






















































Building a picture of ML
People anthropomorphize computers today, giving them human characteristics, such as the ability to think. At its lowest level, a computer processes commands to manipulate data, perform comparisons, and move data around. There is no thought process involved—just electrical energy cleverly manipulated to produce a mathematical result from a given input. So, the term “machine learning” is a bit of a misnomer because the machine is learning nothing and it doesn’t understand anything. A better way to view ML is as a process of algorithm manipulation such that added weighting produces a result that better matches the data input. Once someone trains a model (the combination of algorithm and weighting added to the algorithm), it’s possible to use the model to process data that the algorithm hasn’t seen in the past and still obtain a desirable result. The result is the simulation of human thought processes so that it appears that the application is thinking when it isn’t really thinking at all.
The feature that distinguishes ML most significantly is that the computer can perform mundane tasks fast and consistently. It can’t provide original thought. A human must create the required process but, once created, the machine can outperform the human because it doesn’t require rest and doesn’t get bored. Consequently, if the data is clean, the model correct, and the anticipated result correctly defined, a machine can outshine a human. However, it’s essential to consider everything that is required to obtain a desirable result before employing ML for a particular task, and this part of the process is often lacking today. People often think that machines are much more capable than they really are and then exhibit disappointment when the machine fails to work as expected.
Why is ML important?
Despite what you may have heard from various sources, ML is more important for mundane tasks than for something earth-shattering in its significance. ML won’t enable Terminators to take over the planet, nor will this technology suddenly make it possible for humans to stop working entirely in a utopian version of the future. What ML can do is reduce the boredom and frustration that humans feel when forced to perform repetitive factory work or other tasks of the sort. In the future, at the lowest level, humans will supervise machines performing mundane tasks and be there when things go wrong.
However, the ability to simply supervise machines is still somewhat far into the future, and letting them work unmonitored is further into the future still. There are success stories, of course, but then there are also failures of the worst sort. For example, trusting the AI in a car to drive by itself without human intervention can lead to all sorts of problems. Sleeping while driving will still garner a ticket and put others at risk, as described at https://www.theguardian.com/world/2020/sep/17/canada-tesla-driver-alberta-highway-speeding. In this case, the driver was sleeping peacefully with a passenger in the front seat of the car when the police stopped him. Fortunately, the car didn’t cause an accident in this case, but there are documented instances where self-driving cars did precisely that (see https://www.nytimes.com/2018/03/19/technology/uber-driverless-fatality.html for an example).
Besides performing tasks, ML can perform various kinds of analysis at a speed that humans can’t match, and with greater efficiency. A doctor can rely on ML to assist in finding cancer because the ML application can recognize patterns in an MRI that the doctor can’t even see. Consequently, the ML application can help guide the doctor in the right direction. However, the doctor must still make the final determination as to whether a group of cells really is cancerous, because the ML application lacks experience and the senses that a doctor has. Likewise, ML can make a doctor’s hands steadier during surgery, but the doctor must still perform the actual task. In summary, ML is currently assistive in nature, but it can produce reliable results in that role.
Pattern recognition is a strong reason to use ML. However, the ability to recognize patterns only works when the following applies:
- The source data is untainted
- The training and testing data are unbiased
- The correct algorithms are selected
- The model is created correctly
- Any goals are clearly defined and verified against the training and test data
Classification uses of ML rely on patterns to distinguish between types of objects or data. For example, a classification system can detect the difference between a car, a pedestrian, and a street sign (at least, a lot of the time). Unfortunately, the current state of the art clearly shows that ML has a long way to go in this regard because it’s easy to fool an application in many cases (see https://arxiv.org/pdf/1710.08864.pdf?ref=hackernoon.com for examples). There are a lot of articles now that demonstrate all of the ways in which an adversarial attack on a deep learning or ML application will render it nearly useless. So, ML works best in an environment where nothing unexpected happens, but in that environment, it works extremely well.
Recommender systems are another form of ML that try to predict something based on past data. For example, recommender systems play a huge role in online stores where they suggest some items to go with other items a person has purchased. If you’re fond of online buying, you know from experience that the recommender systems are wrong about the additional items more often than not. A recommender setup attached to a word processor for suggesting the next work you plan to type often does a better job over time. However, even in this case, you must exercise care because the recommendation is often not what you want (sometimes with hilarious results when the recipient receives the errant text).
As everything becomes more automated, ML will play an ever-increasing role in performing the mundane and repeatable elements of that automation. However, humans will also need to play an increasingly supervisory role. In the short term, it may actually appear that ML is replacing humans and putting them out of work, but in the long term, humans will simply perform different work. The current state of ML is akin to the disruption that occurred during the Industrial Revolution, where machines replaced humans in performing many manual tasks. Because of that particular disruption in the ways that things were done, a single farmer today can tend to hundreds of acres of land, and factory work is considerably safer. ML is important because it’s the next step toward making life better for people.
Identifying the ML security domain
Security doesn’t just entail the physical protection of data, which might actually be impossible for online sources such as websites where the data scientist obtains the data using screen-scraping techniques. To ensure that data remains secure, an organization must monitor and validate it prior to use for issues such as data corruption, bias, errors, and the like. When securing an ML application, it’s also essential to review issues such as these:
- Data bias: The data somehow favors a particular group or is skewed in a manner that produces an inaccurate analysis. Model errors give hackers a wedge into gaining access to the application, its model, or underlying data.
- Data corruption: The data may be complete, but some values are incorrect in a way that shows damage, poor formatting, or in a different form. For example, even in adding the correct state name to a dataset, such as Wisconsin, it could appear as WI, Wis, Wisc, Wisconsin, or some other legitimate, but different form.
- Missing critical data: Some data is simply absent from the dataset or could be replaced with a random value, or a placeholder such as N/A or Null for numeric entries.
- Errors in the data: The data is apparently present, but is incorrect in a manner that could cause the application to perform badly and cause the user to make bad decisions. Data errors are often the result of human data entry problems, rather than corruption caused by other sources, such as network errors. Hackers often introduce data errors that have a purpose, such as entering scripts in the place of values.
- Algorithm correctness: Using the incorrect algorithm will create output that doesn’t meet analysis goals, even when the underlying data is correct in every possible manner.
- Algorithm bias: The algorithm is designed in such a manner that it performs analysis incorrectly. This problem can also appear when weighting values are incorrect or the algorithm handles feedback values inappropriately. The bottom line is that the algorithm produces a result, but the result favors a particular group or outputs values that are skewed in some way.
- Repeatable and verifiable results: ML applications aren’t useful unless they can produce the same results on different systems and it’s possible to verify those results in some way (even if verification requires the use of manual methods).
ML applications are also vulnerable to various kinds of software attacks, some of which are quite subtle. All of these attacks are covered in detail starting in Chapter 3 of the book. However, here is an overview of the various attack types and a quick definition of each that you can use for now:
- Evasion: Bypassing the information security functionality built into a system.
- Poisoning: Injecting false information into the application’s data stream.
- Inference: Using data mining and analysis techniques to gain knowledge about the underlying dataset, and then using that knowledge to infer vulnerabilities in the associated application.
- Trojans: Employing various techniques to create code or data that looks legitimate, but is really designed to take over the application or manipulate specific components of it.
- Backdoors: Using system, application, or data stream vulnerabilities to gain access to the underlying system or application without providing the required security credentials.
- Espionage: Stealing classified, sensitive data or intellectual property to gain an advantage over a person, group, or organization to perform a personnel attack.
- Sabotage: Performing deliberate and malicious actions to disrupt normal processes, so that even if the data isn’t corrupted, biased, or damaged in some way, the underlying processes don’t interact with it correctly.
- Fraud: Relying on various techniques, such as phishing or communications from unknown sources, to undermine the system, application, or data security in a secretive manner. This level of access can allow for unauthorized or unpaid use of the application and influence ways in which the results are used, such as providing false election projections.
The target of such an attack may not even know that the attack compromised the ML application until the results demonstrate it (the Seeing the effect of bad data section of Chapter 10, Considering the Ramifications of Deepfakes, shows a visual example of how this can happen). In fact, issues such as bias triggered by external dataset corruption can prove so subtle that the ML application continues to function in a compromised state without anyone noticing at all. Many attacks, such as privacy attacks (see the article entitled Privacy Attacks on Machine Learning Models, at https://www.infoq.com/articles/privacy-attacks-machine-learning-models/), have a direct monetary motive, rather than simple disruption.
It’s also possible to use ML applications as the attack vector. Hackers employ the latest techniques, such as relying on ML applications to attack you to obtain better results, just as you do. The article entitled 7 Ways in Which Cybercriminals Use Machine Learning to Hack Your Business, at https://gatefy.com/blog/cybercriminals-use-machine-learning-hack-business/, describes just seven of the ways in which hackers use ML in their nefarious trade. You can bet that hackers use ML in several other ways, some of them unexpected and likely unknown for now.
Distinguishing between supervised and unsupervised
ML relies on a large number of algorithms, used in a variety of ways, to produce a useful result. However, it’s possible to categorize these approaches in three (or possibly four) different ways:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Some people add the fourth approach of semi-supervised learning, which is a combination of supervised and unsupervised learning. This section will only discuss the first three because they’re the most important in understanding ML.
Understanding supervised learning
Supervised learning is the most popular and easiest-to-use ML paradigm. In this case, data takes the form of an example and label pair. The algorithm builds a mapping function between the example and its label so that when it sees other examples, it can identify them based on this function. Figure 1.1 provides you with an overview of how this process works:

Figure 1.1 – Supervised learning relies on labeled examples to train the model
Supervised learning is often used for certain types of classification, such as facial recognition, and prediction, or how well an advertisement will perform based on past examples. This paradigm is susceptible to many attack vectors including someone sending data with the wrong labels or supplying data that is outside the model’s usage.
Understanding unsupervised learning
When working with unsupervised learning, the algorithm is fed a large amount of data (usually more than is required for supervised learning) and the algorithm uses various techniques to organize, group, or cluster the data. An advantage of unsupervised learning is that it doesn’t require labels: the majority of the data in the world is unlabeled. Most people consider unsupervised learning as data-driven, contrasted with supervised learning, which is task-driven. The underlying strategy is to look for patterns, as shown in Figure 1.2:
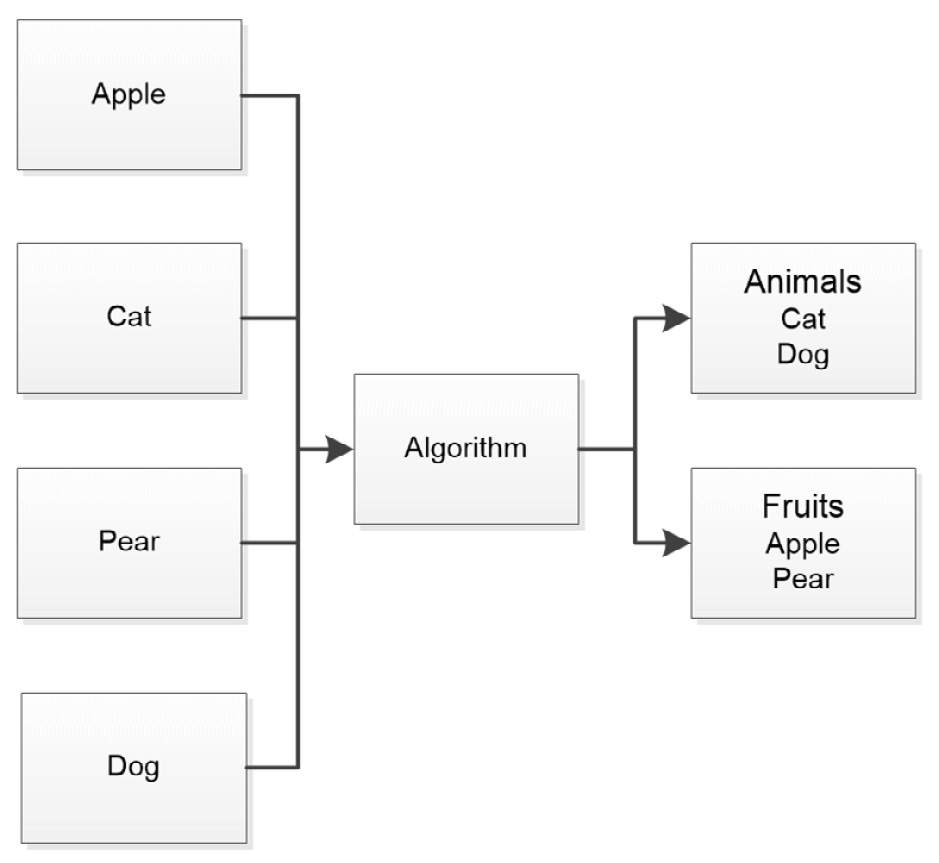
Figure 1.2 – Unsupervised learning groups or clusters like data together to train the model
Unsupervised learning is often used for recommender systems because such systems receive a constant stream of unlabeled data. You also find it used for tracking buying habits and grouping users into various categories. This paradigm is susceptible to a broad range of attack vectors, but data bias, data corruption, data errors, and missing data would be at the top of the list.
Understanding reinforcement learning
Reinforcement learning is essentially different from either supervised or unsupervised learning because it has a feedback loop element built into it. The best way to view reinforcement learning is as a methodology where ML can learn from mistakes. To produce this effect, an agent, the algorithm performing the task, has a specific list of actions that it can take to affect an environment. The environment, in turn, can produce one of two signals as a result of the action. The first signals successful task completion, which reinforces a behavior in the agent. The second provides an environment state so that the agent can detect where errors have occurred. Figure 1.3 shows how this kind of relationship works:
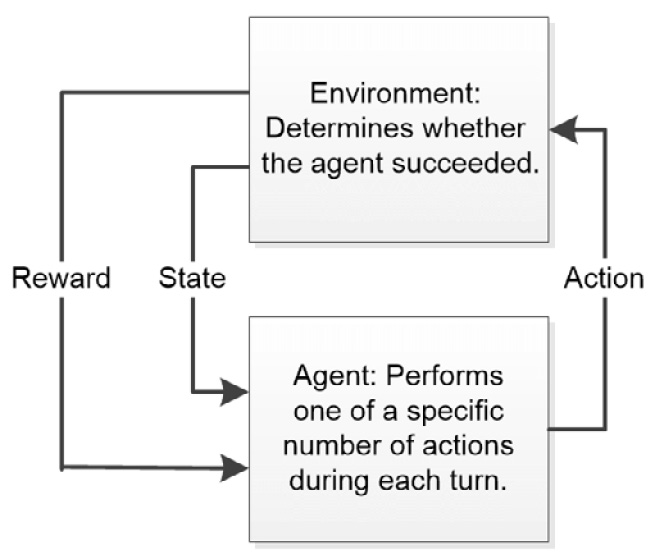
Figure 1.3 – Reinforcement learning is based on a system of rewards and an updated state
You often see reinforcement learning used for video games, simulations, and industrial processes. Because you’re linking two algorithms together, algorithm choice is a significant priority and anything that affects the relationship between the two algorithms has the potential to provide an attack vector. Feeding the agent incorrect state information will also cause this paradigm to fail.
Using ML from development to production
It’s essential to understand that ML does have an important role to fulfill today in performing specific kinds of tasks. Figure 1.4 contains a list of typical tasks that ML applications perform today, along with the learning type used to perform the task and observations of security and other issues associated with this kind of task. In no instance will you find that ML performs any task perfectly, especially without human assistance.


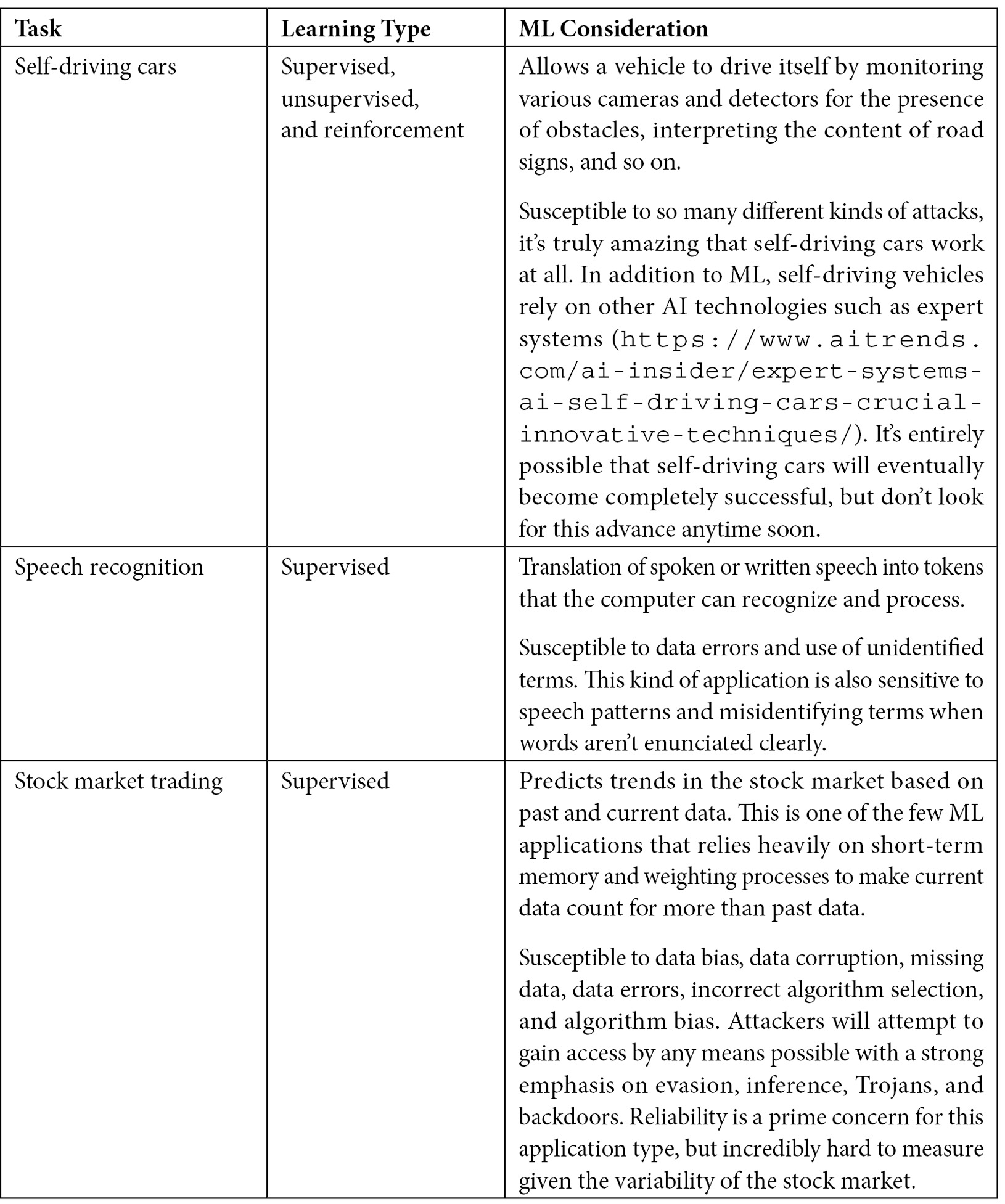

Figure 1.4 – ML tasks and their types
Figure 1.4 doesn’t contain some of the more exotic uses for ML. For example, some people use ML to generate art (see https://www.bbc.com/news/uk-england-oxfordshire-61600523 for one of the newest examples). However, the ML application isn’t creating art. What happens instead is that the ML application learns a particular art style from examples, and then transforms another graphic, such as a family picture, into a representation using the art examples. The results can be interesting, even beautiful, but they aren’t creative. The creativity resides in the original artist and the human guiding the generation (see https://aiartists.org/ai-generated-art-tools for details). The same technique applies to ML-generated music and even videos. Many of these alternative uses for ML are interesting, but the book doesn’t cover them heavily, except for the perspective of ethical treatment of data. So, why is security so important for ML projects? The next section begins to answer that question.











