






















































Segmenting data concepts
Before explaining data segments, we have to review basic statistical concepts such as mean and standard deviation. The reason is that each segment has a mean, or central, value, and each point is separated from the central point. The best case is that this separation of points from the mean point is as small as possible for each segment of data.
For the group of data in Figure 1.1, we will explain the mean and the separation of each point from the center measured by the standard deviation:
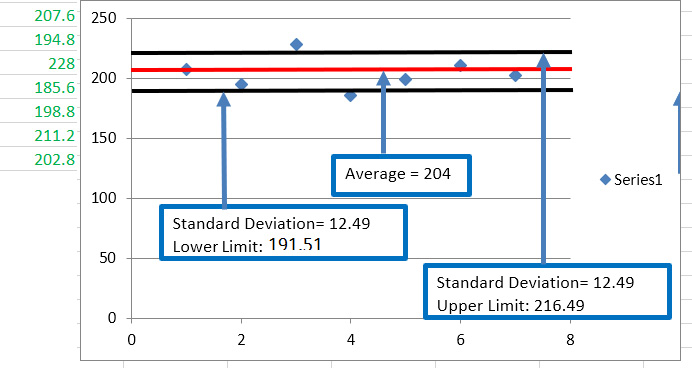
Figure 1.1 – Average, standard deviation, and limits. The data on the left is represented in the chart
The mean of the data on the left of the chart is 204. The group's centroid is represented by the middle line in Figure 1.1.
The standard deviation for this data is 12.49. So, the data upper limit is 216.49 and the lower limit is 191.51.
The standard deviation is the average separation of all the points from the centroid of the segment. It affects the grouping segments, as we want compact groups with a small separation between the group's data points. A small standard deviation means a smaller distance from the group's points to the centroid. The best case for the data segments is that these data points are as close as possible to the centroid. So, the standard deviation of the segment must be a small value.
Now, we will explore four segments of a group of data. We will find out whether all the segments are optimal, and whether the points are close to their respective centroids.
In Figure 1.2, the left column is sales revenue data. The right column is the data segments:
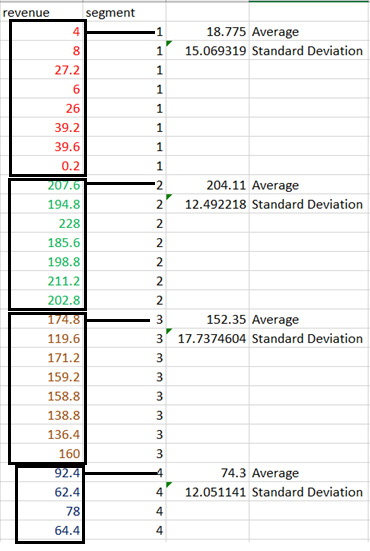
Figure 1.2 – Segments, mean, and standard deviation
We have four segments, and we will analyze the mean and the standard deviation to see whether the points have an optimal separation from the centroid. The separation is given by the standard deviation.
Figure 1.3 is the chart for all the data points in Figure 1.2. We can identify four possible segments by simple visual analysis:
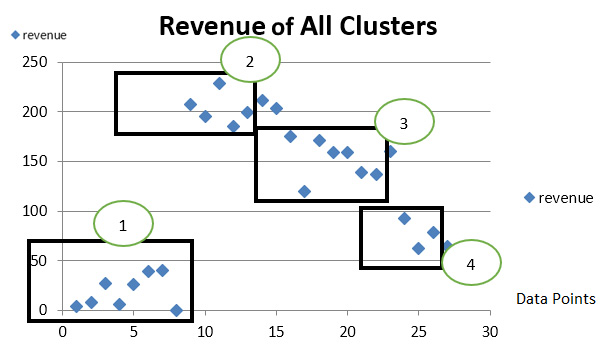
Figure 1.3 – Data segments
We will analyze the centroid and the separation of the points for each segment in Figure 1.3. We can see that the group between 0 and 60 on the y axis is probably an outlier because the revenue is very low compared with the rest of the segments. The other groups appear to be compact around their respective centroid. We will confirm this in the charts of each segment.
The mean for the first segment is 18.775. The standard deviation is 15.09. That means there is a lot of variation around the centroid. This segment is not very compact, as we can see in Figure 1.4. The data is scattered and not close to the centroid value of 18.775:
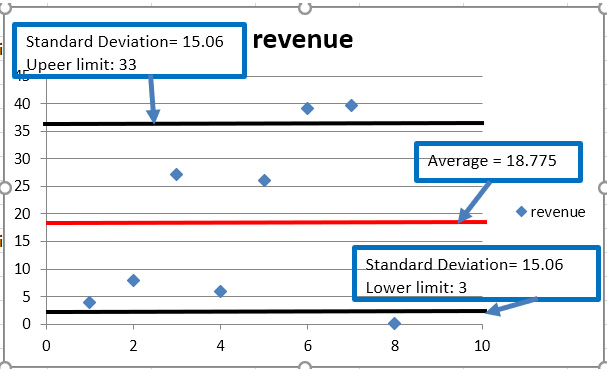
Figure 1.4 – Segment 1, mean and standard deviation
The centroid of this segment is 18.775. The separation of the points measured by the standard deviation is 15.06. The points fall in the range of 3 to 33. That means the separation is wide and the segment is not compact. An explanation for this type of segment is that the points are outliers. They are points that do not have normal behavior and deserve special analysis to research. When we have points that are outside the normal operation values, for example, transactions with smaller amounts than normal at places and times that do not correspond to the rest of the data, we have to do deeper research because they could be indicators of fraud. Or, maybe they are sales that occur only at specific times of the month or year.
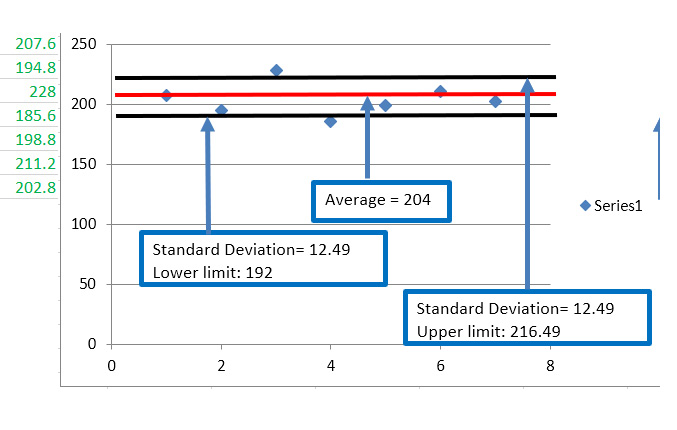
Figure 1.5 – Segment 2, mean and standard deviation
The second segment is more compact than the first one. The mean is 204 and there's a small standard deviation of 12.49. The upper limit is 216 and the lower limit is 192. This is an example of a good segmentation group. The distance from the data points to the centroid is small.
Next is segment number three:
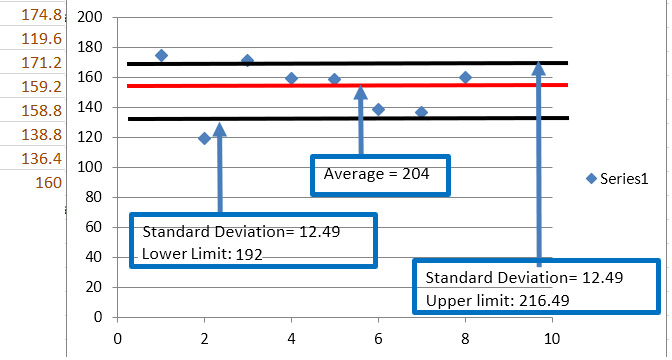
Figure 1.6 – Segment 3, mean and standard deviation
The mean is 204, the upper limit is 216, and the lower limit is 192. By the standard deviation of the points, we also conclude that the segment is compact enough to give reliable information.
The points are close to the centroid, so the behavior of the members of the group or segment is very similar.
Segment number four is the smallest of all. It is shown in Figure 1.7:
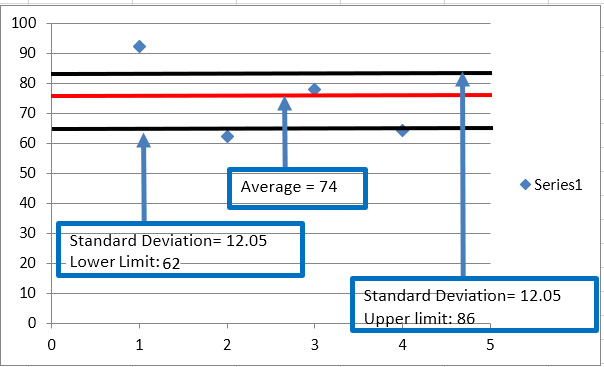
Figure 1.7 – Segment 3, mean and standard deviation
The limits are 62 and 86 and the mean is 74. Figure 1.3 shows that segment four is the group with the second-lowest revenue after segment one. But segment one is scattered with a large standard deviation, so it is a not compact group, and the information is not reliable.
After reviewing the four segments, we conclude that segment number one is the lowest revenue group. It also has the highest separation of points from its centroid. It is probably an outlier and represents the non-regular behavior of sales.
In this section, we reviewed the basic statistical concepts and how they relate to segmentation. We learned that the best-case scenario is to have compact groups with a small standard deviation from the group's mean. It is important to follow up on the points that are outside the groups. These outliers (with very different behavior compared with the rest of the values) could be indicators of fraud. In the next section, we will apply these concepts to multi-variable analysis. We will have groups with two or more variables.


