























































In the previous section, we were processing on raw text and looked at concepts at the sentence level. In this section, we are going to look at the concepts of tokenization, lemmatization, and so on at the word level.
Handling corpus-raw sentences
Word tokenization
Word tokenization is defined as the process of chopping a stream of text up into words, phrases, and meaningful strings. This process is called word tokenization. The output of the process are words that we will get as an output after tokenization. This is called a token.
Let's see the code snippet given in Figure 4.11 of tokenized words:
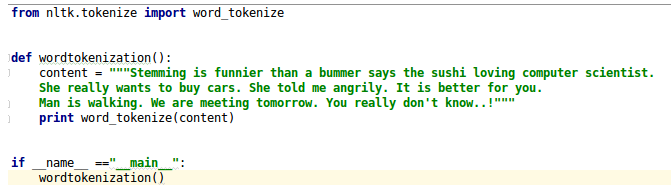
Figure 4.11: Word tokenized code snippet
The output of the code given in Figure 4.11 is as follows:
The input for word tokenization is:
Stemming is funnier than a bummer says the sushi loving computer scientist.She really wants to buy cars. She told me angrily. It is better for you.Man is walking. We are meeting tomorrow. You really don''t know..!
The output for word tokenization is:
[''Stemming'', ''is'', ''funnier'', ''than'', ''a'', ''bummer'', ''says'', ''the'', ''sushi'', ''loving'', ''computer'', ''scientist'', ''.'', ''She'', ''really'', ''wants'', ''to'', ''buy'', ''cars'', ''.'', ''She'', ''told'', ''me'', ''angrily'', ''.'', ''It'', ''is'', ''better'', ''for'', ''you'', ''.'', ''Man'', ''is'', ''walking'', ''.'', ''We'', ''are'', ''meeting'', ''tomorrow'', ''.'', ''You'', ''really'', ''do'', ""n''t"", ''know..'', ''!'']
Challenges for word tokenization
If you analyze the preceding output, then you can observe that the word don't is tokenized as do, n't know. Tokenizing these kinds of words is pretty painful using the word_tokenize of nltk.
To solve the preceding problem, you can write exception codes and improvise the accuracy. You need to write pattern matching rules, which solve the defined challenge, but are so customized and vary from application to application.
Another challenge involves some languages such as Urdu, Hebrew, Arabic, and so on. They are quite difficult in terms of deciding on the word boundary and find out meaningful tokens from the sentences.
Word lemmatization
Word lemmatization is the same concept that we defined in the first section. We will just do a quick revision of it and then we will implement lemmatization on the word level.
Word lemmatization is converting a word from its inflected form to its base form. In word lemmatization, we consider the POS tags and, according to the POS tags, we can derive the base form which is available to the lexical WordNet.
You can find the code snippet in Figure 4.12:
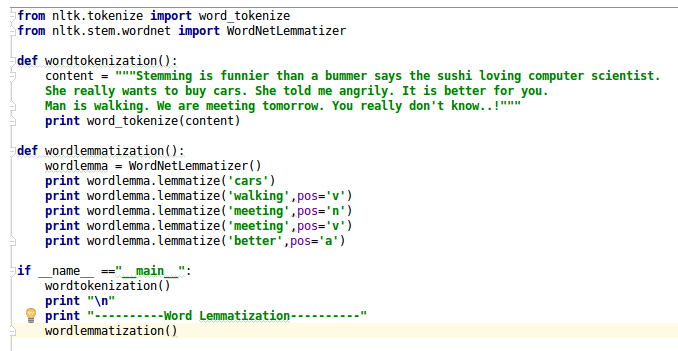
Figure 4.12: Word lemmatization code snippet
The output of the word lemmatization is as follows:
Input is: wordlemma.lemmatize(''cars'') Output is: car
Input is: wordlemma.lemmatize(''walking'',pos=''v'') Output is: walk
Input is: wordlemma.lemmatize(''meeting'',pos=''n'') Output is: meeting
Input is: wordlemma.lemmatize(''meeting'',pos=''v'') Output is: meet
Input is: wordlemma.lemmatize(''better'',pos=''a'') Output is: good
Challenges for word lemmatization
It is time consuming to build a lexical dictionary. If you want to build a lemmatization tool that can consider a larger context, taking into account the context of preceding sentences, it is still an open area in research.






















