






















































Dynamic Programming (DP) is a base for many RL algorithms. The main paradigm of DP algorithms is to use the state- and action-value functions as tools to find the optimal policy, given a fully-known model of the environment. In this section, we'll see how to do that.
Finding optimal policies with Dynamic Programming
Policy evaluation
We'll start with policy evaluation, or how to compute the state-value function, 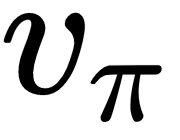 , given a specific policy, π. This task is also known as prediction. As a reminder, we'll assume that the state-value function is a table. We'll implement policy evaluation using the state-value Bellman equation we defined in the Bellman equations section. Let's start:
, given a specific policy, π. This task is also known as prediction. As a reminder, we'll assume that the state-value function is a table. We'll implement policy evaluation using the state-value Bellman equation we defined in the Bellman equations section. Let's start:
- Input the following...



