






















































How to avoid data races using ring buffers
When a buffer needs to be updated every frame, we run the risk of creating a data race, as shown in Figure 2.5. A data race is a situation where multiple threads within a program concurrently access a shared data point, with at least one thread performing a write operation. This concurrent access can result in unforeseen behavior due to the unpredictable order of operations. Take the example of a uniform buffer that stores the view, model, and viewport matrices and needs to be updated every frame. The buffer is updated while the first command buffer is being recorded, initializing it (version 1). Once the command buffer starts processing on the GPU, the buffer contains the correct data:
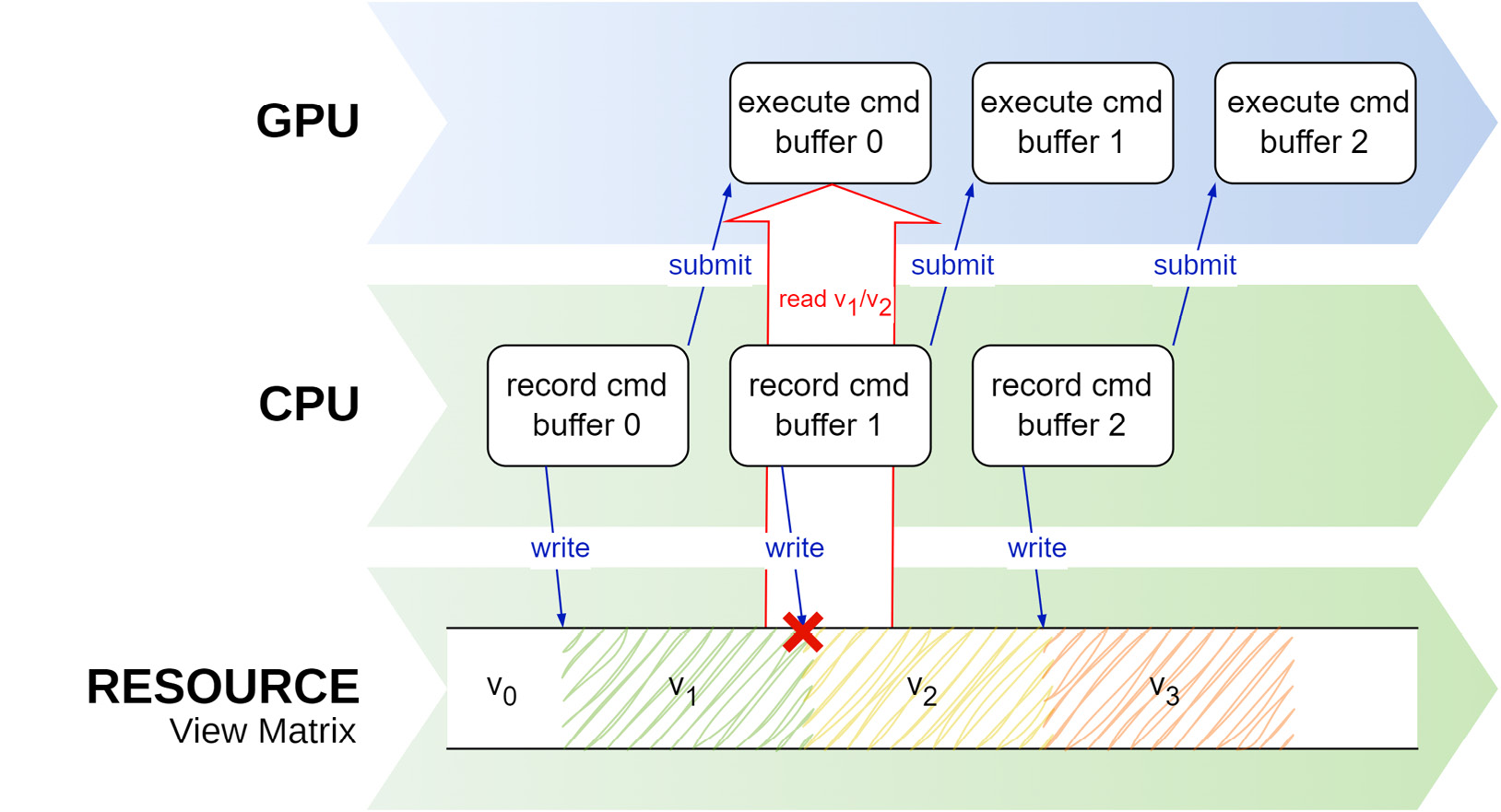
Figure 2.5 – Data race when using one buffer
After the first command buffer starts processing in the GPU, the application may try to update the buffer’s contents to version 2 while the GPU is accessing that data for rendering!
Getting ready
Synchronization is by far the hardest aspect of Vulkan. If synchronization elements such as semaphores, fences, and barriers are used too greedily, then your application becomes a series and won’t use the full power of the parallelism between the CPU and the GPU.
Make sure you also read the Understanding synchronization in the swapchain – fences and semaphores recipe in Chapter 1, Vulkan Core Concepts. That recipe and this one only scratch the surface of how to tackle synchronization, but are very good starting points.
A ring-buffer implementation is provided in the EngineCore::RingBuffer repository, which has a configurable number of sub-buffers. Its sub-buffers are all host-visible, persistent buffers; that is, they are persistently mapped after creation for ease of access.
How to do it…
There are a few ways to avoid this problem, but the easiest one is to create a ring buffer that contains several buffers (or any other resource) equal to the number of frames in flight. Figure 2.6 shows events when there are two buffers available. Once the first command buffer is submitted and is being processed in the GPU, the application is free to process copy 1 of the buffer, as it’s not being accessed by the device:
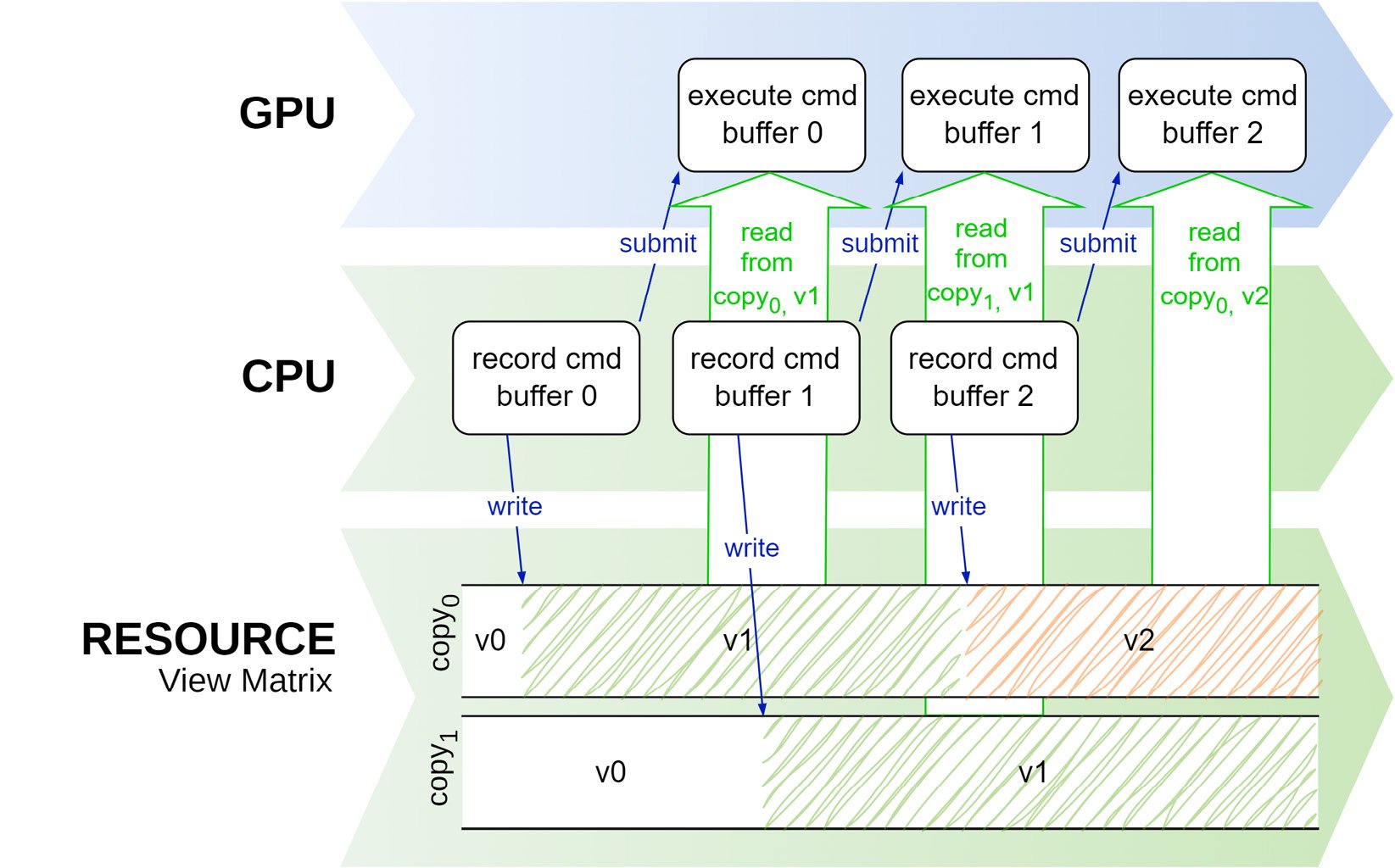
Figure 2.6 – A data race is avoided with multiple copies of a resource
Even though this is a simple solution, it has a caveat: if partial updates are allowed, care must be taken when the buffer is updated. Consider Figure 2.7, in which a ring buffer that contains three sub-allocations is partially updated. The buffer stores the view, model, and viewport matrices. During initialization, all three sub-allocations are initialized to three identity matrices. On Frame 0, while Buffer 0 is active, the model matrix is updated and now contains a translation of (10, 10, 0). On the next frame, Frame 1, Buffer 1 becomes active, and the viewport matrix is updated. Because Buffer 1 was initialized to three identity matrices, updating only the viewport matrix makes buffers 0 and 1 out of sync (as well as Buffer 3). To guarantee that partial updates work, we need to copy the last active buffer, Buffer 0, into Buffer 1 first, and then update the viewport matrix:
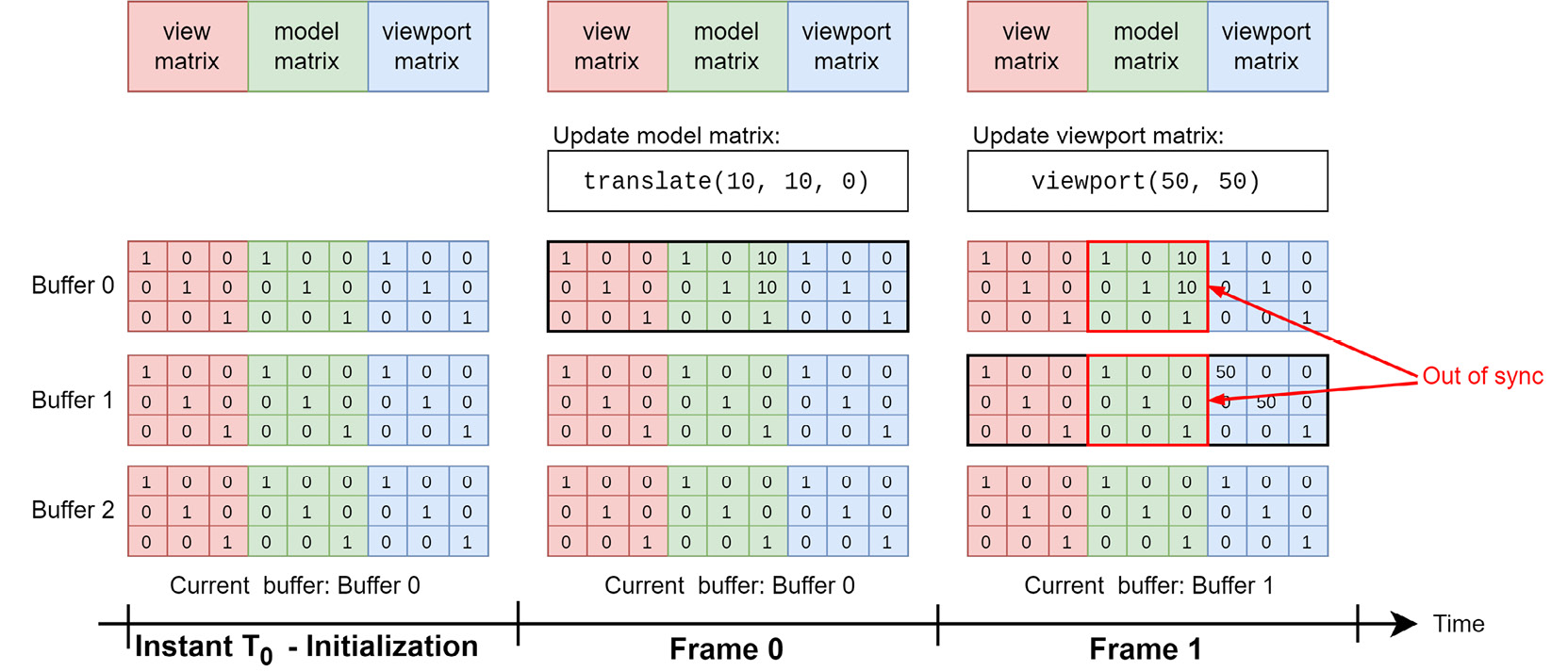
Figure 2.7 – Partial update of a ring buffer makes all sub-allocations out of sync if they are not replicated
Synchronization is a delicate topic, and guaranteeing your application behaves correctly with so many moving parts is tricky. Hopefully, a ring-buffer implementation that is simple may help you focus on other areas of the code.


