






















































Before diving into crawling a website, we should develop an understanding about the scale and structure of our target website. The website itself can help us via the robots.txt and Sitemap files, and there are also external tools available to provide further details such as Google Search and WHOIS.
Background research
Checking robots.txt
Most websites define a robots.txt file to let crawlers know of any restrictions when crawling their website. These restrictions are just a suggestion but good web citizens will follow them. The robots.txt file is a valuable resource to check before crawling to minimize the chance of being blocked, and to discover clues about the website's structure. More information about the robots.txt protocol is available at http://www.robotstxt.org. The following code is the content of our example robots.txt, which is available at http://example.webscraping.com/robots.txt:
# section 1
User-agent: BadCrawler
Disallow: /
# section 2
User-agent: *
Crawl-delay: 5
Disallow: /trap
# section 3
Sitemap: http://example.webscraping.com/sitemap.xml
In section 1, the robots.txt file asks a crawler with user agent BadCrawler not to crawl their website, but this is unlikely to help because a malicious crawler would not respect robots.txt anyway. A later example in this chapter will show you how to make your crawler follow robots.txt automatically.
Section 2 specifies a crawl delay of 5 seconds between download requests for all user-agents, which should be respected to avoid overloading their server(s). There is also a /trap link to try to block malicious crawlers who follow disallowed links. If you visit this link, the server will block your IP for one minute! A real website would block your IP for much longer, perhaps permanently, but then we could not continue with this example.
Section 3 defines a Sitemap file, which will be examined in the next section.
Examining the Sitemap
Sitemap files are provided bywebsites to help crawlers locate their updated content without needing to crawl every web page. For further details, the sitemap standard is defined at http://www.sitemaps.org/protocol.html. Many web publishing platforms have the ability to generate a sitemap automatically. Here is the content of the Sitemap file located in the listed robots.txt file:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url><loc>http://example.webscraping.com/view/Afghanistan-1</loc></url>
<url><loc>http://example.webscraping.com/view/Aland-Islands-2</loc></url>
<url><loc>http://example.webscraping.com/view/Albania-3</loc></url>
...
</urlset>
This sitemap provides links to all the web pages, which will be used in the next section to build our first crawler. Sitemap files provide an efficient way to crawl a website, but need to be treated carefully because they can be missing, out-of-date, or incomplete.
Estimating the size of a website
The size of the target website will affect how we crawl it. If the website is just a few hundred URLs, such as our example website, efficiency is not important. However, if the website has over a million web pages, downloading each sequentially would take months. This problem is addressed later in Chapter 4 , Concurrent Downloading, on distributed downloading.
A quick way to estimate the size of a website is to check the results of Google's crawler, which has quite likely already crawled the website we are interested in. We can access this information through a Google search with the site keyword to filter the results to our domain. An interface to this and other advanced search parameters are available at http://www.google.com/advanced_search.
Here are the site search results for our example website when searching Google for site:example.webscraping.com:
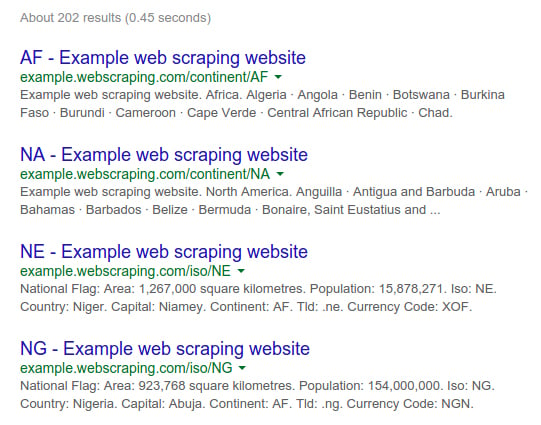
As we can see, Google currently estimates more than 200 web pages (this result may vary), which is around the website size. For larger websites, Google's estimates may be less accurate.
We can filter these results to certain parts of the website by adding a URL path to the domain. Here are the results for site:example.webscraping.com/view, which restricts the site search to the country web pages:
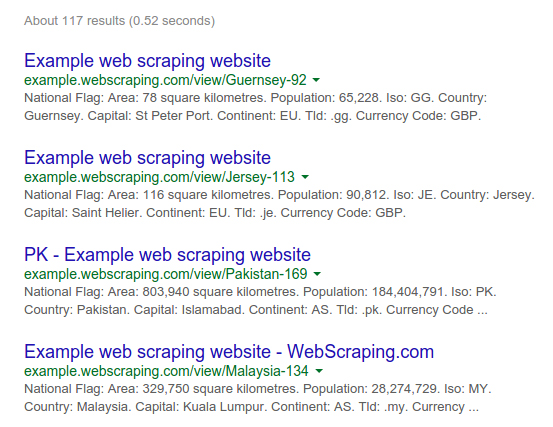
Again, your results may vary in size; however, this additional filter is useful because ideally you only want to crawl the part of a website containing useful data rather than every page.
Identifying the technology used by a website
The type of technology used to build a websitewill affect how we crawl it. A useful tool to check the kind of technologies a website is built with is the module detectem, which requires Python 3.5+ and Docker. If you don't already have Docker installed, follow the instructions for your operating system at https://www.docker.com/products/overview. Once Docker is installed, you can run the following commands.
docker pull scrapinghub/splash
pip install detectem
This will pull the latest Docker image from ScrapingHub and install the package via pip. It is recommended to use a Python virtual environment (https://docs.python.org/3/library/venv.html) or a Conda environment (https://conda.io/docs/using/envs.html) and to check the project's ReadMe page (https://github.com/spectresearch/detectem) for any updates or changes.
Why use environments?
Imagine if your project was developed with an earlier version of a library such as detectem, and then, in a later version, detectem introduced some backwards-incompatible changes that break your project. However, different projects you are working on would like to use the newer version. If your project uses the system-installed detectem, it is eventually going to break when libraries are updated to support other projects.
Ian Bicking's virtualenv provides a clever hack to this problem by copying the system Python executable and its dependencies into a local directory to create an isolated Python environment. This allows a project to install specific versions of Python libraries locally and independently of the wider system. You can even utilize different versions of Python in different virtual environments. Further details are available in the documentation at https://virtualenv.pypa.io. Conda environments offer similar functionality using the Anaconda Python path.
Imagine if your project was developed with an earlier version of a library such as detectem, and then, in a later version, detectem introduced some backwards-incompatible changes that break your project. However, different projects you are working on would like to use the newer version. If your project uses the system-installed detectem, it is eventually going to break when libraries are updated to support other projects.
Ian Bicking's virtualenv provides a clever hack to this problem by copying the system Python executable and its dependencies into a local directory to create an isolated Python environment. This allows a project to install specific versions of Python libraries locally and independently of the wider system. You can even utilize different versions of Python in different virtual environments. Further details are available in the documentation at https://virtualenv.pypa.io. Conda environments offer similar functionality using the Anaconda Python path.
The detectem module uses a series of requests and responses to detect technologies used by the website, based on a series of extensible modules. It uses Splash (https://github.com/scrapinghub/splash), a scriptable browser developed by ScrapingHub (https://scrapinghub.com/). To run the module, simply use the det command:
$ det http://example.webscraping.com
[('jquery', '1.11.0')]
We can see the example website uses a common JavaScript library, so its content is likely embedded in the HTML and should be relatively straightforward to scrape.
Detectem is still fairly young and aims to eventually have Python parity to Wappalyzer (https://github.com/AliasIO/Wappalyzer), a Node.js-based project supporting parsing of many different backends as well as ad networks, JavaScript libraries, and server setups. You can also run Wappalyzer via Docker. To first download the Docker image, run:
$ docker pull wappalyzer/cli
Then, you can run the script from the Docker instance:
$ docker run wappalyzer/cli http://example.webscraping.com
The output is a bit hard to read, but if we copy and paste it into a JSON linter, we can see the many different libraries and technologies detected:
{'applications':
[{'categories': ['Javascript Frameworks'],
'confidence': '100',
'icon': 'Modernizr.png',
'name': 'Modernizr',
'version': ''},
{'categories': ['Web Servers'],
'confidence': '100',
'icon': 'Nginx.svg',
'name': 'Nginx',
'version': ''},
{'categories': ['Web Frameworks'],
'confidence': '100',
'icon': 'Twitter Bootstrap.png',
'name': 'Twitter Bootstrap',
'version': ''},
{'categories': ['Web Frameworks'],
'confidence': '100',
'icon': 'Web2py.png',
'name': 'Web2py',
'version': ''},
{'categories': ['Javascript Frameworks'],
'confidence': '100',
'icon': 'jQuery.svg',
'name': 'jQuery',
'version': ''},
{'categories': ['Javascript Frameworks'],
'confidence': '100',
'icon': 'jQuery UI.svg',
'name': 'jQuery UI',
'version': '1.10.3'},
{'categories': ['Programming Languages'],
'confidence': '100',
'icon': 'Python.png',
'name': 'Python',
'version': ''}],
'originalUrl': 'http://example.webscraping.com',
'url': 'http://example.webscraping.com'}
Here, we can see that Python and the web2py frameworks were detected with very high confidence. We can also see that the frontend CSS framework Twitter Bootstrap is used. Wappalyzer also detected Modernizer.js and the use of Nginx as the backend server. Because the site is only using JQuery and Modernizer, it is unlikely the entire page is loaded by JavaScript. If the website was instead built with AngularJS or React, then its content would likely be loaded dynamically. Or, if the website used ASP.NET, it would be necessary to use sessions and form submissions to crawl web pages. Working with these more difficult cases will be covered later in Chapter 5, Dynamic Content and Chapter 6, Interacting with Forms.
Finding the owner of a website
For some websites it may matter to us who the owner is. For example, if the owner is known to block web crawlers then it would be wise to be more conservative in our download rate. To find who owns a website we can use the WHOIS protocol to see who is the registered owner of the domain name. A Python wrapper to this protocol, documented at https://pypi.python.org/pypi/python-whois, can be installed via pip:
pip install python-whois
Here is the most informative part of the WHOIS response when querying the appspot.com domain with this module:
>>> import whois
>>> print(whois.whois('appspot.com'))
{
...
"name_servers": [
"NS1.GOOGLE.COM",
"NS2.GOOGLE.COM",
"NS3.GOOGLE.COM",
"NS4.GOOGLE.COM",
"ns4.google.com",
"ns2.google.com",
"ns1.google.com",
"ns3.google.com"
],
"org": "Google Inc.",
"emails": [
"abusecomplaints@markmonitor.com",
"dns-admin@google.com"
]
}
We can see here that this domain is owned by Google, which is correct; this domain is for the Google App Engine service. Google often blocks web crawlers despite being fundamentally a web crawling business themselves. We would need to be careful when crawling this domain because Google often blocks IPs that quickly scrape their services; and you, or someone you live or work with, might need to use Google services. I have experienced being asked to enter captchas to use Google services for short periods, even after running only simple search crawlers on Google domains.





