






















































Creating an evaluation
Evaluations and models are independent in Amazon ML. You can train a model and carry out several evaluations by specifying different evaluation datasets. The evaluation page, shown in the following screenshot, lets you name and specify how the model will be evaluated:
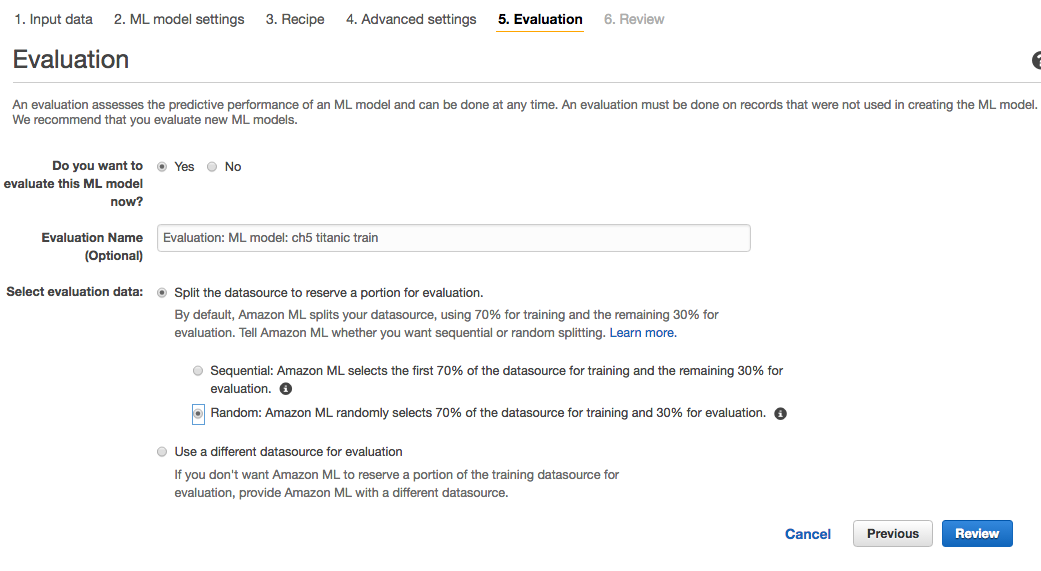
As you know by now, to evaluate a model, you need to split your dataset into two parts, the training and the evaluation sets with a 70/30 split. The training part is used to train your model, while the evaluation part is used to evaluate the model. At this point, you can let Amazon ML split the dataset into training and evaluation or specify a different datasource for evaluation.
Recall that the initial Titanic file was ordered by class and passenger alphabetical order. Using this ordered dataset and splitting it without shuffling, that is, taking sequentially the first 70% samples, would give the model a very different data for the training and the evaluation sets. The evaluation would not be relevant...


