






















































Exploring non-interactive applications
The other major type of natural language application is non-interactive, or offline applications. The primary work done in these applications is done by an NLP component. The other components in the preceding system diagram are not normally needed. These applications are performed on existing text, without a user being present. This means that real-time processing is not necessary because the user isn’t waiting for an answer. Similarly, the system doesn’t have to wait for the user to decide what to say so that, in many cases, processing can occur much more quickly than in the case of an interactive application.
Classification
A very important and widely used class of non-interactive natural language applications is document classification, or assigning documents to categories based on their content. Classification has been a major application area in NLP for many years and has been addressed with a wide variety of approaches.
One simple example of classification is a web application that answers customers’ frequently asked questions (FAQs) by classifying a query into one of a set of given categories and then providing answers that have been previously prepared for each category. For this application, a classification system would be a better solution than simply allowing customers to select their questions from a list because an application could sort questions into hundreds of FAQ categories automatically, saving the customer from having to scroll through a huge list of categories. Another example of an interesting classification problem is automatically assigning genres to movies – for example, based on reviews or plot summaries.
Sentiment analysis
Sentiment analysis is a specialized type of classification where the goal is to classify texts such as product reviews into those that express positive and negative sentiments. It might seem that just looking for positive or negative words would work for sentiment analysis, but in this example, we can see that despite many negative words and phrases (concern, break, problem, issues, send back, and hurt my back), the review is actually positive:
“I was concerned that this chair, although comfortable, might break before I had it for very long because the legs were so thin. This didn’t turn out to be a problem. I thought I might have to send it back. I haven’t had any issues, and it’s the one chair I have that doesn’t hurt my back.”
More sophisticated NLP techniques, taking context into account, are needed to recognize that this is a positive review. Sentiment analysis is a very valuable application because it is difficult for companies to do this manually if there are thousands of existing product reviews and new product reviews are constantly being added. Not only do companies want to see how their products are viewed by customers, but it is also very valuable for them to know how reviews of competing products compare to reviews of their own products. If there are dozens of similar products, this greatly increases the number of reviews relevant to the classification. A text classification application can automate a lot of this process. This is a very active area of investigation in the academic NLP community.
Spam and phishing detection
Spam detection is another very useful classification application, where the goal is to sort email messages into messages that the user wants to see and spam that should be discarded. This application is not only useful but also challenging because spammers are constantly trying to circumvent spam detection algorithms. This means that spam detection techniques have to evolve along with new ways of creating spam. For example, spammers often misspell keywords that might normally indicate spam by substituting the numeral 1 for the letter l, or substituting the numeral 0 for the letter o. While humans have no trouble reading words that are misspelled in this way, keywords that the computer is looking for will no longer match, so spam detection techniques must be developed to find these tricks.
Closely related to spam detection is detecting messages attempting to phish a user or get them to click on a link or open a document that will cause malware to be loaded onto their system. Spam is, in most cases, just an annoyance, but phishing is more serious, since there can be extremely destructive consequences if the user clicks on a phishing link. Any techniques that improve the detection of phishing messages will, therefore, be very beneficial.
Fake news detection
Another very important classification application is fake news detection. Fake news refers to documents that look very much like real news but contain information that isn’t factual and is intended to mislead readers. Like spam detection and phishing detection, fake news detection is challenging because people who generate fake news are actively trying to avoid detection. Detecting fake news is not only important for safeguarding reasons but also from a platform perspective, as users will begin to distrust platforms that consistently report fake news.
Document retrieval
Document retrieval is the task of finding documents that address a user’s search query. The best example of this is a routine web search of the kind most of us do many times a day. Web searches are the most well-known example of document retrieval, but document retrieval techniques are also used in finding information in any set of documents – for example, in the free-text fields of databases or forms.
Document retrieval is based on finding good matches between users’ queries and the stored documents, so analyzing both users’ queries and documents is required. Document retrieval can be implemented as a keyword search, but simple keyword searches are vulnerable to two kinds of errors. First, keywords in a query might be intended in a different sense than the matching keywords in documents. For example, if a user is looking for a new pair of glasses, thinking of eyeglasses, they don’t want to see results for drinking glasses. The other type of error is where relevant results are not found because keywords don’t match. This might happen if a user uses just the keyword glasses, and results that might have been found with the keywords spectacles or eyewear might be missed, even if the user is interested in those. Using NLP technology instead of simple keywords can help provide more precise results.
Analytics
Another important and broad area of natural language applications is analytics. Analytics is an umbrella term for NLP applications that attempt to gain insights from text, often the transcribed text from spoken interactions. A good example is looking at the transcriptions of interactions between customers and call center agents to find cases where the agent was confused by the customer’s question or provided wrong information. The results of analytics can be used in the training of call center agents. Analytics can also be used to examine social media posts to find trending topics.
Information extraction
Information extraction is a type of application where structured information, such as the kind of information that could be used to populate a database, is derived from text such as newspaper articles. Important information about an event, such as the date, time, participants, and locations, can be extracted from texts reporting news. This information is quite similar to the intents and entities discussed previously when we talked about chatbots and voice assistants, and we will find that many of the same processing techniques are relevant to both types of applications.
An extra problem that occurs in information extraction applications is named entity recognition (NER), where references to real people, organizations, and locations are recognized. In extended texts such as newspaper articles, there are often multiple ways of referring to the same individual. For example, Joe Biden might be referred to as the president, Mr. Biden, he, or even the former vice-president. In identifying references to Joe Biden, an information extraction application would also have to avoid misinterpreting a reference to Dr. Biden as a reference to Joe Biden, since that would be a reference to his wife.
Translation
Translation between languages, also known as machine translation, has been one of the most important NLP applications since the field began. Machine translation hasn’t been solved in general, but it has made enormous progress in the past few years. Familiar web applications such as Google Translate and Bing Translate usually do a very good job on text such as web pages, although there is definitely room for improvement.
Machine translation applications such as Google and Bing are less effective on other types of text, such as technical text that contains a great deal of specialized vocabulary or colloquial text of the kind that might be used between friends. According to Wikipedia (https://en.wikipedia.org/wiki/Google_Translate), Google Translate can translate 109 languages. However, it should be kept in mind that the accuracy for the less widely spoken languages is lower than that for the more commonly spoken languages, as discussed in the Global considerations section.
Summarization, authorship, correcting grammar, and other applications
Just as there are many reasons for humans to read and understand texts, there are also many applications where systems that are able to read and understand text can be helpful. Detecting plagiarism, correcting grammar, scoring student essays, and determining the authorship of texts are just a few. Summarizing long texts is also very useful, as is simplifying complex texts. Summarizing and simplifying text can also be applied when the original input is non-interactive speech, such as podcasts, YouTube videos, or broadcasts.
Figure 1.5 is a graphical summary of the discussion of non-interactive applications:
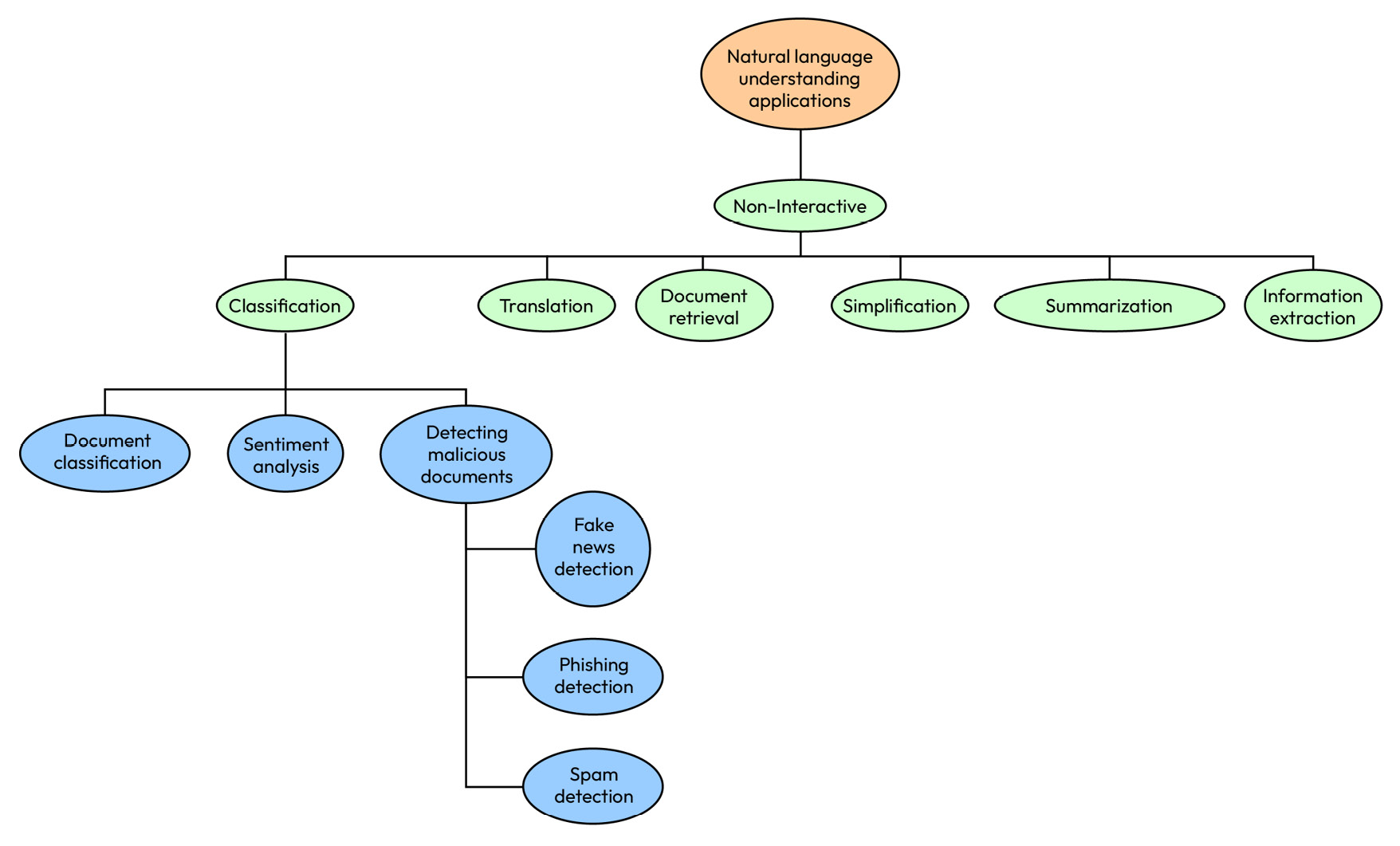
Figure 1.5 – A hierarchy of non-interactive applications
Figure 1.5 shows how the non-interactive NLP applications we’ve been discussing are related to each other. It’s clear that classification is a major application area, and we will look at it in depth in Chapter 9, Chapter 10, and Chapter 11.
A summary of the types of applications
In the previous sections, we saw how the different types of interactive and non-interactive applications we have discussed relate to each other. It is apparent that NLP can be applied to solving many different and important problems. In the rest of the book, we’ll dive into the specific techniques that are appropriate for solving different kinds of problems, and you’ll learn how to select the most effective technologies for each problem.


