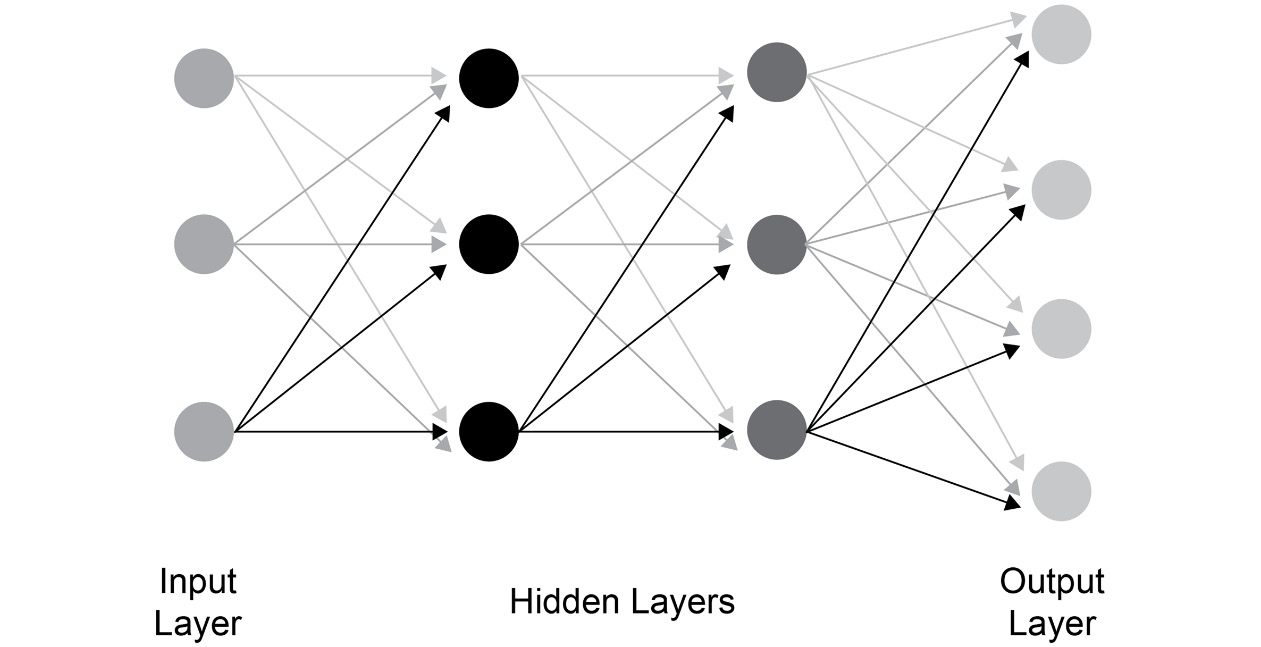
Figure 1.6: MLP representation
One of the basic building blocks of an MLP (or any neural network) is a neuron. A network consists of multiple neurons connected to successive layers. At a very basic level, an MLP will consist of an input layer, a hidden layer, and an output layer. The input layer will have neurons equal to the input data. Each input neuron will have a connection to all the neurons of the hidden layer. The final hidden layer will be connected to the output layer. The MLP is a very useful model and can be tried out on various classification and regression problems. The concept of an MLP will be covered in detail in Chapter 2, Neural Networks.
Convolutional Neural Networks
A convolutional neural network (CNN) is a class of deep learning model that is predominantly used for image recognition. When we discussed the MLP, we saw that each neuron in a layer is connected to every other neuron in the subsequent layer. However, CNNs adopt a different approach and do not resort to such a fully connected architecture. Instead, CNNs extract local features from images, which are then fed to the subsequent layers.
CNNs rose to prominence in 2012 when an architecture called AlexNet won a premier competition called the ImageNet Large-Scale Visual Recognition Challenge (ILSVRC). ILSVRC is a large-scale computer vision competition where teams from around the globe compete for the prize of the best computer vision model. Through the 2012 research paper titled ImageNet Classification with Deep Convolutional Neural Networks (https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks), Alex Krizhevsky, et al. (University of Toronto) showcased the true power of CNN architectures, which eventually won them the 2012 ILSVRC challenge. The following figure depicts the structure of the AlexNet model, a CNN model whose high performance catapulted CNNs to prominence in the deep learning domain. While the structure of this model may look complicated to you, in Chapter 3, Image Classification with Convolutional Neural Networks, the working of such CNN networks will be explained to you in detail:
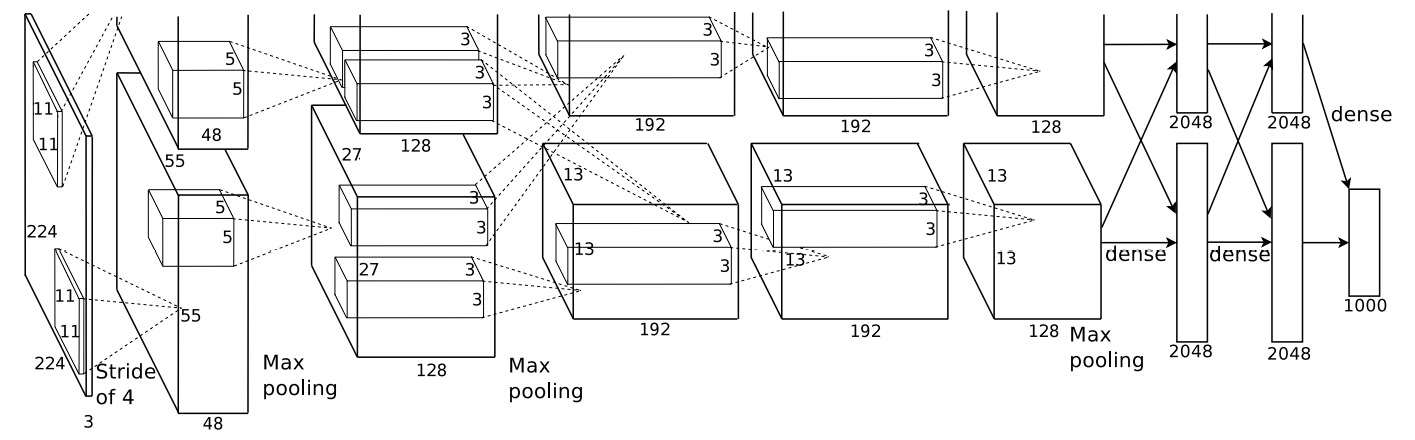
Figure 1.7: CNN architecture of the AlexNet model
Note
The aforementioned diagram is sourced from the popular research paper: Krizhevsky, Alex & Sutskever, Ilya & Hinton, Geoffrey. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Neural Information Processing Systems. 25. 10.1145/3065386.
Since 2012, there have been many breakthrough CNN architectures expanding the possibilities for computer vision. Some of the prominent architectures are ZFNet, Inception (GoogLeNet), VGG, and ResNet.
Some of the most prominent use cases where CNNs are put to use are as follows:
- Image recognition and optical character recognition (OCR)
- Face recognition on social media
- Text classification
- Object detection for self-driving cars
- Image analysis for health care
Another great benefit of working with deep learning is that you needn't always build your models from scratch – you could use models built by others and use them for your own applications. This is known as "transfer learning", and it allows you to benefit from the active deep learning community.
We will apply transfer learning to image processing and learn about CNNs and their dynamics in detail in Chapter 3, Image Classification with Convolutional Neural Networks.
Recurrent Neural Networks
In traditional neural networks, the inputs are independent of the outputs. However, in cases such as language translation, where there is dependence on the words preceding and succeeding a word, there is a need to understand the dynamics of the sequences in which words appear. This problem was solved by a class of networks called recurrent neural networks (RNNs). RNNs are a class of deep learning networks where the output from the previous step is sent as input to the current step. A distinct characteristic of an RNN is a hidden layer, which remembers the information of other inputs in a sequence. A high-level representation of an RNN can be seen in the following figure. You'll learn more about the inner workings of these networks in Chapter 5, Deep Learning for Sequences:
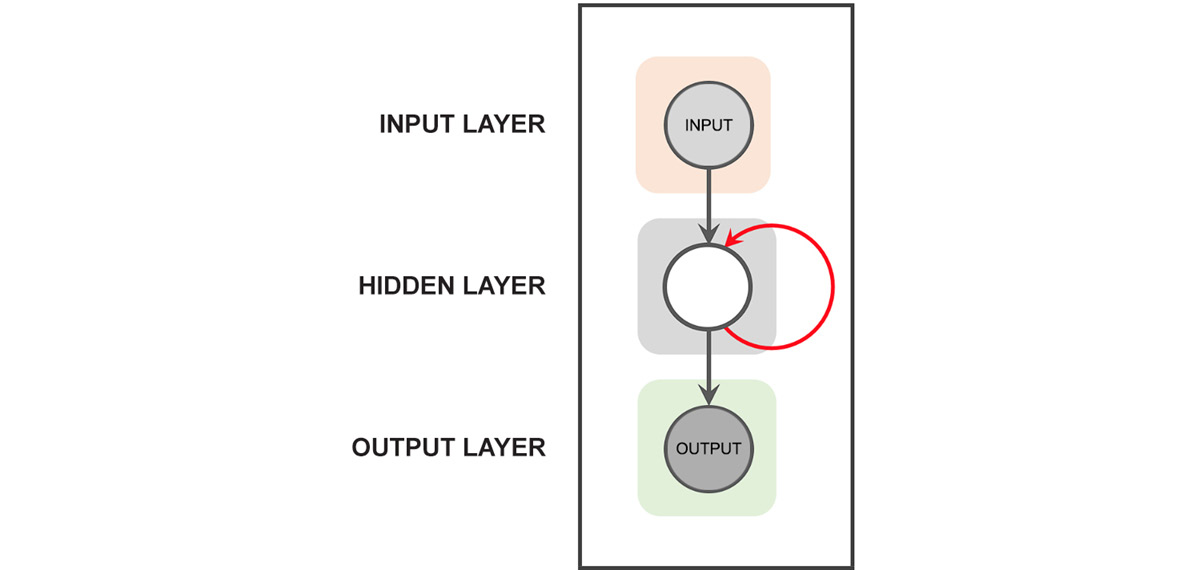
Figure 1.8: Structure of RNNs
There are different types of RNN architecture. Some of the most prominent ones are long short-term memory (LSTM) and gated recurrent units (GRU).
Some of the important use cases for RNNs are as follows:
- Language modeling and text generation
- Machine translation
- Speech recognition
- Generating image descriptions
RNNs will be covered in detail in Chapter 5, Deep Learning for Sequences, and Chapter 6, LSTMs, GRUs, and Advanced RNNs.
Generative Adversarial Networks
Generative adversarial networks (GANs) are networks that are capable of generating data distributions similar to any real data distributions. One of the pioneers of deep learning, Yann LeCun, described GANs as one of the most promising ideas in deep learning in the last decade.
To give you an example, suppose we want to generate images of dogs from random noise data. For this, we train a GAN network with real images of dogs and the noise data until we generate data that looks like the real images of dogs. The following diagram explains the concept behind GANs. At this stage, you might not fully understand this concept. It will be explained in detail in Chapter 7, Generative Adversarial Networks.
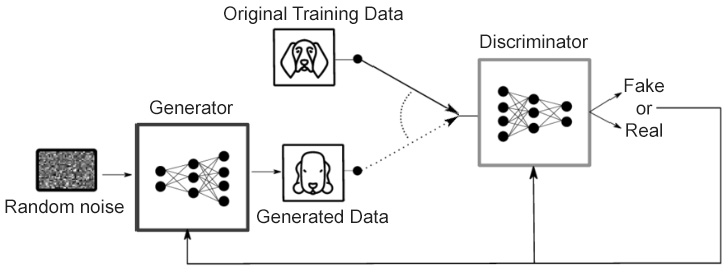
Figure 1.9: Structure of GANs
Note
The aforementioned diagram is sourced from the popular research paper: Barrios, Buldain, Comech, Gilbert & Orue (2019). Partial Discharge Classification Using Deep Learning Methods—Survey of Recent Progress (https://doi.org/10.3390/en12132485).
GANs are a big area of research, and there are many use cases for them. Some of the useful applications of GANs are as follows:
- Image translation
- Text to image synthesis
- Generating videos
- The restoration of art
GANs will be covered in detail in Chapter 7, Generative Adversarial Networks.
The possibilities and promises of deep learning are huge. Deep learning applications have become ubiquitous in our daily lives. Some notable examples are as follows:
- Chatbots
- Robots
- Smart speakers (such as Alexa)
- Virtual assistants
- Recommendation engines
- Drones
- Self-driving cars or autonomous vehicles
This ever-expanding canvas of possibilities makes it a great toolset in the arsenal of a data scientist. This book will progressively introduce you to the amazing world of deep learning and make you adept at applying it to real-world scenarios.






















