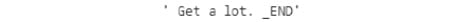Chapter 7: Foundations of LSTM
Activity 9: Build a Spam or Ham classifier using a Simple RNN
Solution:
- Import required Python packages
import pandas as pd
import numpy as np
from keras.models import Model, Sequential
from keras.layers import SimpleRNN, Dense,Embedding
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
- Read the input file containing a column that contains text and another column that contains the label for the text depicting whether the text is spam or not.
df = pd.read_csv("drive/spam.csv", encoding="latin")
df.head()
The output is as follows:

Figure 7.35: Input data file
- Label the columns in the input data.
df = df[["v1","v2"]]
df.head()
The output is as follows:

Figure 7.36: Labelled input data
- Count spam, ham characters in the v1 column.
df["v1"].value_counts()
The output is as follows:

Figure 7.37: Value counts for spam or ham
- Get X as feature and Y as target.
lab_map = {"ham":0, "spam":1}
X = df["v2"].values
Y = df["v1"].map(lab_map).values
- Convert to sequences and pad the sequences.
max_words = 100
mytokenizer = Tokenizer(nb_words=max_words,lower=True, split=" ")
mytokenizer.fit_on_texts(X)
text_tokenized = mytokenizer.texts_to_sequences(X)
text_tokenized
The output is as follows:

Figure 7.38: Tokenized data
- Train the sequences
max_len = 50
sequences = sequence.pad_sequences(text_tokenized,maxlen=max_len)
sequences
- Build the model
model = Sequential()
model.add(Embedding(max_words, 20, input_length=max_len))
model.add(SimpleRNN(64))
model.add(Dense(1, activation="sigmoid"))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(sequences,Y,batch_size=128,epochs=10,
validation_split=0.2)
- Predict the mail category on new test data.
inp_test_seq = "WINNER! U win a 500 prize reward & free entry to FA cup final tickets! Text FA to 34212 to receive award"
test_sequences = mytokenizer.texts_to_sequences(np.array([inp_test_seq]))
test_sequences_matrix = sequence.pad_sequences(test_sequences,maxlen=max_len)
model.predict(test_sequences_matrix)
The output is as follows:
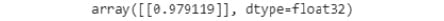
Figure 7.39: Output for new test data
Activity 10: Create a French to English translation model
Solution:
- Import the necessary Python packages and classes.
import os
import re
import numpy as np
- Read the file in sentence pairs.
with open("fra.txt", 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
num_samples = 20000 # Using only 20000 pairs for this example
lines_to_use = lines[: min(num_samples, len(lines) - 1)]
- Remove \u202f character
for l in range(len(lines_to_use)):
lines_to_use[l] = re.sub("\u202f", "", lines_to_use[l])
for l in range(len(lines_to_use)):
lines_to_use[l] = re.sub("\d", " NUMBER_PRESENT ", lines_to_use[l])
- Append 'BEGIN_ ' and ' _END' words to target sequences. Map words to integers.
input_texts = []
target_texts = []
input_words = set()
target_words = set()
for line in lines_to_use:
target_text, input_text = line.split('\t')
target_text = 'BEGIN_ ' + target_text + ' _END'
input_texts.append(input_text)
target_texts.append(target_text)
for word in input_text.split():
if word not in input_words:
input_words.add(word)
for word in target_text.split():
if word not in target_words:
target_words.add(word)
max_input_seq_length = max([len(i.split()) for i in input_texts])
max_target_seq_length = max([len(i.split()) for i in target_texts])
input_words = sorted(list(input_words))
target_words = sorted(list(target_words))
num_encoder_tokens = len(input_words)
num_decoder_tokens = len(target_words)
- Define encoder-decoder inputs.
input_token_index = dict(
[(word, i) for i, word in enumerate(input_words)])
target_token_index = dict(
[(word, i) for i, word in enumerate(target_words)])
encoder_input_data = np.zeros(
(len(input_texts), max_input_seq_length),
dtype='float32')
decoder_input_data = np.zeros(
(len(target_texts), max_target_seq_length),
dtype='float32')
decoder_target_data = np.zeros(
(len(target_texts), max_target_seq_length, num_decoder_tokens),
dtype='float32')
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, word in enumerate(input_text.split()):
encoder_input_data[i, t] = input_token_index[word]
for t, word in enumerate(target_text.split()):
decoder_input_data[i, t] = target_token_index[word]
if t > 0:
# decoder_target_data is ahead of decoder_input_data #by one timestep
decoder_target_data[i, t - 1, target_token_index[word]] = 1.
- Build the model.
from keras.layers import Input, LSTM, Embedding, Dense
from keras.models import Model
embedding_size = 50
- Initiate encoder training.
encoder_inputs = Input(shape=(None,))
encoder_after_embedding = Embedding(num_encoder_tokens, embedding_size)(encoder_inputs)
encoder_lstm = LSTM(50, return_state=True)_,
state_h, state_c = encoder_lstm(encoder_after_embedding)
encoder_states = [state_h, state_c]
- Initiate decoder training.
decoder_inputs = Input(shape=(None,))
decoder_after_embedding = Embedding(num_decoder_tokens, embedding_size)(decoder_inputs)
decoder_lstm = LSTM(50, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_after_embedding,
initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
- Define the final model.
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc'])
model.fit([encoder_input_data, decoder_input_data],
decoder_target_data,
batch_size=128,
epochs=20,
validation_split=0.05)
- Provide inferences to encoder and decoder
# encoder part
encoder_model = Model(encoder_inputs, encoder_states)
# decoder part
decoder_state_input_h = Input(shape=(50,))
decoder_state_input_c = Input(shape=(50,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs_inf, state_h_inf, state_c_inf = decoder_lstm(decoder_after_embedding, initial_state=decoder_states_inputs)
decoder_states_inf = [state_h_inf, state_c_inf]
decoder_outputs_inf = decoder_dense(decoder_outputs_inf)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs_inf] + decoder_states_inf)
- Reverse-lookup token index to decode sequences
reverse_input_word_index = dict(
(i, word) for word, i in input_token_index.items())
reverse_target_word_index = dict(
(i, word) for word, i in target_token_index.items())
def decode_sequence(input_seq):
- Encode input as a state vector
states_value = encoder_model.predict(input_seq)
- Generate empty target sequence of length 1.
target_seq = np.zeros((1,1))
- Populate the first character of target sequence with the start character.
target_seq[0, 0] = target_token_index['BEGIN_']
- Sampling loop for a batch of sequences
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
- Sample a token.
sampled_token_index = np.argmax(output_tokens)
sampled_word = reverse_target_word_index[sampled_token_index]
decoded_sentence += ' ' + sampled_word
- Exit condition: either hit max length or find stop character.
if (sampled_word == '_END' or
len(decoded_sentence) > 60):
stop_condition = True
- Update the target sequence (of length 1).
target_seq = np.zeros((1,1))
target_seq[0, 0] = sampled_token_index
- Update states
states_value = [h, c]
return decoded_sentence
- Inference for user input: take in a word sequence, convert the sequence word by word into encoded.
text_to_translate = "Où est ma voiture??"
encoder_input_to_translate = np.zeros(
(1, max_input_seq_length),
dtype='float32')
for t, word in enumerate(text_to_translate.split()):
encoder_input_to_translate[0, t] = input_token_index[word]
decode_sequence(encoder_input_to_translate)
The output is as follows: