






















































Linear support vector machines
Let's consider a dataset of feature vectors we want to classify:
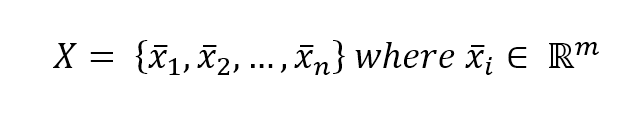
For simplicity, we assume it as a binary classification (in all the other cases, it's possible to use automatically the one-versus-all strategy) and we set our class labels as -1 and 1:

Our goal is to find the best separating hyperplane, for which the equation is:

In the following figure, there's a bidimensional representation of such a hyperplane:

In this way, our classifier can be written as:

In a realistic scenario, the two classes are normally separated by a margin with two boundaries where a few elements lie. Those elements are called support vectors. For a more generic mathematical expression, it's preferable to renormalize our dataset so that the support vectors will lie on two hyperplanes with equations:

In the following figure, there's an example with two support vectors. The dashed line is the original separating hyperplane:

Our goal is to maximize the distance between these two boundary hyperplanes...












