






















































Creating our own instruction dataset
In this section, we will create our own instruction dataset based on the crawled data from Chapter 3. To create a high-quality instruction dataset, we need to address two main issues: the unstructured nature of our data and the limited number of articles we can crawl.
This unstructured nature comes from the fact that we are dealing with raw text (articles), instead of pairs of instructions and answers. To address this issue, we will use an LLM to perform this transformation. Specifically, we will employ a combination of backtranslation and rephrasing. Backtranslation refers to the process of providing the expected answer as output and generating its corresponding instruction. However, using a chunk of text like a paragraph as an answer might not always be appropriate. This is why we want to rephrase the raw text to ensure we’re outputting properly formatted, high-quality answers. Additionally, we can ask the model to follow the author’s writing style to stay close to the original paragraph. While this process involves extensive prompt engineering, it can be automated and used at scale, as we will see in the following implementation.
Our second issue regarding the limited number of samples is quite common in real-world use cases. The number of articles we can retrieve is limited, which constrains the size of the instruction dataset we are able to create. In this example, the more samples we have, the better the model becomes at imitating the original authors. To address this problem, we will divide our articles into chunks and generate three instruction-answer pairs for each chunk. This will multiply the number of samples we create while maintaining diversity in the final dataset. For simplicity, we will do it using OpenAI’s GPT-4o-mini model, but you can also use open-source models.
However, LLMs are not reliable when it comes to producing structured output. Even when given specific templates or instructions, there’s no guarantee that the model will consistently adhere to them. This inconsistency often necessitates additional string parsing to ensure the output meets the desired format.
To simplify this process and ensure properly structured results, we can employ structured generation techniques. Structured generation is an effective method to force an LLM to follow a predefined template, such as JSON, pydantic classes, or regular expressions. In the following, we will use OpenAI’s JSON mode feature, which provides a more robust way to return valid JSON objects and reduce the need for extensive post-processing.
Based on this description, the following figure summarizes every step of the synthetic data pipeline we want to build.
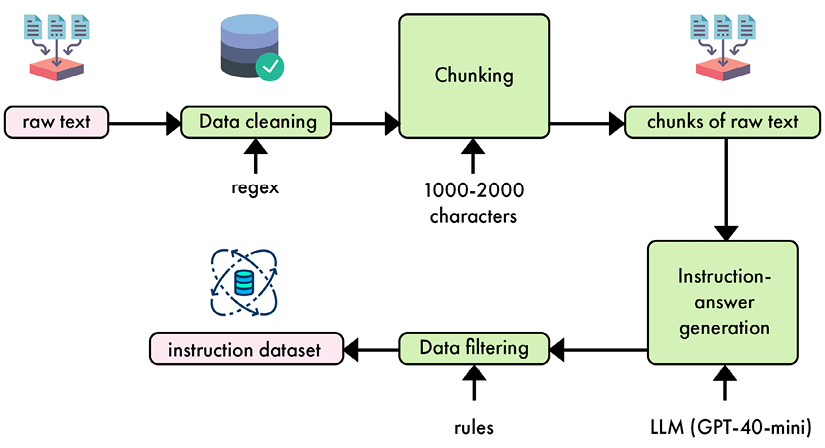
Figure 5.6 – Synthetic data generation pipeline from raw text to instruction dataset
Let’s now implement it in Python. You can implement it as part of the LLMOps pipeline, or as a standalone script:
- We want to make sure that the following libraries are installed. The OpenAI library will allow us to interact with a model to generate the instruction data, and datasets will format it into a Hugging Face-compatible format. The tqdm library is installed to visualize the progress during the data generation process.
openai==1.37.1 datasets==2.20.0 tqdm==4.66.4 - We import all the required libraries as follows.
import concurrent.futures import json import random import re from concurrent.futures import ThreadPoolExecutor from typing import List, Tuple from datasets import Dataset from openai import OpenAI from pydantic import BaseModel, Field from tqdm.auto import tqdm - The raw data we have is a JSON file. We create a Hugging Face dataset from this JSON file by extracting specific fields from each article:
id,content,platform,author_id,author name, andlink.def load_articles_from_json(file_path: str) -> Dataset: with open(file_path, "r") as file: data = json.load(file) return Dataset.from_dict( { "id": [item["id"] for item in data["artifact_data"]], "content": [item["content"] for item in data["artifact_data"]], "platform": [item["platform"] for item in data["artifact_data"]], "author_id": [item["author_id"] for item in data["artifact_data"]], "author_full_name": [item["author_full_name"] for item in data["artifact_data"]], "link": [item["link"] for item in data["artifact_data"]], } )
If we simply load our dataset as a pandas dataframe, it returns the following table.
|
id |
content |
platform |
author_id |
author_full_name |
link |
|
|
0 |
ab2f9e2e-5459-4dd6-97d6-c291de4a7093 |
The Importance of Data Pipelines in the Era of... |
medium |
e6b945ba-6a9a-4cde-b2bf-0890af79732b |
Alex Vesa |
|
|
1 |
ccfe70f3-d324-40b6-ba38-86e72786dcf4 |
Change Data Capture: Enabling Event-Driven Arc... |
medium |
e6b945ba-6a9a-4cde-b2bf-0890af79732b |
Alex Vesa |
|
|
2 |
4c9f68ae-ec8b-4534-8ad5-92372bf8bb37 |
The Role of Feature Stores in Fine-Tuning LLMs... |
medium |
e6b945ba-6a9a-4cde-b2bf-0890af79732b |
Alex Vesa |
|
|
... |
... |
... |
... |
... |
... |
... |
|
73 |
68795a4d-26c2-43b7-9900-739a80b9b7dc |
DML: 4 key ideas you must know to train an LLM... |
decodingml.substack.com |
1519b1d1-1a5d-444c-a880-926c9eb6539e |
Paul Iusztin |
|
|
74 |
d91b17c0-05d8-4838-bf61-e2abc1573622 |
DML: How to add real-time monitoring & metrics... |
decodingml.substack.com |
1519b1d1-1a5d-444c-a880-926c9eb6539e |
Paul Iusztin |
https://decodingml.substack.com/p/dml-how-to-a... |
|
75 |
dcf55b28-2814-4480-a18b-a77d01d44f5f |
DML: Top 6 ML Platform Features You Must Know ... |
decodingml.substack.com |
1519b1d1-1a5d-444c-a880-926c9eb6539e |
Paul Iusztin |
- If we inspect the content of some articles a little further, we realize that some of them have special characters and redundant whitespaces. We can clean this with a simple regex.
First, we use [^\w\s.,!?'] to remove non-alphanumeric characters except for apostrophes, periods, commas, exclamation marks, and question marks. Then, we use \s+ to replace multiple consecutive whitespace characters with a single space.
Finally, we implement strip() to remove any leading or trailing whitespace.
def clean_text(text):
text = re.sub(r"[^\w\s.,!?']", " ", text)
text = re.sub(r"\s+", " ", text)
return text.strip()
- Now that we can load our articles, we need to chunk them before turning them into pairs of instructions and answers. Ideally, you would want to use headlines or paragraphs to produce semantically meaningful chunking.
However, in our example, like in the real world, raw data tends to be messy. Due to improper formatting, we cannot extract paragraphs or headlines for every article in our raw dataset. Instead, we will extract sentences using a regex to get chunks between 1,000 and 2,000 characters. This number can be optimized depending on the density of the information contained in the text.
The extract_substrings function processes each article in the dataset by first cleaning the text and then using a regex to split it into sentences. It then builds chunks of text by concatenating these sentences until each chunk is between 1,000 and 2,000 characters long.
def extract_substrings(dataset: Dataset, min_length: int = 1000, max_length: int = 2000) -> List[str]:
extracts = []
sentence_pattern = r"(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?|\!)\s"
for article in dataset["content"]:
cleaned_article = clean_text(article)
sentences = re.split(sentence_pattern, cleaned_article)
current_chunk = ""
for sentence in sentences:
sentence = sentence.strip()
if not sentence:
continue
if len(current_chunk) + len(sentence) <= max_length:
current_chunk += sentence + " "
else:
if len(current_chunk) >= min_length:
extracts.append(current_chunk.strip())
current_chunk = sentence + " "
if len(current_chunk) >= min_length:
extracts.append(current_chunk.strip())
return extracts
- Next, we want to create instruction-answer pairs from the extracted chunks of text. To manage these pairs effectively, we introduce the
InstructionAnswerSetclass. This class allows us to create instances directly from JSON strings, which is useful when parsing the output from the OpenAI API.class InstructionAnswerSet: def __init__(self, pairs: List[Tuple[str, str]]): self.pairs = pairs @classmethod def from_json(cls, json_str: str) -> 'InstructionAnswerSet': data = json.loads(json_str) pairs = [(pair['instruction'], pair['answer']) for pair in data['instruction_answer_pairs']] return cls(pairs) def __iter__(self): return iter(self.pairs) - Now that we have a set of extracts from the articles with a reasonable length, we can use an LLM to transform them into pairs of instructions and answers. Note that this step is model-agnostic and can be implemented with any open-source or closed-source model. Because this output is grounded in the context we provide, it doesn’t require complex reasoning or high-performing models.
For convenience, we will use GPT-4o mini in this example. This choice is motivated by the low cost and good performance of this model. Prompt engineering is the most important aspect of this data transformation stage and requires several iterations to produce the expected outputs. We recommend starting with simple prompts and adding complexity when required to be more accurate, modify the style, or output multiple responses.
In our example, we want to create instructions like “Write a paragraph about X topic” and corresponding answers that are factual and imitate the writer’s style. To implement this, we need to provide an extract that will ground the model’s responses. For efficiency, we also choose to generate five instruction-answer pairs for each extract. Here’s the beginning of our function for instruction generation, including our prompt.
def generate_instruction_answer_pairs(
extract: str, client: OpenAI
) -> List[Tuple[str, str]]:
prompt = f"""Based on the following extract, generate five instruction-answer pairs. Each instruction \
must ask to write about a specific topic contained in the context. each answer \
must provide a relevant paragraph based on the information found in the \
context. Only use concepts from the context to generate the instructions. \
Instructions must never explicitly mention a context, a system, a course, or an extract. \
Instructions must be self-contained and general. \
Answers must imitate the writing style of the context. \
Example instruction: Explain the concept of an LLM Twin. \
Example answer: An LLM Twin is essentially an AI character that mimics your writing style, personality, and voice. \
It's designed to write just like you by incorporating these elements into a language model. \
The idea is to create a digital replica of your writing habits using advanced AI techniques. \
Provide your response in JSON format with the following structure:
{{
"instruction_answer_pairs": [
{{"instruction": "...", "answer": "..."}},
...
]
}}
Extract:
{extract}
"""
- In addition to the user prompt, we can also specify a system prompt to guide the model into generating the expected instructions. Here, we repeat our high-level task in the system prompt.
The concatenation of the system and user prompts is fed to the OpenAI API, using the GPT-4o mini model in JSON mode and a maximum of 1,200 tokens in the answer. We also use a standard temperature of 0.7 to encourage diverse responses. The generated text is directly parsed using the InstructionAnswerSet class to return pairs of instructions and answers.
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system", "content": "You are a helpful assistant who \
generates instruction-answer pairs based on the given context. \
Provide your response in JSON format.",
},
{"role": "user", "content": prompt},
],
response_format={"type": "json_object"},
max_tokens=1200,
temperature=0.7,
)
# Parse the structured output
result = InstructionAnswerSet.from_json(completion.choices[0].message.content)
# Convert to list of tuples
return result.pairs
- Let’s create a main function to automate the process. It extracts substrings from the input dataset, then uses concurrent processing via Python’s
ThreadPoolExecutorto efficiently generate instruction-answer pairs for each extract.
We use a default max_workers value of 4 because higher values tend to exceed OpenAI’s rate limits, potentially causing API request failures or throttling.
def create_instruction_dataset(
dataset: Dataset, client: OpenAI, num_workers: int = 4
) -> Dataset:
extracts = extract_substrings(dataset)
instruction_answer_pairs = []
with concurrent.futures.ThreadPoolExecutor(max_workers=num_workers) as executor:
futures = [executor.submit(generate_instruction_answer_pairs, extract, client)
for extract in extracts
]
for future in tqdm(concurrent.futures.as_completed(futures), total=len(futures)
):
instruction_answer_pairs.extend(future.result())
instructions, answers = zip(*instruction_answer_pairs)
return Dataset.from_dict(
{"instruction": list(instructions), "output": list(answers)}
)
- We can create our instruction dataset by calling this function. Running it over the raw data with GPT-4o mini costs less than 0.5$.
- We can now create a main function to orchestrate the entire pipeline. It loads the raw data, creates the instruction dataset, splits it into training and testing sets, and pushes the result to the Hugging Face Hub.
def main(dataset_id: str) -> Dataset: client = OpenAI() # 1. Load the raw data raw_dataset = load_articles_from_json("cleaned_documents.json") print("Raw dataset:") print(raw_dataset.to_pandas()) # 2. Create instructiondataset instruction_dataset = create_instruction_dataset(raw_dataset, client) print("Instruction dataset:") print(instruction_dataset.to_pandas()) # 3. Train/test split and export filtered_dataset = instruction_dataset.train_test_split(test_size=0.1) filtered_dataset.push_to_hub("mlabonne/llmtwin") return filtered_dataset Dataset({ features: ['instruction', 'output'], num_rows: 3335 })
We obtained 3,335 pairs with this process. You can find our version of the dataset at https://huggingface.co/datasets/mlabonne/llmtwin. The Hugging Face Hub provides a convenient dataset viewer (see Figure 5.7) to explore instructions and answers and make sure that there are no obvious mistakes in these samples. Due to the small size of the dataset, there is no need for comprehensive exploration and topic clustering.
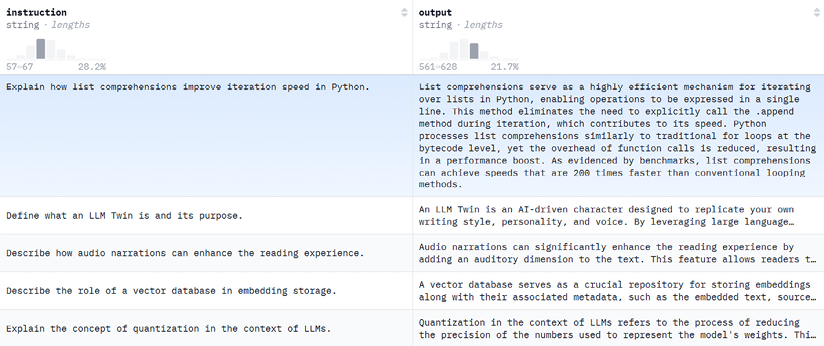
Figure 5.7 – The mlabonne/llmtwin instruction dataset on the Hugging Face Hub
As seen in the previous section, we could refine this instruction dataset by increasing the diversity and complexity of our samples. More advanced prompt engineering could also increase the quality of the generated data by providing examples of the expected results, for instance. Finally, quality evaluation could help filter out low-quality samples by reviewing them individually. For conciseness and simplicity, we will keep a straightforward approach for this instruction dataset and explore more advanced methods in Chapter 6 when we create a preference dataset.
In the next section, we will introduce SFT techniques, as well as related concepts.


