






















































Distance measure
The clustering problem is based on evaluating the distance between data points. The distance measure is an indicator of the similarity of the data points. For any clustering algorithm, you need to make a decision on the appropriate distance measure for your context. Essentially, the distance measure is more important for accuracy than the number of clusters.
Further, the criteria for choosing the right distance measure depends on the application domain and the dataset, so it is important to understand the different distance measures available in Apache Mahout. A few important distance measures are explained in the following section. The distance measure is visualized using a two-dimensional visualization here.
The Euclidean distance is not suitable if the magnitude of possible values for each feature varies drastically (if all the features need to be assessed equally):
|
Euclidean distance | |
|---|---|
|
Class |
|
|
Formula |
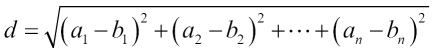 |
 | |
Squared...

