






















































Gradient boosting is widely considered the most reliable and accurate algorithm for generic machine learning problems. We will utilize XGBoost to create malware detectors in future recipes.
Training an XGBoost classifier
Getting ready
The preparation for this recipe consists of installing the scikit-learn, pandas, and xgboost packages in pip. The command for this is as follows:
pip install sklearn xgboost pandas
In addition, a dataset named file_pe_header.csv is provided in the repository for this recipe.
How to do it...
In the following steps, we will demonstrate how to instantiate, train, and test an XGBoost classifier:
- Start by reading in the data:
import pandas as pd
df = pd.read_csv("file_pe_headers.csv", sep=",")
y = df["Malware"]
X = df.drop(["Name", "Malware"], axis=1).to_numpy()
- Next, train-test-split a dataset:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
- Create one instance of an XGBoost model and train it on the training set:
from xgboost import XGBClassifier
XGB_model_instance = XGBClassifier()
XGB_model_instance.fit(X_train, y_train)
- Finally, assess its performance on the testing set:
from sklearn.metrics import accuracy_score
y_test_pred = XGB_model_instance.predict(X_test)
accuracy = accuracy_score(y_test, y_test_pred)
print("Accuracy: %.2f%%" % (accuracy * 100))
The following screenshot shows the output:
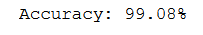
How it works...
We begin by reading in our data (step 1). We then create a train-test split (step 2). We proceed to instantiate an XGBoost classifier with default parameters and fit it to our training set (step 3). Finally, in step 4, we use our XGBoost classifier to predict on the testing set. We then produce the measured accuracy of our XGBoost model's predictions.





