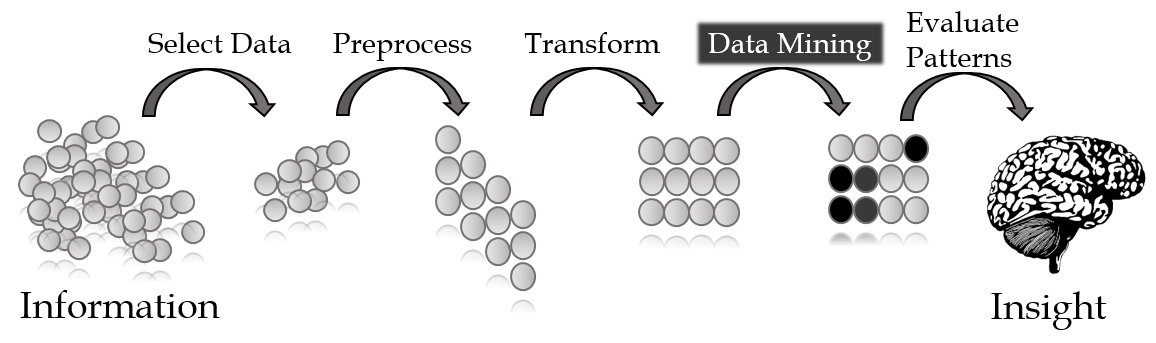
In a sense, data mining is a necessary and predictable response to the dawn of the information age. Indeed, every piece of the modern global economy relies more each year on information and an immense in-stream of data. The path from information pool to actionable insights has many steps. Data mining is typically defined as the pattern and/or trend discovery phase in the pipeline.
This book is a quick-start guide for data mining and will include utilitarian descriptions of the most important and widely used methods, including the mainstays among data professionals such as k-means clustering, random forest prediction, and principal component dimensionality reduction. Along the way, I will give you tips I've learned and introduce helpful scripting tools to make your life easier. Not only will I introduce the tools, but I will clearly describe what makes them so helpful and why you should take the time to learn them.
The first half of the book will cover the nuts and bolts of data collection and preparation. The second half will be more conceptual and will introduce the topics of transformation, clustering, and prediction. The conceptual discussions start in the middle of Chapter 4, Cleaning and Readying Data for Analysis, and are written solely as a conversation between myself and the reader. These conversations are ported mostly from the many adhoc training sessions I've done over the years on Intel office marker boards. The last chapter of the book will be on the deployment of these models. This topic is the natural next step for new practitioners and I will provide an introduction and references for when you think you are ready to take the next steps.
The following topics will be covered in this chapter:
- Descriptive, predictive, and prescriptive analytics
- What will and will not be covered in this book
- Setting up Python environments for data mining
- Installing the Anaconda distribution and Conda package manager
- Launching the Spyder IDE
- Launching a Jupyter Notebook
- Installing a high performance Python distribution
- Recommended libraries and how to install