






















































Linux kernel interrupt management
Apart from servicing processes and user requests, another job of the Linux kernel is managing and speaking with hardware. This is either from the CPU to the device or from the device to the CPU. This is achieved by means of interrupts. An interrupt is a signal that’s sent to the processor by an external hardware device requesting immediate attention. Prior to an interrupt being visible to the CPU, this interrupt should be enabled by the interrupt controller, which is a device on its own, and whose main job consists of routing interrupts to CPUs.
An interrupt may have five states:
- Active: An interrupt that has been acknowledged by a processing element (PE) and is being handled. While being handled, another assertion of the same interrupt is not presented as an interrupt to a processing element, until the initial interrupt is no longer active.
- Pending (asserted): An interrupt that is recognized as asserted in hardware, or generated by software, and is waiting to be handled by the target PE. It is a common behavior for most hardware devices not to generate other interrupts until their “interrupt pending” bit has been cleared. A disabled interrupt can’t be pending as it is never asserted, and it is immediately dropped by the interrupt controller.
- Active and pending: An interrupt that is active from one assertion of the interrupt and is pending from a subsequent assertion.
- Inactive: An interrupt that is not active or pending. Deactivation clears the active state of the interrupt, and thereby allows the interrupt, when it is pending, to be taken again.
- Disabled/Deactivated: This is unknown to the CPU and not even seen by the interrupt controller. This will never be asserted. Disabled interrupts are lost.
Important note
There are interrupt controllers where disabling an interrupt means masking that interrupt, or vice versa. In the remainder of this book, we will consider disabling to be the same as masking, though this is not always true.
Upon reset, the processor disables all the interrupts until they are enabled again by the initialization code (this is the job of the Linux kernel in our case). The interrupts are enabled/disabled by setting/clearing the bits in the processor status/control registers. Upon an interrupt assertion (an interrupt occurred), the processor will check whether the interrupts are masked or not and will do nothing if they are masked. Once unmasked, the processor will pick one pending interrupt, if any (the order does not matter since it will do this for each pending interrupt until they are all serviced), and will execute a specially purposed function called the Interrupt Service Routine (ISR) that is associated with this interrupt. This ISR must be registered by the code (that is, our device driver, which relies on the kernel irq core code) at a special location called the vector table. Right before the processor starts executing this ISR, it does some context saving (including the unmasked status of interrupts) and then masks the interrupts on the local CPU (interrupts can be asserted and will be serviced once unmasked). Once the ISR is running, we can say that the interrupt is being serviced.
The following is the complete IRQ handling flow on ARM Linux. This happens when an interrupt occurs and the interrupts are enabled in the PSR:
- The ARM core will disable further interrupts occurring on the local CPU.
- The ARM core will then put the Current Program Status Register (CPSR) in the Saved Program Status Register (SPSR), put the current Program Counter (PC) in the Link Register (LR), and then switch to IRQ mode.
- Finally, the ARM processor will refer to the vector table and jumps to the exception handler. In our case, it jumps to the exception handler of IRQ, which in the Linux kernel corresponds to the
vector_stubmacro defined inarch/arm/kernel/entry-armv.S.These three steps are done by the ARM processor itself. Now, the kernel jumps into action:
- The
vector_stubmacro checks from what processor mode we used to get here – either kernel mode or user mode – and determines the macro to call accordingly; either__irq_useror__irq_svc. __irq_svc()will save the registers (fromr0tor12) on the kernel stack and then call theirq_handler()macro, which either callshandle_arch_irq()(present inarch/arm/include/asm/entry-macro-multi.S) ifCONFIG_MULTI_IRQ_HANDLERis defined, orarch_irq_handler_default()otherwise, withhandle_arch_irqbeing a global pointer to the function that’s set inarch/arm/kernel/setup.c(from within thesetup_arch()function).- Now, we need to identify the hardware-IRQ number, which is what
asm_do_IRQ()does. It then callshandle_IRQ()on that hardware-IRQ, which in turn calls__handle_domain_irq(), which will translate the hardware-irq into its corresponding Linux IRQ number (irq = irq_find_mapping(domain, hwirq)) and callgeneric_handle_irq()on the decoded Linux IRQ (generic_handle_irq(irq)). generic_handle_irq()will look for the IRQ descriptor structure (Linux’s view of an interrupt) that corresponds to the decoded Linux IRQ (struct irq_desc *desc = irq_to_desc(irq)) and callinggeneric_handle_irq_desc()on this descriptor), which will result indesc->handle_irq(desc).desc->handle_irqcorresponding to the high-level IRQ handler that was set usingirq_set_chip_and_handler()during the mapping of this IRQ.desc->handle_irq()may result in a call tohandle_level_irq(),handle_simple_irq(),handle_edge_irq(), and so on.- The high-level IRQ handler calls our ISR.
- Once the ISR has been completed,
irq_svcwill return and restore the processor state by restoring registers (r0-r12), the PC, and the CSPR.Important note
Going back to step 1, during an interrupt, the ARM core disables further IRQs on the local CPU. It is worth mentioning that in the earlier Linux kernel days, there were two families of interrupt handlers: those running with interrupts disabled (that is, with the old
IRQF_DISABLEDflag set) and those running with interrupts enabled: they were then interruptible. The former were called fast handlers, while the latter were called slow handlers. For the latter, interrupts were actually reenabled by the kernel prior to invoking the handler.Since the interrupt context has a really small stack size compared to the process stack, it makes no sense that we may run into a stack overflow if we are in an interrupt context (running a given IRQ handler) while other interrupts keep occurring, even the one being serviced. This is confirmed by the commit at https://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git/commit/?id=e58aa3d2d0cc, which deprecated the fact of running interrupt handlers with IRQs enabled. As of this patch, IRQs remain disabled (left untouched after ARM core disabled them on the local CPU) during the execution of an IRQ handler. Additionally, the aforementioned flags have been entirely removed by the commit at https://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git/commit/?id=d8bf368d0631, since Linux v4.1.
Designing an interrupt handler
Now that we’re familiar with the concept of bottom halves and deferring mechanisms, the time for us to implement interrupt handlers has come. In this section, we’ll take care of some specifics. Nowadays, the fact that interrupt handlers run with interrupts disabled (on the local CPU) means that we need to respect certain constraints in the ISR design:
- Execution time: Since IRQ handlers run with interrupts disabled on the local CPU, the code must be as short and as small as possible, as well as fast enough to ensure the previously disabled CPU-local interrupts are reenabled quickly in so that other IRQs are not missed. Time-consuming IRQ handlers may considerably alter the real-time properties of the system and slow it down.
- Execution context: Since interrupt handlers are executed in an atomic context, sleeping (or any other mechanism that may sleep, such as mutexes, copying data from kernel to user space or vice versa, and so on) is forbidden. Any part of the code that requires or involves sleeping must be deferred into another, safer context (that is, a process context).
An IRQ handler needs to be given two arguments: the interrupt line to install the handler for, and a unique device identifier of the peripheral (mostly used as a context data structure; that is, the pointer to the per-device or private structure of the associated hardware device):
typedef irqreturn_t (*irq_handler_t)(int, void *);
The device driver that wants to enable a given interrupt and register an ISR for it should call request_irq(), which is declared in <linux/interrupt.h>. This must be included in the driver code:
int request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev)
While the aforementioned API would require the caller to free the IRQ when it is no longer needed (that is, on driver detach), you can use the device managed variant, devm_request_irq(), which contains internal logic that allows it to take care of releasing the IRQ line automatically. It has the following prototype:
int devm_request_irq(struct device *dev, unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev)
Except for the extra dev parameter (which is the device that requires the interrupt), both devm_request_irq() and request_irq() expect the following arguments:
irq, which is the interrupt line (that is, the interrupt number of the issuing device). Prior to validating the request, the kernel will make sure the requested interrupt is valid and that it is not already assigned to another device, unless both devices request that this IRQ line needs to be shared (with the help of flags).handler, which is a function pointer to the interrupt handler.flags, which represents the interrupt flags.name, an ASCII string representing the name of the device generating or claiming this interrupt.devshould be unique to each registered handler. This cannot beNULLfor shared IRQs since it is used to identify the device via the kernel IRQ core. The most common way of using it is to provide a pointer to the device structure or a pointer to any per-device (that’s potentially useful to the handler) data structure. This is because when an interrupt occurs, both the interrupt line (irq) and this parameter will be passed to the registered handler, which can use this data as context data for further processing.
flags mangle the state or behavior of the IRQ line or its handler by means of the following masks, which can be OR’ed to form the final desired bit mask according to your needs:
#define IRQF_TRIGGER_RISING 0x00000001 #define IRQF_TRIGGER_FALLING 0x00000002 #define IRQF_TRIGGER_HIGH 0x00000004 #define IRQF_TRIGGER_LOW 0x00000008 #define IRQF_SHARED 0x00000080 #define IRQF_PROBE_SHARED 0x00000100 #define IRQF_NOBALANCING 0x00000800 #define IRQF_IRQPOLL 0x00001000 #define IRQF_ONESHOT 0x00002000 #define IRQF_NO_SUSPEND 0x00004000 #define IRQF_FORCE_RESUME 0x00008000 #define IRQF_NO_THREAD 0x00010000 #define IRQF_EARLY_RESUME 0x00020000 #define IRQF_COND_SUSPEND 0x00040000
Note that flags can also be zero. Let’s take a look at some important flags. I’ll leave the rest for you to explore in include/linux/interrupt.h:
IRQF_TRIGGER_HIGHandIRQF_TRIGGER_LOWflags are to be used for level-sensitive interrupts. The former is for interrupts triggered at high level and the latter is for the low-level triggered interrupts. Level-sensitive interrupts are triggered as long as the physical interrupt signal is high. If the interrupt source is not cleared by the end of its interrupt handler in the kernel, the operating system will repeatedly call that kernel interrupt handler, which may lead platform to hang. In other words, when the handler services the interrupt and returns, if the IRQ line is still asserted, the CPU will signal the interrupt again immediately. To prevent such a situation, the interrupt must be acknowledged (that is, cleared or de-asserted) by the kernel interrupt handler immediately when it is received.However, those flags are safe with regard to interrupt sharing because if several devices pull the line active, an interrupt will be signaled (assuming the IRQ is enabled or as soon as it becomes so) until all drivers have serviced their devices. The only drawback is that it may lead to lockup if a driver fails to clear its interrupt source.
IRQF_TRIGGER_RISINGandIRQF_TRIGGER_FALLINGconcern edge-triggered interrupts, rising and falling edges respectively. Such interrupts are signaled when the line changes from inactive to active state, but only once. To get a new request the line must go back to inactive and then to active again. Most of the time, no special action is required in software in order to acknowledge this type of interrupt.When using edge-triggered interrupts however, interrupts may be lost, especially in the context of a shared interrupt line: if one device pulls the line active for too long a time, when another device pulls the line active, no edge will be generated, the second request will not be seen by the processor and then will be ignored. With a shared edge-triggered interrupts, if a hardware does not de-assert the IRQ line, no other interrupt will be notified for either shared device.
Important note
As a quick reminder, you can just remember that level triggered interrupts signal a state, while edge triggered ones signal an event.Moreover, when requesting an interrupt without specifying an
IRQF_TRIGGERflag, the setting should be assumed to be as already configured, which may be as per machine or firmware initialization. In such cases, you can refer to the device tree (if specified in there) for example to see what this assumed configuration is.IRQF_SHARED: This allows the interrupt line to be shared among several devices. However, each device driver that needs to share the given interrupt line must set this flag; otherwise, the registration will fail.IRQF_NOBALANCING: This excludes the interrupt from IRQ balancing, which is a mechanism that consists of distributing/relocating interrupts across CPUs, with the goal of increasing performance. This prevents the CPU affinity of this IRQ from being changed. This flag can be used to provide a flexible setup for clocksources in order to prevent the event from being misattributed to the wrong core. This misattribution may result in the IRQ being disabled because if the CPU handling the interrupt is not the one that triggered it, the handler will returnIRQ_NONE. This flag is only meaningful on multicore systems.IRQF_IRQPOLL: This flag allows the irqpoll mechanism to be used, which fixes interrupt problems. This means that this handler should be added to the list of known interrupt handlers that can be looked for when a given interrupt is not handled.IRQF_ONESHOT: Normally, the actual interrupt line being serviced is enabled after its hard-IRQ handler completes, whether it awakes a threaded handler or not. This flag keeps the interrupt line disabled after the hard-IRQ handler completes. This flag must be set on threaded interrupts (we will discuss this later) for which the interrupt line must remain disabled until the threaded handler has completed. After this, it will be enabled.IRQF_NO_SUSPEND: This does not disable the IRQ during system hibernation/suspension. This means that the interrupt is able to save the system from a suspended state. Such IRQs may be timer interrupts, which may trigger and need to be handled while the system is suspended. The whole IRQ line is affected by this flag in that if the IRQ is shared, every registered handler for this shared line will be executed, not just the one who installed this flag. You should avoid usingIRQF_NO_SUSPENDandIRQF_SHAREDat the same time as much as possible.IRQF_FORCE_RESUME: This enables the IRQ in the system resume path, even ifIRQF_NO_SUSPENDis set.IRQF_NO_THREAD: This prevents the interrupt handler from being threaded. This flag overrides thethreadirqskernel (used on RT kernels, such as when applying thePREEMPT_RTpatch) command-line option, which forces every interrupt to be threaded. This flag was introduced to address the non-threadability of some interrupts (for example, timers, which cannot be threaded even when all the interrupt handlers are forced to be threaded).IRQF_TIMER: This marks this handler as being specific to the system timer interrupts. It helps not to disable the timer IRQ during system suspend to ensure that it resumes normally and does not thread them when full preemption (seePREEMPT_RT) is enabled. It is just an alias forIRQF_NO_SUSPEND | IRQF_NO_THREAD.IRQF_EARLY_RESUME: This resumes IRQ early at the resume time of system core (syscore) operations instead of at device resume time. Go to https://lkml.org/lkml/2013/11/20/89 to see the commit introducing its support.
We must also consider the return type, irqreturn_t, of interrupt handlers since they may involve further actions once the handler is returned:
IRQ_NONE: On a shared interrupt line, once the interrupt occurs, the kernel irqcore successively walks through the handlers that have been registered for this line and executes them in the order they have been registered. The driver then has the responsibility of checking whether it is their device that issued the interrupt. If the interrupt does not come from its device, it must returnIRQ_NONEin order to instruct the kernel to call the next registered interrupt handler. This return value is mostly used on shared interrupt lines since it informs the kernel that the interrupt does not come from our device. However, if 99,900 of the previous 100,000 interrupts of a given IRQ line have not been handled, the kernel assumes that this IRQ is stuck in some manner, drops a diagnostic, and tries to turn the IRQ off. For more information on this, have a look at the__report_bad_irq()function in the kernel source tree.IRQ_HANDLED: This value should be returned if the interrupt has been handled successfully. On a threaded IRQ, this value acknowledges the interrupt without waking the thread handler up.IRQ_WAKE_THREAD: On a thread IRQ handler, this value must be returned the by hard-IRQ handler in order to wake the handler thread. In this case,IRQ_HANDLEDmust only be returned by the threaded handler that was previously registered withrequest_threaded_irq(). We will discuss this later in the Threaded IRQ handlers section of this chapter.Important note
You must be very careful when reenabling interrupts in the handler. Actually, you must never reenable IRQs from within your IRQ handler as this would involve allowing “interrupts reentrancy”. In this case, it is your responsibility to address this.
In the unloading path of your driver (or once you think you do not need the IRQ line anymore during your driver runtime life cycle, which is quite rare), you must release your IRQ resource by unregistering your interrupt handler and potentially disabling the interrupt line. The free_irq() interface does this for you:
void free_irq(unsigned int irq, void *dev_id)
That being said, if an IRQ allocated with devm_request_irq() needs to be freed separately, devm_free_irq() must be used. It has the following prototype:
void devm_free_irq(struct device *dev, unsigned int irq, void *dev_id)
This function has an extra dev argument, which is the device to free the IRQ for. This is usually the same as the one that the IRQ has been registered for. Except for dev, this function takes the same arguments and performs the same function as free_irq(). However, instead of free_irq(), it should be used to manually free IRQs that have been allocated with devm_request_irq().
Both devm_request_irq() and free_irq() remove the handler (identified by dev_id when it comes to shared interrupts) and disable the line. If the interrupt line is shared, the handler is simply removed from the list of handlers for this IRQ, and the interrupt line is disabled in the future when the last handler is removed. Moreover, if possible, your code must ensure the interrupt is really disabled on the card it drives before calling this function, since omitting this may leads to spurious IRQs.
There are few things that are worth mentioning here about interrupts that you should never forget:
- Since interrupt handlers in Linux run with IRQs disabled on the local CPU and the current line is masked in all other cores, they don’t need to be reentrant, since the same interrupt will never be received until the current handler has completed. However, all other interrupts (on other cores) remain enabled (or should we say untouched), so other interrupts keep being serviced, even though the current line is always disabled, as well as further interrupts on the local CPU. Consequently, the same interrupt handler is never invoked concurrently to service a nested interrupt. This greatly simplifies writing your interrupt handler.
- Critical regions that need to run with interrupts disabled should be limited as much as possible. To remember this, tell yourselves that your interrupt handler has interrupted other code and needs to give CPU back.
- Interrupt handlers cannot block as they do not run in a process context.
- They may not transfer data to/from user space since this may block.
- They may not sleep or rely on code that may lead to sleep, such as invoking
wait_event(), memory allocation with anything other thanGFP_ATOMIC, or using a mutex/semaphore. The threaded handler can handle this. - They may not trigger nor call
schedule(). - Only one interrupt on a given line can be pending (its interrupt flag bits get set when its interrupt condition occurs, regardless of the state of its corresponding enabled bit or the global enabled bit). Any further interrupt of this line is lost. For example, if you are processing an RX interrupt while five more packets are received at the same time, you should not expect five times more interrupts to appear sequentially. You’ll only be notified once. If the processor doesn’t service the ISR first, there’s no way to check how many RX interrupts will occur later. This means that if the device generates another interrupt before the handler function returns
IRQ_HANDLED, the interrupt controller will be notified of the pending interrupt flag and the handler will get called again (only once), so you may miss some interrupts if you are not fast enough. Multiple interrupts will happen while you are still handling the first one.Important note
If an interrupt occurs while it is disabled (or masked), it will not be processed at all (masked in the flow handler), but will be recognized as asserted and will remain pending so that it will be processed when enabled (or unmasked).
The interrupt context has its own (fixed and quite low) stack size. Therefore, it totally makes sense to disable IRQs while running an ISR as reentrancy could cause stack overflow if too many preemptions happen.
The concept of non-reentrancy for an interrupt means that if an interrupt is already in an active state, it cannot enter it again until the active status is cleared.
The concept of top and bottom halves
External devices send interrupt requests to the CPU either to signal a particular event or to request a service. As stated in the previous section, bad interrupt management may considerably increase system latency and decrease its real-time quality. We also stated that interrupt processing – that is, the hard-IRQ handler – must be very fast, not only to keep the system responsive, but also so that it doesn’t miss other interrupt events.
Take a look at the following diagram:
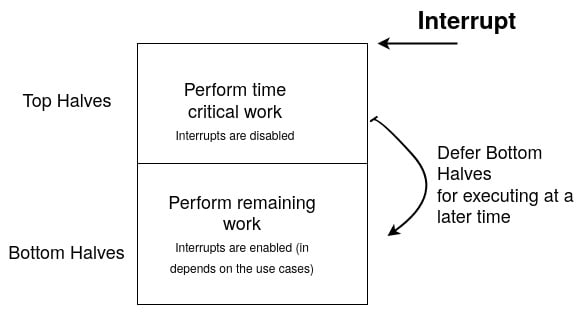
Figure 1.2 – Interrupt splitting flow
The basic idea is that you split the interrupt handler into two parts. The first part is a function) that will run in a so-called hard-IRQ context, with interrupts disabled, and perform the minimum required work (such as doing some quick sanity checks, time-sensitive tasks, read/write hardware registers, and processing this data and acknowledging the interrupt on the device that raised it). This first part is the so-called top-half on Linux systems. The top-half then schedules a (sometimes threaded) handler, which then runs a so-called bottom-half function, with interrupts re-enabled. This is the second part of the interrupt. The bottom-half may then perform time-consuming tasks (such as buffer processing) – tasks that may sleep, depending on the deferring mechanism.
This splitting would considerably increase the system’s responsiveness as the time spent with IRQs disabled is reduced to its minimum. When the bottom halves are run in kernel threads, they compete for the CPU with other processes on the runqueue. Moreover, they may have their real-time properties set. The top half is actually the handler that’s registered using request_irq(). When using request_threaded_irq(), as we will see in the next section, the top half is the first handler that’s given to the function.
As we described previously, a bottom half represents any task (or work) that’s scheduled from within an interrupt handler. Bottom halves are designed using a work-deferring mechanism, which we have seen previously. Depending on which one you choose, it may run in a (software) interrupt context or in a process context. This includes SoftIRQs, tasklets, workqueues, and threaded IRQs.
Important note
Tasklets and SoftIRQs do not actually fit into the so-called “thread interrupts” mechanism since they run in their own special contexts.
Since softIRQ handlers run at a high priority with scheduler preemption disabled, they do not relinquish the CPU to processes/threads until they complete, so care must be taken while using them for bottom-half delegation. Nowadays, since the quantum that’s allocated for a particular process may vary, there is no strict rule regarding how long the softIRQ handler should take to complete so that it doesn’t slow the system down as the kernel would not be able to give CPU time to other processes. I would say that this should be no longer than a half of jiffy.
The hard-IRQ handler (the top half) has to be as fast as possible, and most of time, it should just be reading and writing in I/O memory. Any other computation should be deferred to the bottom half, whose main goal is to perform any time-consuming and minimal interrupt-related work that’s not performed by the top half. There are no clear guidelines on repartitioning work between the top and bottom halves. The following is some advice:
- Hardware-related work and time-sensitive work should be performed in the top half.
- If the work doesn’t need to be interrupted, perform it in the top half.
- From my point of view, everything else can be deferred – that is, performed in the bottom half – so that it runs with interrupts enabled and when the system is less busy.
- If the hard-IRQ handler is fast enough to process and acknowledge interrupts consistently within a few microseconds, then there is absolutely no need to use bottom-half delegations at all.
Next, we will look at threaded IRQ handlers.
Threaded IRQ handlers
Threaded interrupt handlers were introduced to reduce the time spent in the interrupt handler and deferring the rest of the work (that is, processing) out to kernel threads. So, the top half (hard-IRQ handler) would consist of quick sanity checks such as ensuring that the interrupt comes from its device and waking the bottom half accordingly. A threaded interrupt handler runs in its own thread, either in the thread of their parent (if they have one) or in a separate kernel thread. Moreover, the dedicated kernel thread can have its real-time priority set, though it runs at normal real-time priority (that is, MAX_USER_RT_PRIO/2 as shown in the setup_irq_thread() function in kernel/irq/manage.c).
The general rule behind threaded interrupts is simple: keep the hard-IRQ handler as minimal as possible and defer as much work to the kernel thread as possible (preferably all work). You should use request_threaded_irq() (defined in kernel/irq/manage.c) if you want to request a threaded interrupt handler:
int request_threaded_irq(unsigned int irq, irq_handler_t handler, irq_handler_t thread_fn, unsigned long irqflags, const char *devname, void *dev_id)
This function accepts two special parameters handler and thread_fn. The other parameters are the same as they are for request_irq():
handlerimmediately runs when the interrupt occurs in the interrupt context, and acts as a hard-IRQ handler. Its job usually consists of reading the interrupt cause (in the device’s status register) to determine whether or how to handle the interrupt (this is frequent on MMIO devices). If the interrupt does not come from its device, this function should returnIRQ_NONE. This return value usually only makes sense on shared interrupt lines. In the other case, if this hard-IRQ handler can finish interrupt processing fast enough (this is not a universal rule, but let’s say no longer than half a jiffy – that is, no longer than 500 µs ifCONFIG_HZ, which defines the value of a jiffy, is set to 1,000) for a set of interrupt causes, it should returnIRQ_HANDLEDafter processing in order to acknowledge the interrupts. Interrupt processing that does not fall into this time lapse should be deferred to the threaded IRQ handler. In this case, the hard-IRQ handler should returnIRQ_WAKE_T HREADin order to awake the threaded handler. ReturningIRQ_WAKE_THREADonly makes sense when thethread_fnhandler is also registered.thread_fnis the threaded handler that’s added to the scheduler runqueue when the hard-IRQ handler function returnsIRQ_WAKE_THREAD. Ifthread_fnisNULLwhilehandleris set and it returnsIRQ_WAKE_THREAD, nothing happens at the return path of the hard-IRQ handler except for a simple warning message being shown. Have a look at the__irq_wake_thread()function in the kernel sources for more information. Asthread_fncompetes for the CPU with other processes on the runqueue, it may be executed immediately or later in the future when the system has less load. This function should returnIRQ_HANDLEDwhen it has completed the interrupt handling process successfully. At this stage, the associated kthread will be taken off the runqueue and put in a blocked state until it’s woken up again by the hard-IRQ function.
A default hard-IRQ handler will be installed by the kernel if handler is NULL and thread_fn != NULL. This is the default primary handler. It is an almost empty handler that simply returns IRQ_WAKE_THREAD in order to wake up the associated kernel thread that will execute the thread_fn handler. This makes it possible to move the execution of interrupt handlers entirely to the process context, thus preventing buggy drivers (buggy IRQ handlers) from breaking the whole system and reducing interrupt latency. A dedicated handler’s kthreads will be visible in ps ax:
/*
* Default primary interrupt handler for threaded interrupts is * assigned as primary handler when request_threaded_irq is * called with handler == NULL. Useful for one-shot interrupts.
*/
static irqreturn_t irq_default_primary_handler(int irq, void *dev_id)
{
return IRQ_WAKE_THREAD;
}
int
request_threaded_irq(unsigned int irq,
irq_handler_t handler,
irq_handler_t thread_fn,
unsigned long irqflags,
const char *devname,
void *dev_id)
{
[...]
if (!handler) {
if (!thread_fn)
return -EINVAL;
handler = irq_default_primary_handler;
}
[...]
}
EXPORT_SYMBOL(request_threaded_irq);
Important note
Nowadays, request_irq() is just a wrapper around request_threaded_irq(), with the thread_fn parameter set to NULL.
Note that the interrupt is acknowledged at the interrupt controller level when you return from the hard-IRQ handler (whatever the return value is), thus allowing you to take other interrupts into account. In such a situation, if the interrupt hasn’t been acknowledged at the device level, the interrupt will fire again and again, resulting in stack overflows (or being stuck in the hard-IRQ handler forever) for level-triggered interrupts since the issuing device still has the interrupt line asserted. Before threaded IRQs were a thing, when you needed to run the bottom-half in a thread, you would instruct the top half to disable the IRQ at the device level, prior to waking the thread up. This way, even if the controller is ready to accept another interrupt, it is not raised again by the device.
The IRQF_ONESHOT flag resolves this problem. It must be set when it comes to use a threaded interrupt (at the request_threaded_irq() call); otherwise, the request will fail with the following error:
pr_err( “Threaded irq requested with handler=NULL and !ONESHOT for irq %d\n”, irq);
For more information on this, please have a look at the __setup_irq() function in the kernel source tree.
The following is an excerpt from the message that introduced the IRQF_ONESHOT flag and explains what it does (the entire message can be found at http://lkml.iu.edu/hypermail/linux/kernel/0908.1/02114.html):
Important note
If you omit the IRQF_ONESHOT flag, you’ll have to provide a hard-IRQ handler (in which you should disable the interrupt line); otherwise, the request will fail.
An example of a thread-only IRQ is as follows:
static irqreturn_t data_event_handler(int irq, void *dev_id)
{
struct big_structure *bs = dev_id;
process_data(bs->buffer);
return IRQ_HANDLED;
}
static int my_probe(struct i2c_client *client,
const struct i2c_device_id *id)
{
[...]
if (client->irq > 0) {
ret = request_threaded_irq(client->irq,
NULL,
&data_event_handler,
IRQF_TRIGGER_LOW | IRQF_ONESHOT,
id->name,
private);
if (ret)
goto error_irq;
}
[...]
return 0;
error_irq:
do_cleanup();
return ret;
}
In the preceding example, our device sits on an I2C bus. Thus, accessing the available data may cause it to sleep, so this should not be performed in the hard-IRQ handler. This is why our handler parameter is NULL.
Tip
If the IRQ line where you need threaded ISR handling to be shared among several devices (for example, some SoCs share the same interrupt among their internal ADCs and the touchscreen module), you must implement the hard-IRQ handler, which should check whether the interrupt has been raised by your device or not. If the interrupt does come from your device, you should disable the interrupt at the device level and return IRQ_WAKE_THREAD to wake the threaded handler. The interrupt should be enabled back at the device level in the return path of the threaded handler. If the interrupt does not come from your device, you should return IRQ_NONE directly from the hard-IRQ handler.
Moreover, if one driver has set either the IRQF_SHARED or IRQF_ONESHOT flag on the line, every other driver sharing the line must set the same flags. The /proc/interrupts file lists the IRQs and their processing per CPU, the IRQ name that was given during the requesting step, and a comma-separated list of drivers that registered an ISR for that interrupt.
Threaded IRQs are the best choice for interrupt processing as they can hog too many CPU cycles (exceeding a jiffy in most cases), such as bulk data processing. Threading IRQs allow the priority and CPU affinity of their associated thread to be managed individually. Since this concept comes from the real-time kernel tree (from Thomas Gleixner), it fulfills many requirements of a real-time system, such as allowing a fine-grained priority model to be used and reducing interrupt latency in the kernel.
Take a look at /proc/irq/IRQ_NUMBER/smp_affinity, which can be used to get or set the corresponding IRQ_NUMBER affinity. This file returns and accepts a bitmask that represents which processors can handle ISRs that have been registered for this IRQ. This way, you can, for example, decide to set the affinity of a hard-IRQ to one CPU while setting the affinity of the threaded handler to another CPU.
Requesting a context IRQ
A driver requesting an IRQ must know the nature of the interrupt in advance and decide whether its handler can run in the hard-IRQ context in order to call request_irq() or request_threaded_irq() accordingly.
There is a problem when it comes to request IRQ lines provided by discrete and non-MMIO-based interrupt controllers, such as I2C/SPI gpio-expanders. Since accessing those buses may cause them to sleep, it would be a disaster to run the handler of such slow controllers in a hard-IRQ context. Since the driver does not contain any information about the nature of the interrupt line/controller, the IRQ core provides the request_any_context_irq() API. This function determines whether the interrupt controller/line can sleep and calls the appropriate requesting function:
int request_any_context_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev_id)
request_any_context_irq() and request_irq() have the same interface but different semantics. Depending on the underlying context (the hardware platform), request_any_context_irq() selects either a hardIRQ handling method using request_irq() or a threaded handling method using request_threaded_irq(). It returns a negative error value on failure, while on success, it returns either IRQC_IS_HARDIRQ (meaning hardI-RQ handling is used) or IRQC_IS_NESTED (meaning the threaded version is used). With this function, the behavior of the interrupt handler is decided at runtime. For more information, take a look at the comment introducing it in the kernel by following this link: https://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git/commit/?id=ae731f8d0785.
The advantage of using request_any_context_irq() is that you don’t need to care about what can be done in the IRQ handler. This is because the context in which the handler will run depends on the interrupt controller that provides the IRQ line. For example, for a gpio-IRQ-based device driver, if the gpio belongs to a controller that seats on an I2C or SPI bus (in which case gpio access may sleep), the handler will be threaded. Otherwise (the gpio access may not sleep and is memory mapped as it belongs to the SoC), the handler will run in the hardIRQ context.
In the following example, the device expects an IRQ line mapped to a gpio. The driver cannot assume that the given gpio line will be memory mapped since it’s coming from the SoC. It may come from a discrete I2C or SPI gpio controller as well. A good practice would be to use request_any_context_irq() here:
static irqreturn_t packt_btn_interrupt(int irq, void *dev_id)
{
struct btn_data *priv = dev_id;
input_report_key(priv->i_dev,
BTN_0,
gpiod_get_value(priv->btn_gpiod) & 1);
input_sync(priv->i_dev);
return IRQ_HANDLED;
}
static int btn_probe(struct platform_device *pdev)
{
struct gpio_desc *gpiod;
int ret, irq;
gpiod = gpiod_get(&pdev->dev, “button”, GPIOD_IN);
if (IS_ERR(gpiod))
return -ENODEV;
priv->irq = gpiod_to_irq(priv->btn_gpiod);
priv->btn_gpiod = gpiod;
[...]
ret = request_any_context_irq(
priv->irq,
packt_btn_interrupt,
(IRQF_TRIGGER_FALLING | IRQF_TRIGGER_RISING),
“packt-input-button”,
priv);
if (ret < 0)
goto err_btn;
return 0;
err_btn:
do_cleanup();
return ret;
}
The preceding code is simple enough but is quite safe thanks to request_any_context_irq(), which prevents us from mistaking the type of the underlying gpio.
Using a workqueue to defer a bottom-half
Since we have already discussed the workqueue API, we will provide an example of how to use it here. This example is not error-free and has not been tested. It is just a demonstration that highlights the concept of bottom-half deferring by means of a workqueue.
Let’s start by defining the data structure that will hold the elements we need for further development:
struct private_struct {
int counter;
struct work_struct my_work;
void __iomem *reg_base;
spinlock_t lock;
int irq;
/* Other fields */
[...]
};
In the preceding data structure, our work structure is represented by the my_work element. We aren’t using the pointer here because we will need to use the container_of() macro to grab a pointer to the initial data structure. Next, we can define the method that will be invoked in the worker thread:
static void work_handler(struct work_struct *work)
{
int i;
unsigned long flags;
struct private_data *my_data =
container_of(work, struct private_data, my_work);
/*
* let’s proccessing at least half of MIN_REQUIRED_FIFO_SIZE
* prior to re-enabling the irq at device level, and so that
* buffer further data
*/
for (i = 0, i < MIN_REQUIRED_FIFO_SIZE, i++) {
device_pop_and_process_data_buffer();
if (i == MIN_REQUIRED_FIFO_SIZE / 2)
enable_irq_at_device_level();
}
spin_lock_irqsave(&my_data->lock, flags);
my_data->buf_counter -= MIN_REQUIRED_FIFO_SIZE;
spin_unlock_irqrestore(&my_data->lock, flags);
}
In the preceding code, we start data processing when enough data has been buffered. Now, we can provide our IRQ handler, which is responsible for scheduling our work, as follows:
/* This is our hard-IRQ handler.*/
static irqreturn_t my_interrupt_handler(int irq, void *dev_id)
{
u32 status;
unsigned long flags;
struct private_struct *my_data = dev_id;
/* Let’s read the status register in order to determine how
* and what to do
*/
status = readl(my_data->reg_base + REG_STATUS_OFFSET);
/*
* Let’s ack this irq at device level. Even if it raises * another irq, we are safe since this irq remain disabled * at controller level while we are in this handler
*/
writel(my_data->reg_base + REG_STATUS_OFFSET,
status | MASK_IRQ_ACK);
/*
* Protecting the shared resource, since the worker also * accesses this counter
*/
spin_lock_irqsave(&my_data->lock, flags);
my_data->buf_counter++;
spin_unlock_irqrestore(&my_data->lock, flags);
/*
* Ok. Our device raised an interrupt in order to inform it * has some new data in its fifo. But is it enough for us * to be processed
*/
if (my_data->buf_counter != MIN_REQUIRED_FIFO_SIZE)) {
/* ack and re-enable this irq at controller level */
return IRQ_HANDLED;
} else {
/*
* Right. prior to schedule the worker and returning * from this handler, we need to disable the irq at * device level
*/
writel(my_data->reg_base + REG_STATUS_OFFSET,
MASK_IRQ_DISABLE);
schedule_work(&my_work);
}
/* This will re-enable the irq at controller level */
return IRQ_HANDLED;
};
The comments in the IRQ handler code are meaningful enough. schedule_work() is the function that schedules our work. Finally, we can write our probe method, which will request our IRQ and register the previous handler:
static int foo_probe(struct platform_device *pdev)
{
struct resource *mem;
struct private_struct *my_data;
my_data = alloc_some_memory(sizeof(struct private_struct));
mem = platform_get_resource(pdev, IORESOURCE_MEM, 0);
my_data->reg_base =
ioremap(ioremap(mem->start, resource_size(mem));
if (IS_ERR(my_data->reg_base))
return PTR_ERR(my_data->reg_base);
/*
* work queue initialization. “work_handler” is the * callback that will be executed when our work is * scheduled.
*/
INIT_WORK(&my_data->my_work, work_handler);
spin_lock_init(&my_data->lock);
my_data->irq = platform_get_irq(pdev, 0);
if (request_irq(my_data->irq, my_interrupt_handler,
0, pdev->name, my_data))
handler_this_error()
return 0;
}
The structure of the preceding probe method shows without a doubt that we are facing a platform device driver. Generic IRQ and workqueue APIs have been used here to initialize our workqueue and register our handler.
Locking from within an interrupt handler
If a resource is shared between two or more use contexts (kthread, work, threaded IRQ, and so on) and only with a threaded bottom-half (that is, they’re never accessed by the hard-IRQ), then mutex locking is the way to go, as shown in the following example:
static int my_probe(struct platform_device *pdev)
{
int irq;
int ret;
irq = platform_get_irq(pdev, i);
ret = devm_request_threaded_irq(dev, irq, NULL, my_threaded_irq,
IRQF_ONESHOT, dev_ name(dev),
my_data);
[...]
return ret;
}
static irqreturn_t my_threaded_irq(int irq, void *dev_id)
{
struct priv_struct *my_data = dev_id;
/* Save FIFO Underrun & Transfer Error status */
mutex_lock(&my_data->fifo_lock);
/* accessing the device’s buffer through i2c */
[...]
mutex_unlock(&ldev->fifo_lock);
return IRQ_HANDLED;
}
In the preceding code, both the user task (kthread, work, and so on) and the threaded bottom half must hold the mutex before accessing the resource.
The preceding case is the simplest one to exemplify. The following are some rules that will help you lock between hard-IRQ contexts and others:
- If a resource is shared between a user context and a hard interrupt handler, you will want to use the spinlock variant, which disables interrupts; that is, the simple
_irqor_irqsave/_irq_restorevariants. This ensures that the user context is never preempted by this IRQ when it’s accessing the resource. This can be seen in the following example:static int my_probe(struct platform_device *pdev) { int irq; int ret; [...] irq = platform_get_irq(pdev, 0); if (irq < 0) goto handle_get_irq_error; ret = devm_request_threaded_irq(&pdev->dev, irq, my_hardirq, my_threaded_irq, IRQF_ONESHOT, dev_name(dev), my_data); if (ret < 0) goto err_cleanup_irq; [...] return 0; } static irqreturn_t my_hardirq(int irq, void *dev_id) { struct priv_struct *my_data = dev_id; unsigned long flags; /* No need to protect the shared resource */ my_data->status = __raw_readl( my_data->mmio_base + my_data->foo.reg_offset); /* Let us schedule the bottom-half */ return IRQ_WAKE_THREAD; } static irqreturn_t my_threaded_irq(int irq, void *dev_id) { struct priv_struct *my_data = dev_id; spin_lock_irqsave(&my_data->lock, flags); /* Processing the status status */ process_status(my_data->status); spin_unlock_irqrestore(&my_data->lock, flags); [...] return IRQ_HANDLED; }In the preceding code, the hard-IRQ handler doesn’t need to hold the spinlock as it can never be preempted. Only the user context must be held. There is a case where protection may not be necessary between the hard-IRQ and its threaded counterpart; that is, when the
IRQF_ONESHOTflag is set while requesting the IRQ line. This flag keeps the interrupt disabled after the hard-IRQ handler has finished. With this flag set, the IRQ line remains disabled until the threaded handler has been run until its completion. This way, the hard-IRQ handler and its threaded counterpart will never compete and a lock for a resource shared between the two might not be necessary. - When the resource is shared between user context and softIRQ, there are two things you need to guard against: the fact the user context can be interrupted by the softIRQ (remember, softIRQs run on the return path of hard-IRQ handlers) and the fact that the critical region can be entered from another CPU (remember, the same softIRQ may run concurrently on another CPU). In this case, you should use spinlock API variants that will disable softIRQs; that is,
spin_lock_bh()andspin_unlock_bh(). The_bhprefix means the bottom half. Because those APIs have not been discussed in detail in this chapter, you can use the_irqor even_irqsavevariants, which disable hardware interrupts as well. - The same applies to tasklets (because tasklets are built on top of softIRQs), with the only difference that a tasklet never runs concurrently (it never runs on more than one CPU at once); a tasklet is exclusive by design.
- There are two things to guard against when it comes to locking between hard IRQ and softIRQ: the softIRQ can be interrupted by the hard-IRQ and the critical region can be entered (
1for either by another hard-IRQ if designed in this way,2by the same softIRQ, or3by another softIRQ) from another CPU. Because the softIRQ can never run when the hard-IRQ handler is running, hard-IRQ handlers only need to use thespin_lock()andspin_unlock()APIs, which prevent concurrent access by other hard handlers on another CPU. However, softIRQ needs to use the locking API that actually disables interrupts – that is, the_irq()orirqsave()variants – with a preference for the latter. - Because softIRQs may run concurrently, locking may be necessary between two different softIRQs, or even between a softIRQ and itself (running on another CPU). In this case,
spinlock()/spin_unlock()should be used. There’s no need to disable hardware interrupts.
At this point, we are done looking at interrupt locking, which means we have come to the end of this chapter.





