























































How YARN satisfies big data needs
We talked about the MapReduce v1 framework and some limitations of the framework. Let's now discuss how YARN solves these issues:

- Scalability and higher cluster utilization: Scalability is the ability of a software or product to implement well under an expanding workload. In YARN, the responsibility of resource management and job scheduling / monitoring is divided into separate daemons, allowing YARN daemons to scale the cluster without degrading the performance of the cluster.
With a flexible and generic resource model in YARN, the scheduler handles an overall resource profile for each type of application. This structure makes the communication and storage of resource requests efficient for the scheduler resulting in higher cluster utilization.
- High availability for components: Fault tolerance is a core design principle for any multitenancy platform such as YARN. This responsibility is delegated to ResourceManager and ApplicationMaster. The application specific framework, ApplicationMaster, handles the failure of a container. The ResourceManager handles the failure of NodeManager and ApplicationMaster.
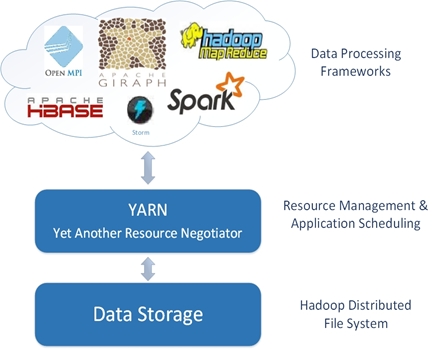
- Flexible resource model: In MapReduce v1, resources are defined as the number of map and reduce task slots available for the execution of a job. Every resource request cannot be mapped as map/reduce slots. In YARN, a resource-request is defined in terms of memory, CPU, locality, and so on. It results in a generic definition for a resource request by an application. The NodeManager node is the worker node and its capability is calculated based on the installed memory and cores of the CPU.
- Multiple data processing algorithms: The MapReduce framework is bounded to batch processing only. YARN is developed with a need to perform a wide variety of data processing over the data stored over Hadoop HDFS. YARN is a framework for generic resource management and allows users to execute multiple data processing algorithms over the data.
- Log aggregation and resource localization: As discussed earlier, accessing and managing user logs is difficult in the Hadoop 1.x framework. To manage user logs, YARN introduced a concept of log aggregation. In YARN, once the application is finished, the NodeManager service aggregates the user logs related to an application and these aggregated logs are written out to a single log file in HDFS. To access the logs, users can use either the YARN command-line options, YARN web interface, or can fetch directly from HDFS.
A container might require external resources such as jars, files, or scripts on a local file system. These are made available to containers before they are started. An ApplicationMaster defines a list of resources that are required to run the containers. For efficient disk utilization and access security, the NodeManager ensures the availability of specified resources and their deletion after use.









