






















































Fibers and green threads
Note!
This is an example of M:N threading. Many tasks can run concurrently on one OS thread. Fibers and green threads are often referred to as stackful coroutines.
The name “green threads” originally stems from an early implementation of an M:N threading model used in Java and has since been associated with different implementations of M:N threading. You will encounter different variations of this term, such as “green processes” (used in Erlang), which are different from the ones we discuss here. You’ll also see some that define green threads more broadly than we do here.
The way we define green threads in this book makes them synonymous with fibers, so both terms refer to the same thing going forward.
The implementation of fibers and green threads implies that there is a runtime with a scheduler that’s responsible for scheduling what task (M) gets time to run on the OS thread (N). There are many more tasks than there are OS threads, and such a system can run perfectly fine using only one OS thread. The latter case is often referred to as M:1 threading.
Goroutines is an example of a specific implementation of stackfull coroutines, but it comes with slight nuances. The term “coroutine” usually implies that they’re cooperative in nature, but Goroutines can be pre-empted by the scheduler (at least since version 1.14), thereby landing them in somewhat of a grey area using the categories we present here.
Green threads and fibers use the same mechanisms as an OS, setting up a stack for each task, saving the CPU’s state, and jumping from one task(thread) to another by doing a context switch.
We yield control to the scheduler (which is a central part of the runtime in such a system), which then continues running a different task.
The state of execution is stored in each stack, so in such a solution, there would be no need for async, await, Future, or Pin. In many ways, green threads mimic how an operating system facilitates concurrency, and implementing them is a great learning experience.
A runtime using fibers/green threads for concurrent tasks can have a high degree of flexibility. Tasks can, for example, be pre-empted and context switched at any time and at any point in their execution, so a long-running task that hogs the CPU could in theory be pre-empted by the runtime, acting as a safeguard from having tasks that end up blocking the whole system due to an edge-case or a programmer error.
This gives the runtime scheduler almost the same capabilities as the OS scheduler, which is one of the biggest advantages of systems using fibers/green threads.
The typical flow goes as follows:
- You run some non-blocking code
- You make a blocking call to some external resource
- The CPU jumps to the main thread, which schedules a different thread to run and jumps to that stack
- You run some non-blocking code on the new thread until a new blocking call or the task is finished
- The CPU jumps back to the main thread, schedules a new thread that is ready to make progress, and jumps to that thread
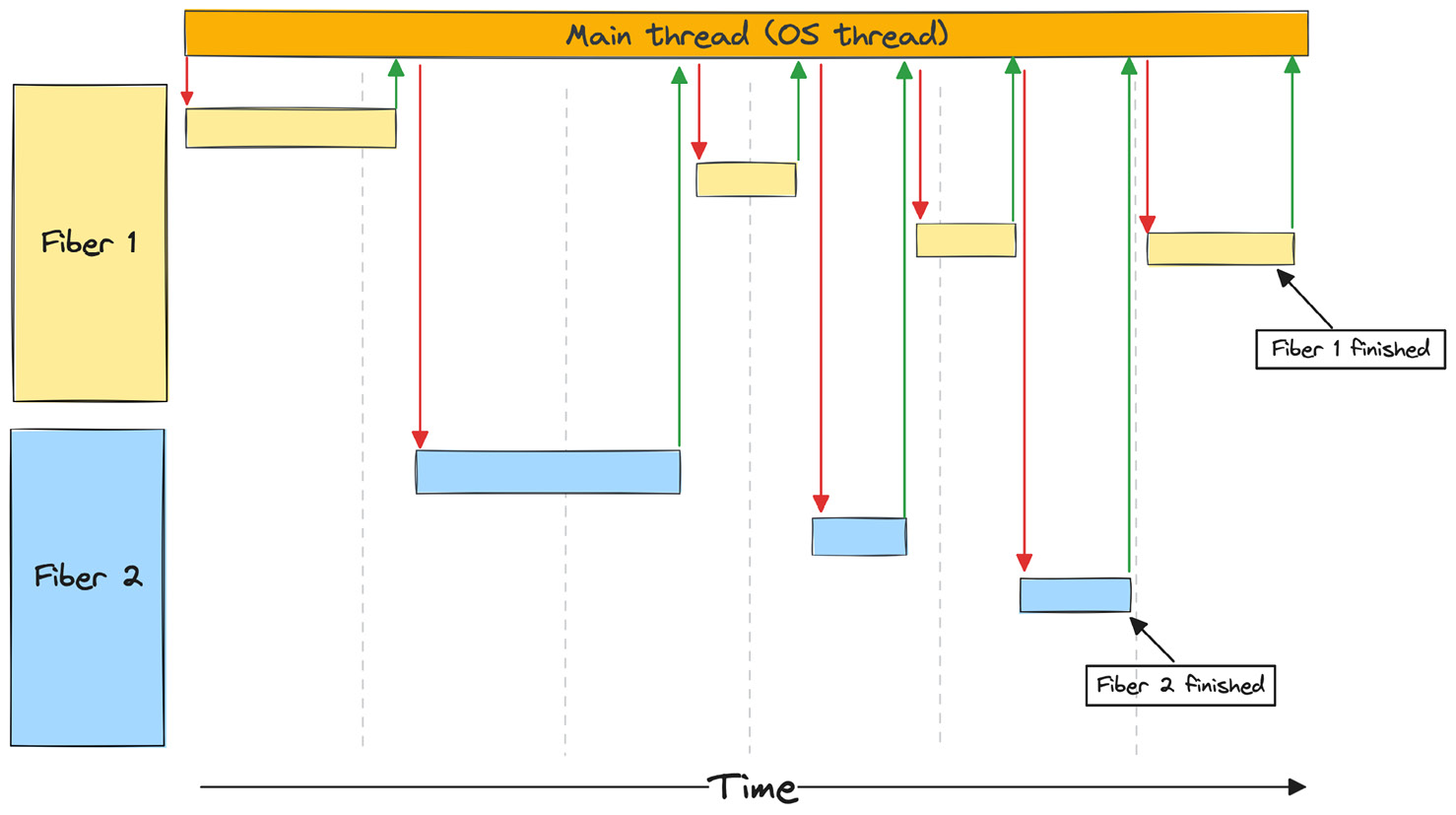
Figure 2.2 – Program flow using fibers/green threads
Each stack has a fixed space
As fibers and green threads are similar to OS threads, they do have some of the same drawbacks as well. Each task is set up with a stack of a fixed size, so you still have to reserve more space than you actually use. However, these stacks can be growable, meaning that once the stack is full, the runtime can grow the stack. While this sounds easy, it’s a rather complicated problem to solve.
We can’t simply grow a stack as we grow a tree. What actually needs to happen is one of two things:
- You allocate a new piece of continuous memory and handle the fact that your stack is spread over two disjointed memory segments
- You allocate a new larger stack (for example, twice the size of the previous stack), move all your data over to the new stack, and continue from there
The first solution sounds pretty simple, as you can leave the original stack as it is, and you can basically context switch over to the new stack when needed and continue from there. However, modern CPUs can work extremely fast if they can work on a contiguous piece of memory due to caching and their ability to predict what data your next instructions are going to work on. Spreading the stack over two disjointed pieces of memory will hinder performance. This is especially noticeable when you have a loop that happens to be just at the stack boundary, so you end up making up to two context switches for each iteration of the loop.
The second solution solves the problems with the first solution by having the stack as a contiguous piece of memory, but it comes with some problems as well.
First, you need to allocate a new stack and move all the data over to the new stack. But what happens with all pointers and references that point to something located on the stack when everything moves to a new location? You guessed it: every pointer and reference to anything located on the stack needs to be updated so they point to the new location. This is complex and time-consuming, but if your runtime already includes a garbage collector, you already have the overhead of keeping track of all your pointers and references anyway, so it might be less of a problem than it would for a non-garbage collected program. However, it does require a great deal of integration between the garbage collector and the runtime to do this every time the stack grows, so implementing this kind of runtime can get very complicated.
Secondly, you have to consider what happens if you have a lot of long-running tasks that only require a lot of stack space for a brief period of time (for example, if it involves a lot of recursion at the start of the task) but are mostly I/O bound the rest of the time. You end up growing your stack many times over only for one specific part of that task, and you have to make a decision whether you will accept that the task occupies more space than it needs or at some point move it back to a smaller stack. The impact this will have on your program will of course vary greatly based on the type of work you do, but it’s still something to be aware of.
Context switching
Even though these fibers/green threads are lightweight compared to OS threads, you still have to save and restore registers at every context switch. This likely won’t be a problem most of the time, but when compared to alternatives that don’t require context switching, it can be less efficient.
Context switching can also be pretty complex to get right, especially if you intend to support many different platforms.
Scheduling
When a fiber/green thread yields to the runtime scheduler, the scheduler can simply resume execution on a new task that’s ready to run. This means that you avoid the problem of being put in the same run queue as every other task in the system every time you yield to the scheduler. From the OS perspective, your threads are busy doing work all the time, so it will try to avoid pre-empting them if it can.
One unexpected downside of this is that most OS schedulers make sure all threads get some time to run by giving each OS thread a time slice where it can run before the OS pre-empts the thread and schedules a new thread on that CPU. A program using many OS threads might be allotted more time slices than a program with fewer OS threads. A program using M:N threading will most likely only use a few OS threads (one thread per CPU core seems to be the starting point on most systems). So, depending on whatever else is running on the system, your program might be allotted fewer time slices in total than it would be using many OS threads. However, with the number of cores available on most modern CPUs and the typical workload on concurrent systems, the impact from this should be minimal.
FFI
Since you create your own stacks that are supposed to grow/shrink under certain conditions and might have a scheduler that assumes it can pre-empt running tasks at any point, you will have to take extra measures when you use FFI. Most FFI functions will assume a normal OS-provided C-stack, so it will most likely be problematic to call an FFI function from a fiber/green thread. You need to notify the runtime scheduler, context switch to a different OS thread, and have some way of notifying the scheduler that you’re done and the fiber/green thread can continue. This naturally creates overhead and added complexity both for the runtime implementor and the user making the FFI call.
Advantages
- It is simple to use for the user. The code will look like it does when using OS threads.
- Context switching is reasonably fast.
- Abundant memory usage is less of a problem when compared to OS threads.
- You are in full control over how tasks are scheduled and if you want you can prioritize them as you see fit.
- It’s easy to incorporate pre-emption, which can be a powerful feature.
Drawbacks
- Stacks need a way to grow when they run out of space creating additional work and complexity
- You still need to save the CPU state on every context switch
- It’s complicated to implement correctly if you intend to support many platforms and/or CPU architectures
- FFI can have a lot of overhead and add unexpected complexity



