






















































Histograms
Data exploration after a basic understanding can also be done with the aid of visualizations. Plotting a histogram is one of the most common ways of data exploration through visualization. A histogram type is used to tabulate data over a real plane separated into regular intervals.
A histogram is created using the fit method:
julia> fit(Histogram, data[, weight][, edges])
fit takes the following arguments:
data: Data is passed to thefitfunction in the form of a vector, which can either be one-dimensional or n-dimensional (tuple of vectors of equal length).weight: This is the optional argument. AWeightVectype can be passed as an argument if values have different weights. The default weight of values is 1.edges: This is a vector used to give the edges of the bins along each dimension.
It also takes a keyword argument, nbins, which is used to define the number of bins that the histogram should use along each side:
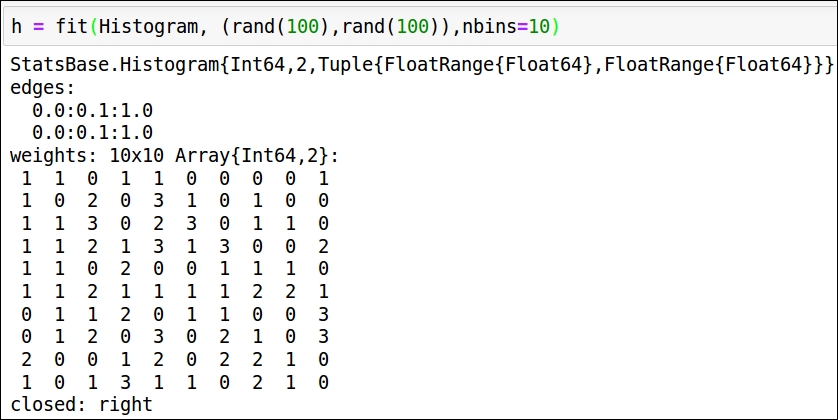
In this example, we used two random value generators...

