Eigen is a general-purpose linear algebra C++ library. In Eigen, all matrices and vectors are objects of the Matrix template class, and the vector is a specialization of the matrix type, with either one row or one column. Tensor objects are not presented in official APIs but exist as submodules.
We can define the type for a matrix with known dimensions and floating-point data type like this:
typedef Eigen::Matrix<float, 3, 3> MyMatrix33f;
We can define a vector in the following way:
typedef Eigen::Matrix<float, 3, 1> MyVector3f;
Eigen already has a lot of predefined types for vector and matrix objects—for example, Eigen::Matrix3f (floating-point 3x3 matrix type) or Eigen::RowVector2f (floating-point 1 x 2 vector type). Also, Eigen is not limited to matrices whose dimensions we know at compile time. We can define matrix types that will take the number of rows or columns at initialization during runtime. To define such types, we can use a special type variable for the Matrix class template argument named Eigen::Dynamic. For example, to define a matrix of doubles with dynamic dimensions, we can use the following definition:
typedef Eigen::Matrix<double, Eigen::Dynamic, Eigen::Dynamic> MyMatrix;
Objects initialized from the types we defined will look like this:
MyMatrix33f a;
MyVector3f v;
MyMatrix m(10,15);
To put some values into these objects, we can use several approaches. We can use special predefined initialization functions, as follows:
a = MyMatrix33f::Zero(); // fill matrix elements with zeros
a = MyMatrix33f::Identity(); // fill matrix as Identity matrix
v = MyVector3f::Random(); // fill matrix elements with random values
We can use the comma-initializer syntax, as follows:
a << 1,2,3,
4,5,6,
7,8,9;
This code construction initializes the matrix values in the following way:
We can use direct element access to set or change matrix coefficients. The following code sample shows how to use the () operator for such an operation:
a(0,0) = 3;
We can use the object of the Map type to wrap an existent C++ array or vector in the Matrix type object. This kind of mapping object will use memory and values from the underlying object, and will not allocate the additional memory and copy the values. The following snippet shows how to use the Map type:
int data[] = {1,2,3,4};
Eigen::Map<Eigen::RowVectorxi> v(data,4);
std::vector<float> data = {1,2,3,4,5,6,7,8,9};
Eigen::Map<MyMatrix33f> a(data.data());
We can use initialized matrix objects in mathematical operations. Matrix and vector arithmetic operations in the Eigen library are offered either through overloads of standard C++ arithmetic operators such as +, -, *, or through methods such as dot() and cross(). The following code sample shows how to express general math operations in Eigen:
using namespace Eigen;
auto a = Matrix2d::Random();
auto b = Matrix2d::Random();
auto result = a + b;
result = a.array() * b.array(); // element wise multiplication
result = a.array() / b.array();
a += b;
result = a * b; // matrix multiplication
//Also it’s possible to use scalars:
a = b.array() * 4;
Notice that in Eigen, arithmetic operators such as operator+ do not perform any computation by themselves. These operators return an expression object, which describes what computation to perform. The actual computation happens later when the whole expression is evaluated, typically in the operator= arithmetic operator. It can lead to some strange behaviors, primarily if a developer uses the auto keyword too frequently.
Sometimes, we need to perform operations only on a part of the matrix. For this purpose, Eigen provides the block method, which takes four parameters: i,j,p,q. These parameters are the block size p,q and the starting point i,j. The following code shows how to use this method:
Eigen::Matrixxf m(4,4);
Eigen::Matrix2f b = m.block(1,1,2,2); // copying the middle part of matrix
m.block(1,1,2,2) *= 4; // change values in original matrix
There are two more methods to access rows and columns by index, which are also a type of block operation. The following snippet shows how to use the col and the row methods:
m.row(1).array() += 3;
m.col(2).array() /= 4;
Another important feature of linear algebra libraries is broadcasting, and Eigen supports this with the colwise and rowwise methods. Broadcasting can be interpreted as a matrix by replicating it in one direction. Take a look at the following example of how to add a vector to each column of the matrix:
Eigen::Matrixxf mat(2,4);
Eigen::Vectorxf v(2); // column vector
mat.colwise() += v;
This operation has the following result: 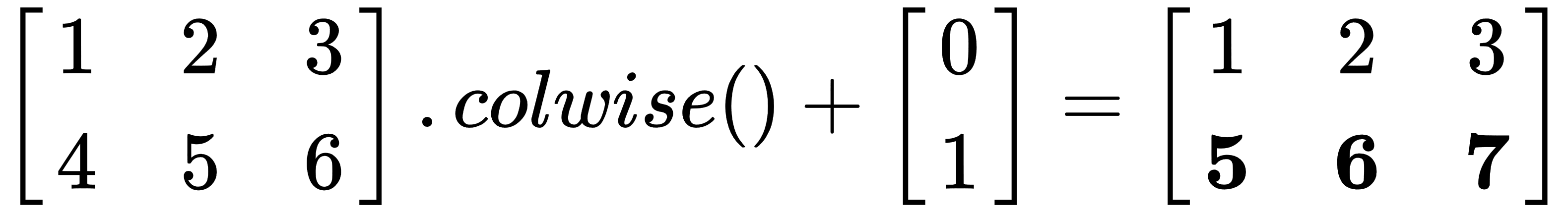 .
.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand




















