























































K-NN is another classical method of clustering. It builds groups of samples, supposing that each new sample will have the same class as its neighbors, without looking for a global representative central sample. Instead, it looks at the environment, looking for the most frequent class on each new sample's environment.
Nearest neighbors
Mechanics of K-NN
K-NN can be implemented in many configurations, but in this chapter we will use the semi-supervised approach, starting from a certain number of already assigned samples, and later guessing the cluster membership using the main criteria.
In the following diagram, we have a breakdown of the algorithm. It can be summarized with the following steps:
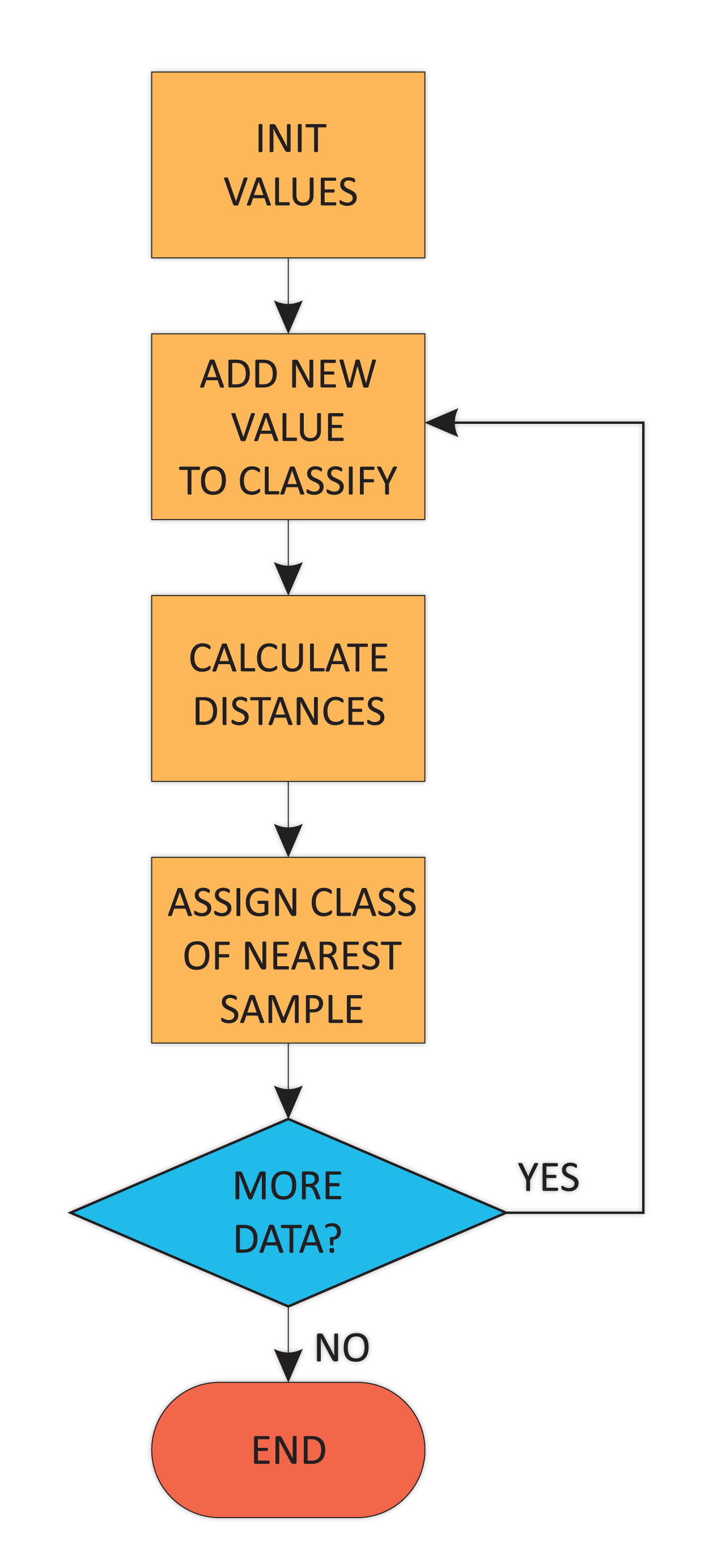
Flowchart for the K-NN...






















