






















































PG methods suffer from several technical issues, some of which you may have already noticed. These issues manifest themselves in training and you may have already observed this in lack of training convergence or wobble. This is caused by several factors we can summarize here:
- Gradient ascent versus gradient descent: In PG, we use gradient ascent to assume the maximum action value is at the top of a hill. However, our chosen optimization methods (SGD or ADAM) are tuned for gradient descent or looking for values at the bottom of hills or flat areas, meaning they work well finding the bottom of a trough but do poorly finding the top of a ridge, especially if the ridge or hill is steep. A comparison of this is shown here:
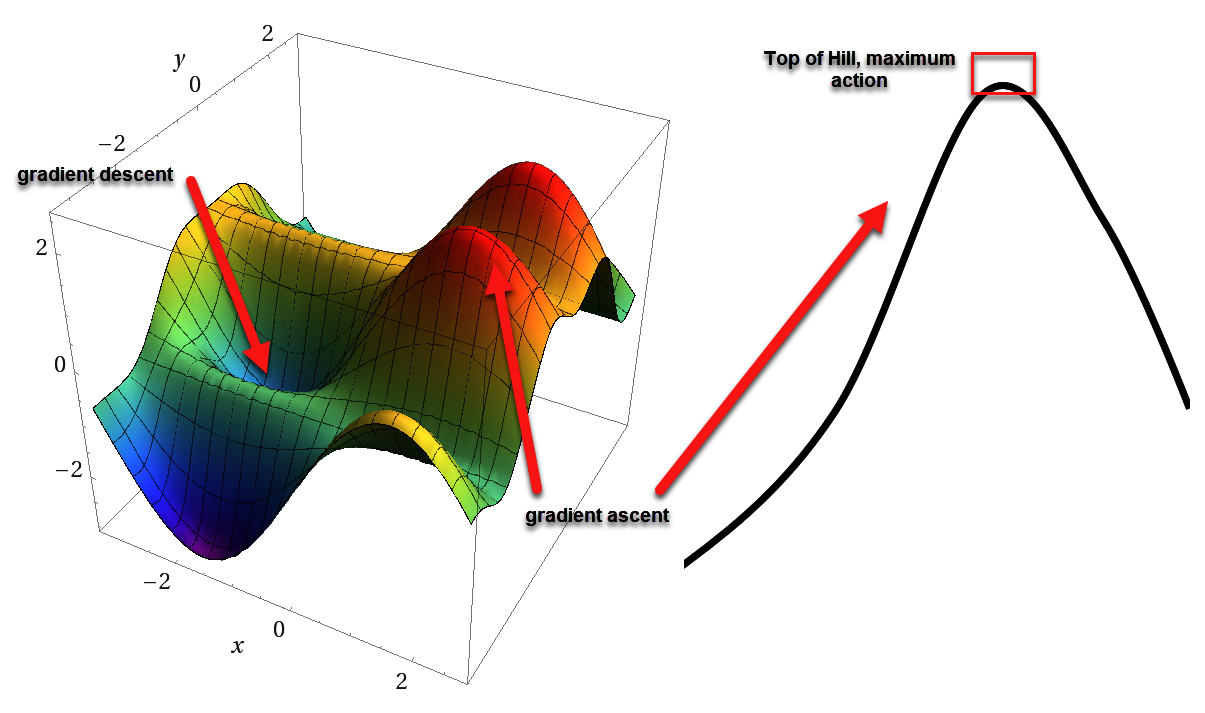
A comparison of gradient descent and ascent
Finding the peak, therefore, becomes the problem, especially in environments...

















