






















































Validating an algorithm confirms that it is actually providing a mathematical solution to the problem we are trying to solve. A validation process should check the results for as many possible values and types of input values as possible.
Validating an algorithm
Exact, approximate, and randomized algorithms
Validating an algorithm also depends on the type of the algorithm as the testing techniques are different. Let's first differentiate between deterministic and randomized algorithms.
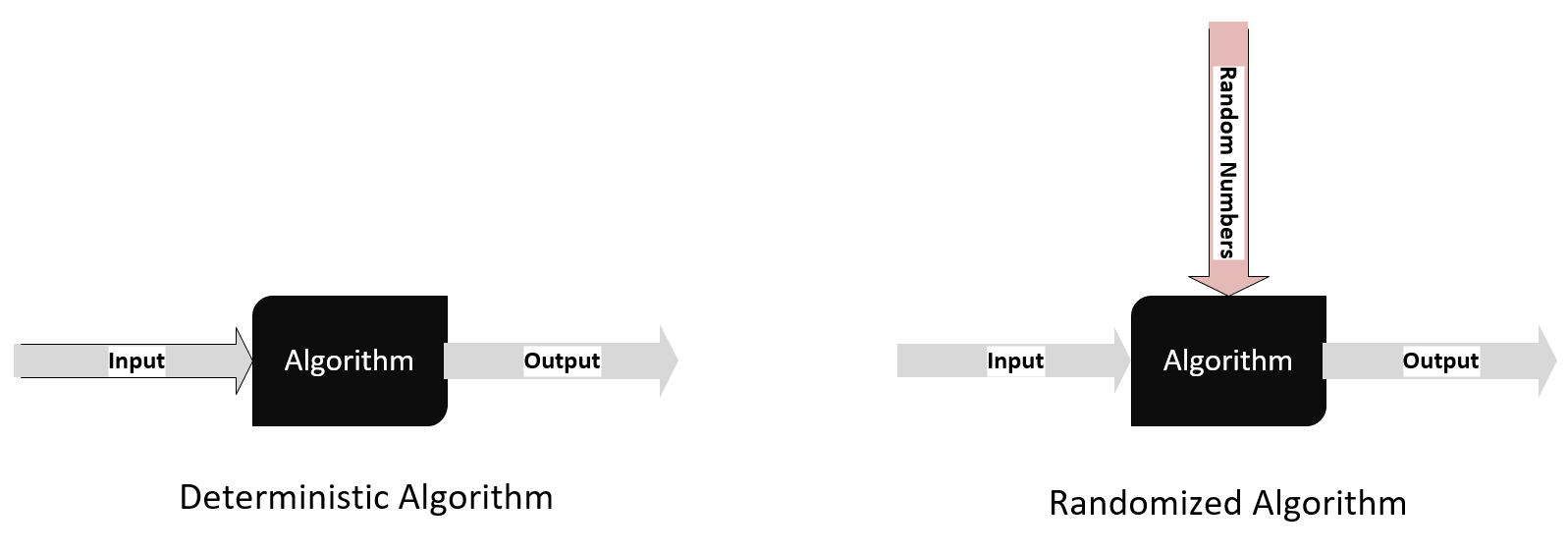
For deterministic algorithms, a particular input always generates exactly the same output. But for certain classes of algorithms, a sequence of random numbers is also taken as input, which makes the output different each time the algorithm is run. The k-means clustering algorithm, which is detailed in Chapter 6, Unsupervised Machine Learning Algorithms, is an example of such an algorithm:
Algorithms can also be divided into the following two types based on assumptions or approximation used to simplify the logic to make them run faster:
An exact algorithm: Exact algorithms are expected to produce a precise solution without introducing any assumptions or approximations.
An approximate algorithm: When the problem complexity is too much to handle for the given resources, we simplify our problem by making some assumptions. The algorithms based on these simplifications or assumptions are called approximate algorithms, which doesn't quite give us the precise solution.
Let's look at an example to understand the difference between the exact and approximate algorithms—the famous traveling salesman problem, which was presented in 1930. A traveling salesman challenges you to find the shortest route for a particular salesman that visits each city (from a list of cities) and then returns to the origin, which is why he is named the traveling salesman. The first attempt to provide the solution will include generating all the permutations of cities and choosing the combination of cities that is cheapest. The complexity of this approach to provide the solution is O(n!), where n is the number of cities. It is obvious that time complexity starts to become unmanageable beyond 30 cities.
If the number of cities is more than 30, one way of reducing the complexity is to introduce some approximations and assumptions.
For approximate algorithms, it is important to set the expectations for accuracy when gathering the requirements. Validating an approximation algorithm is about verifying that the error of the results is within an acceptable range.
Explainability
When algorithms are used for critical cases, it becomes important to have the ability to explain the reason behind each and every result whenever needed. This is necessary to make sure that decisions based on the results of the algorithms do not introduce bias.
The ability to exactly identify the features that are used directly or indirectly to come up with a particular decision is called the explainability of an algorithm. Algorithms, when used for critical use cases, need to be evaluated for bias and prejudice. The ethical analysis of algorithms has become a standard part of the validation process for those algorithms that can affect decision-making that relates to the life of people.
For algorithms that deal with deep learning, explainability is difficult to achieve. For example, if an algorithm is used to refuse the mortgage application of a person, it is important to have the transparency and ability to explain the reason.
Algorithmic explainability is an active area of research. One of the effective techniques that has been recently developed is Local Interpretable Model-Agnostic Explanations (LIME), as proposed in the proceedings of the 22nd Association for Computing Machinery (ACM) at the Special Interest Group on Knowledge Discovery (SIGKDD) international conference on knowledge discovery and data mining in 2016. LIME is based on a concept where small changes are induced to the input for each instance and then an effort to map the local decision boundary for that instance is made. It can then quantify the influence of each variable for that instance.




