






















































Understanding the basics
The compilation of C++ source code appears to be a fairly straightforward process. Let’s start with the classic Hello World example.
The following code is found in ch01/01-hello/hello.cpp, Hello world in the C++ language:
#include <iostream>
int main() {
std::cout << "Hello World!" << std::endl;
return 0;
}
To produce an executable, we of course need a C++ compiler. CMake doesn’t come with one, so you’ll need to pick and install one on your own. Popular choices include:
- Microsoft Visual C++ compiler
- The GNU compiler collection
- Clang/LLVM
Most readers are familiar with a compiler, as it is indispensable when learning C++, so we won’t go into picking one and installation. Examples in this book will use GNU GCC as it is a well-established, open-source software compiler available for free across many platforms.
Assuming that we have our compiler already installed, running it is similar for most vendors and systems. We should call it with the filename as an argument:
$ g++ hello.cpp -o hello
Our code is correct, so the compiler will silently produce an executable binary file that our machine can understand. We can run it by calling its name:
$ ./hello
Hello World!
Running one command to build your program is simple enough; however, as our projects grow, you will quickly understand that keeping everything in a single file is simply not possible. Clean code practices recommend that source code files should be kept small and in well-organized structures. The manual compilation of every file can be a tiresome and fragile process. There must be a better way.
What is CMake?
Let’s say we automate building by writing a script that goes through our project tree and compiles everything. To avoid any unnecessary compilations, our script will detect whether the source has been modified since the last time we ran the script. Now, we’d like a convenient way to manage arguments that are passed to the compiler for each file – preferably, we’d like to do that based on configurable criteria. Additionally, our script should know how to link all of the compiled files into a single binary file or, even better, build whole solutions that can be reused and incorporated as modules into bigger projects.
Building software is a very versatile process and can span multiple different aspects:
- Compiling executables and libraries
- Managing dependencies
- Testing
- Installing
- Packaging
- Producing documentation
- Testing some more
It would take a very long time to come up with a truly modular and powerful C++ building utility that is fit for every purpose. And it did. Bill Hoffman at Kitware implemented the first versions of CMake over 20 years ago. As you might have already guessed, it was very successful. Today, it has a lot of features and extensive support from the community. CMake is being actively developed and has become the industry standard for C and C++ programmers.
The problem of building code in an automated way is much older than CMake, so naturally, there are plenty of options out there: GNU Make, Autotools, SCons, Ninja, Premake, and more. But why does CMake have the upper hand?
There are a couple of things about CMake that I find (granted, subjectively) important:
- It stays focused on supporting modern compilers and toolchains.
- CMake is truly cross-platform – it supports building for Windows, Linux, macOS, and Cygwin.
- It generates project files for popular IDEs: Microsoft Visual Studio, Xcode, and Eclipse CDT. Additionally, it is a project model for others, like CLion.
- CMake operates on just the right level of abstraction – it allows you to group files in reusable targets and projects.
- There are tons of projects that are built with CMake and offer an easy way to plug them into your project.
- CMake views testing, packaging, and installing as an inherent part of the build process.
- Old, unused features get deprecated to keep CMake lean.
CMake provides a unified, streamlined experience across the board. It doesn’t matter whether you’re building your software in an IDE or directly from the command line; what’s really important is that it takes care of post-build stages as well.
Your CI/CD pipeline can easily use the same CMake configuration and build projects using a single standard even if all of the preceding environments differ.
How does it work?
You might be under the impression that CMake is a tool that reads source code on one end and produces binaries on the other – while that’s true in principle, it’s not the full picture.
CMake can’t build anything on its own – it relies on other tools in the system to perform the actual compilation, linking, and other tasks. You can think of it as the orchestrator of your building process: it knows what steps need to be done, what the end goal is, and how to find the right workers and materials for the job.
This process has three stages:
- Configuration
- Generation
- Building
Let’s explore them in some detail.
The configuration stage
This stage is about reading project details stored in a directory, called the source tree, and preparing an output directory or build tree for the generation stage.
CMake starts by checking whether the project was configured before and reads cached configuration variables from a CMakeCache.txt file. On a first run, this is not the case, so it creates an empty build tree and collects all of the details about the environment it is working in: for example, what the architecture is, what compilers are available, and what linkers and archivers are installed. Additionally, it checks whether a simple test program can be compiled correctly.
Next, the CMakeLists.txt project configuration file is parsed and executed (yes, CMake projects are configured with CMake’s coding language). This file is the bare minimum of a CMake project (source files can be added later). It tells CMake about the project structure, its targets, and its dependencies (libraries and other CMake packages).
During this process, CMake stores collected information in the build tree, such as system details, project configurations, logs, and temp files, which are used for the next step. Specifically, a CMakeCache.txt file is created to store more stable information (such as paths to compilers and other tools), which saves time when the whole build sequence is executed again.
The generation stage
After reading the project configuration, CMake will generate a buildsystem for the exact environment it is working in. Buildsystems are simply cut-to-size configuration files for other build tools (for example, Makefiles for GNU Make or Ninja and IDE project files for Visual Studio). During this stage, CMake can still apply some final touches to the build configuration by evaluating generator expressions.
The generation stage is executed automatically after the configuration stage. For this reason, this book and other resources sometimes refer to both of these stages interchangeably when mentioning the “configuration” or “generation” of a buildsystem. To explicitly run just the configuration stage, you can use the cmake-gui utility.
The building stage
To produce the final artifacts specified in our project (like executables and libraries), CMake has to run the appropriate build tool. This can be invoked directly, through an IDE, or using the appropriate CMake command. In turn, these build tools will execute steps to produce target artifacts with compilers, linkers, static and dynamic analysis tools, test frameworks, reporting tools, and anything else you can think of.
The beauty of this solution lies in the ability to produce buildsystems on demand for every platform with a single configuration (that is, the same project files):
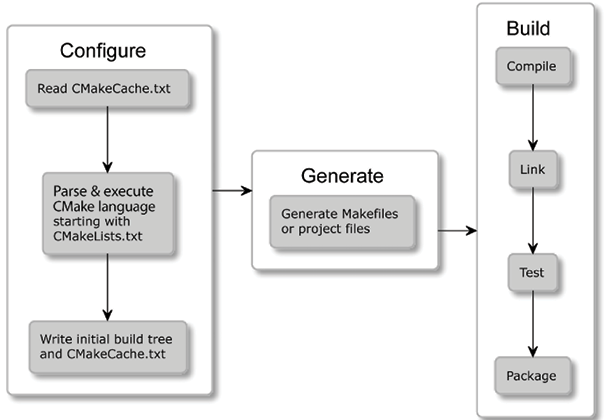
Figure 1.1: The stages of CMake
Do you remember our hello.cpp application from the Understanding the basics section? It is really easy to build it with CMake. All we need is the following CMakeLists.txt file in the same directory as our source.
ch01/01-hello/CMakeLists.txt
cmake_minimum_required(VERSION 3.26)
project(Hello)
add_executable(Hello hello.cpp)
After creating this file, execute the following commands in the same directory:
cmake -B <build tree>
cmake --build <build tree>
Note that <build tree> is a placeholder that should be replaced with a path to a temporary directory that will hold generated files.
Here is the output from an Ubuntu system running in Docker (Docker is a virtual machine that can run within other systems; we’ll discuss it in the Installing CMake on different platforms section). The first command generates a buildsystem:
~/examples/ch01/01-hello# cmake -B ~/build_tree
-- The C compiler identification is GNU 11.3.0
-- The CXX compiler identification is GNU 11.3.0
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/cc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Configuring done (1.0s)
-- Generating done (0.1s)
-- Build files have been written to: /root/build_tree
The second command actually builds the project:
~/examples/ch01/01-hello# cmake --build ~/build_tree
Scanning dependencies of target Hello
[ 50%] Building CXX object CMakeFiles/Hello.dir/hello.cpp.o
[100%] Linking CXX executable Hello
[100%] Built target Hello
All that’s left is to run the compiled program:
~/examples/ch01/01-hello# ~/build_tree/Hello
Hello World!
Here, we have generated a buildsystem that is stored in the build tree directory. Following this, we executed the build stage and produced a final binary that we were able to run.
Now you know what the result looks like, I’m sure you will be full of questions: what are the prerequisites to this process? What do these commands mean? Why do we need two of them? How do I write my own project files? Don’t worry – these questions will be answered in the following sections.
This book will provide you with the most important information that is relevant to the current version of CMake (at the time of writing, this is 3.26). To provide you with the best advice, I have explicitly avoided any deprecated and no longer recommended features and I highly recommend using, at the very least, CMake version 3.15, which is considered the modern CMake. If you require more information, you can find the latest, complete documentation online at https://cmake.org/cmake/help/.



