























































Before you begin your deep learning journey, the first step is to install R, which is available at https://cran.r-project.org/. When you download R and use it, only a few core packages are installed by default, but new packages can be added by selecting from a menu option or by a single line of code. We will not go into detail on how to install R or how to add packages, we assume that most readers are proficient in these skills. A good integrated development environment (IDE) for working with R is essential. By far the most popular IDE, and my recommendation, is RStudio, which can be downloaded from https://www.rstudio.com/. Another option is Emacs. An advantage of both Emacs and RStudio is that they are available on all major platforms (Windows, macOS, and Linux), so even if you switch computers, you can have a consistent IDE experience. The following is a screenshot of the RStudio IDE:
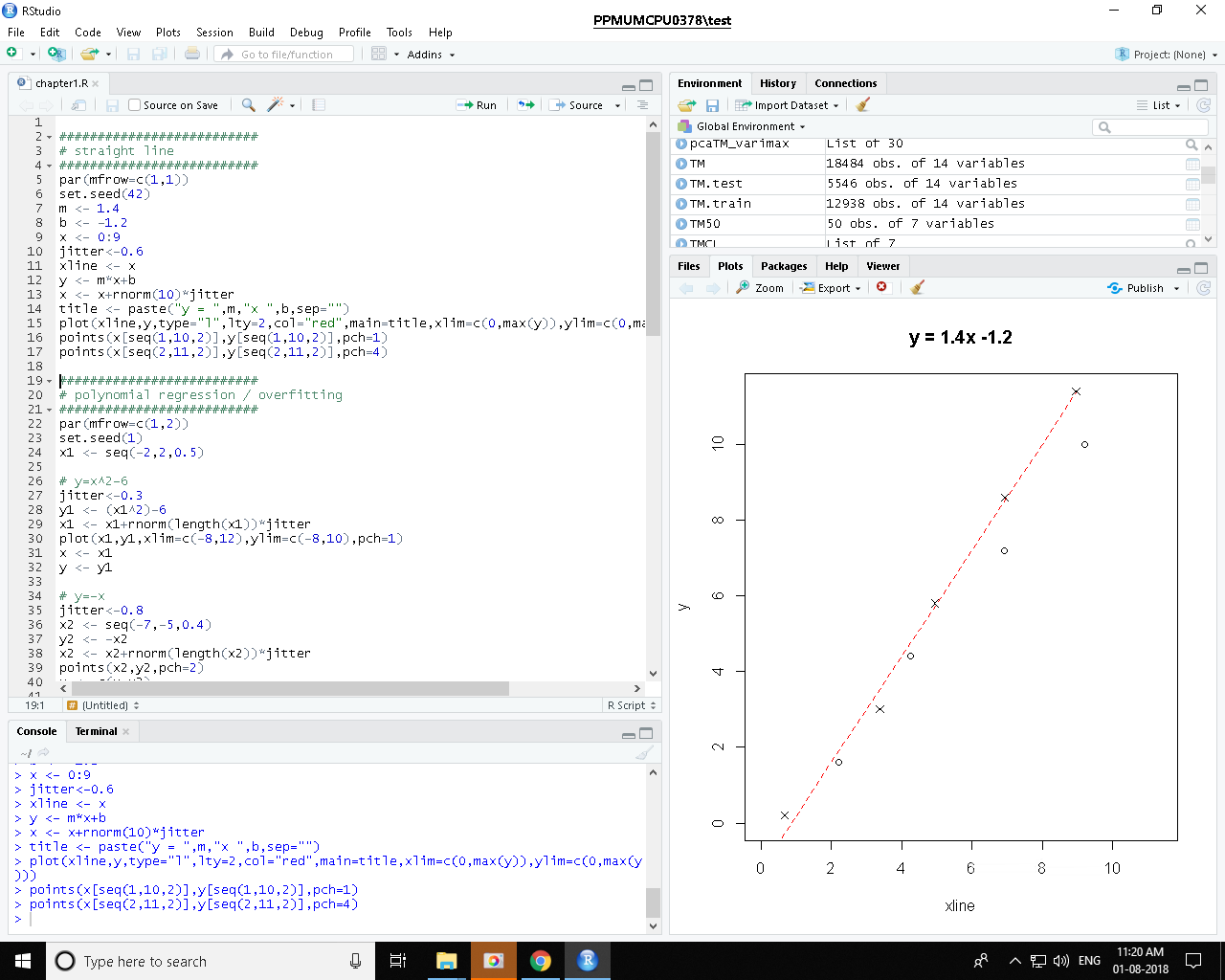
Using RStudio is a major improvement over the R GUI in Windows. There are a number of panes in RStudio that provide different perspectives on your work. The top-left pane shows the code, the bottom-left pane shows the console (results of running the code). The top-right pane shows the list of variables and their current values, the bottom-right pane shows the plots created by the code. All of these panes have further tabs to explore further perspectives.
As well as an IDE, RStudio (the company) have either developed or heavily supported other tools and packages for the R environment. We will use some of these tools, including the R Markdown and R Shiny applications. R Markdown is similar to Jupyter or IPython notebooks; it allows you to combine code, output (for example, plots), and documentation in one script. R Markdown was used to create sections of this book where code and descriptive text are interwoven. R Markdown is a very good tool to ensure that your data science experiments are documented correctly. By embedding the documentation within the analysis, they are more likely to stay synchronized. R Markdown can output to HTML, Word, or PDF. The following is an example of an R Markdown script on the left and the output on the right:
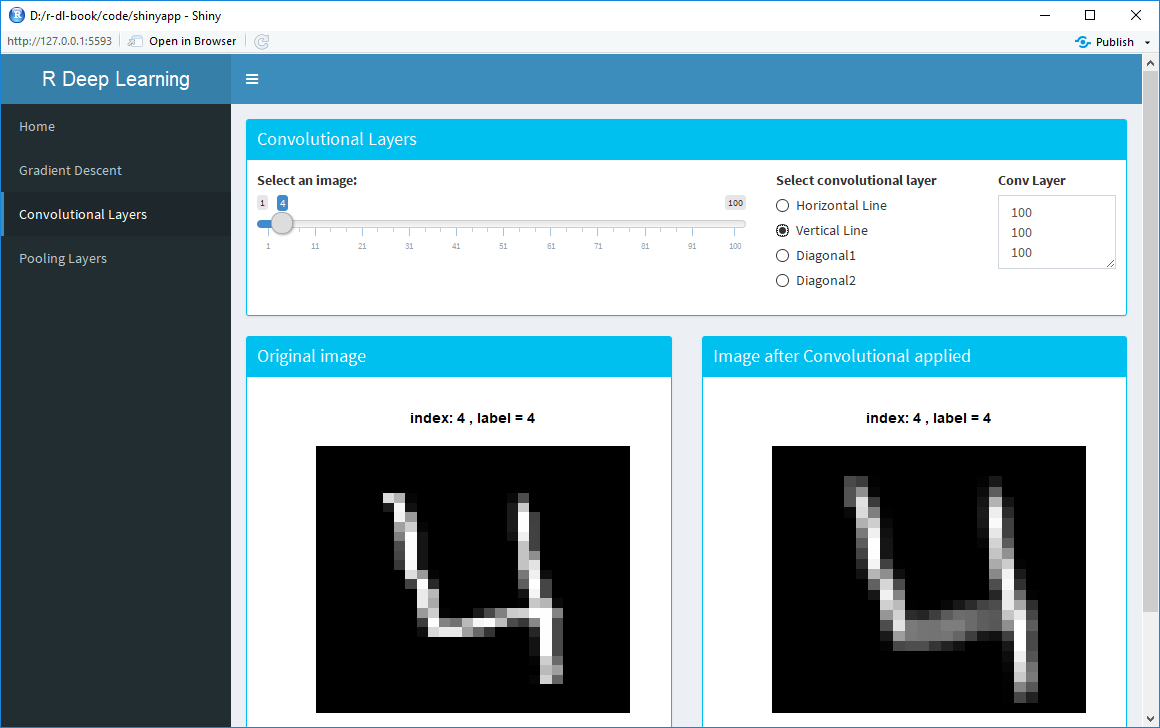
We will also use R Shiny to create web applications using R. This is an excellent method to create interactive applications to demonstrate key functionality. The following screenshot is an example of an R Shiny web application, which we will see in Chapter 5, Image Classification Using Convolutional Neural Networks:
Once you have R installed, you can look at adding packages that can fit basic neural networks. The nnet package is one package and it can fit feed-forward neural networks with one hidden layer, such as the one shown in Figure 1.6. For more details on the nnet package, see Venables, W. N. and Ripley, B. D. (2002). The neuralnet package fits neural networks with multiple hidden layers and can train them using back-propagation. It also allows custom error and neuron-activation functions. We will also use the RSNNS package, which is an R wrapper of the Stuttgart Neural Network Simulator (SNNS). The SNNS was originally written in C, but was ported to C++. The RSNNS package makes many model components from SNNS available, making it possible to train a wide variety of models. For more details on the RSNNS package, see Bergmeir, C., and Benitez, J. M. (2012). We will see examples of how to use these models in Chapter 2, Training a Prediction Model.
The deepnet package provides a number of tools for deep learning in R. Specifically, it can train RBMs and use these as part of DBNs to generate initial values to train deep neural networks. The deepnet package also allows for different activation functions, and the use of dropout for regularization.






















