






















































Migrating Containerized Application to Kubernetes
In the previous chapter, we built a simple HTTP server called k8s-for-beginners, and it runs as a Docker container. It works perfectly for a sample application. However, what if you have to manage thousands of containers, and coordinate and schedule them properly? How can you upgrade a service without downtime? How do you keep a service healthy upon unexpected failure? These problems exceed the abilities of a system that simply uses containers alone. What we need is a platform that can orchestrate, as well as manage, our containers.
We have told you that Kubernetes is the solution that we need. Next, we will walk you through a series of exercises regarding how to orchestrate and run containers in Kubernetes using a Kubernetes native approach.
Pod Specification
A straightforward thought is that we wish to see what the equivalent API call or command to run a container in Kubernetes is. As explained in Chapter 1, Introduction to Kubernetes and Containers, a container can join another container's namespace so that they can access each other's resources (for example, network, storage, and so on) without additional overhead. In the real world, some applications may need several containers working closely, either in parallel or in a particular order (the output of one will be processed by another). Also, some generic containers (for example, logging agent, network throttling agent, and so on) may need to work closely with their target containers.
Since an application may often need several containers, a container is not the minimum operational unit in Kubernetes; instead, it introduces a concept called pods to bundle one or multiple containers. Kubernetes provides a series of specifications to describe how this pod is supposed to be, including several specifics such as images, resource requests, startup commands, and more. To send this pod spec to Kubernetes, particularly to the Kubernetes API server, we're going to use kubectl.
Note
We will learn more about pods in Chapter 5, Pods, but we will use them in this chapter for the purpose of simple demonstrations. You can refer to the complete list of available pod specifications at this link: https://godoc.org/k8s.io/api/core/v1#PodSpec.
Next, let's learn how to run a single container in Kubernetes by composing the pod spec file (also called the specification, manifest, config, or configuration file). In Kubernetes, you can use YAML or JSON to write this specification file, though YAML is commonly used since it is more human-readable and editable.
Consider the following YAML spec for a very simple pod:
kind: Pod apiVersion: v1 metadata: name: k8s-for-beginners spec: containers: - name: k8s-for-beginners image: packtworkshops/the-kubernetes-workshop:k8s-for-beginners
Let's go through the different fields briefly:
kindtells Kubernetes which type of object you want to create. Here, we are creating aPod. In later chapters, you will see many other kinds, such as Deployment, StatefulSet, ConfigMap, and so on.apiVersionspecifies a particular version of an API object. Different versions may behave a bit differently.metadataincludes some attributes that can be used to uniquely identify the pod, such as name and namespace. If we don't specify a namespace, it goes in thedefaultnamespace.speccontains a series of fields describing the pod. In this example, there is one container that has its image URL and name specified.
Pods are one of the simplest Kubernetes objects to deploy, so we will use them to learn how to deploy objects using YAML manifests in the following exercise.
Applying a YAML Manifest
Once we have a YAML manifest ready, we can use kubectl apply -f <yaml file> or kubectl create -f <yaml file> to instruct the API server to persist the API resources defined in this manifest. When you create a pod from scratch for the first time, it doesn't make much difference which of the two commands you use. However, we may often need to modify the YAML (let's say, for example, if we want to upgrade the image version) and reapply it. If we use the kubectl create command, we have to delete and recreate it. However, with the kubectl apply command, we can rerun the same command and the delta change will be calculated and applied automatically by Kubernetes.
This is very convenient from an operational point of view. For example, if we use some form of automation, it is much simpler to repeat the same command. So, we will use kubectl apply across the following exercise, regardless of whether it's the first time it's being applied or not.
Note
A detailed on kubectl can be obtained in Chapter 4, How to Communicate with Kubernetes (API Server).
Exercise 2.02: Running a Pod in Kubernetes
In the previous exercise, we started up Minikube and looked at the various Kubernetes components running as pods. Now, in this exercise, we shall deploy our pod. Follow these steps to complete this exercise:
Note
If you have been trying out the commands from the Kubernetes Components Overview section, don't forget to leave the SSH session by using the exit command before beginning this exercise. Unless otherwise specified, all commands using kubectl should run on the host machine and not inside the Minikube VM.
- In Kubernetes, we use a spec file to describe an API object such as a pod. As mentioned earlier, we will stick to YAML as it is more human-readable and editable friendly. Create a file named
k8s-for-beginners-pod.yaml(using any text editor of your choice) with the following content:kind: Pod apiVersion: v1 metadata: name: k8s-for-beginners spec: containers: - name: k8s-for-beginners image: packtworkshops/the-kubernetes-workshop:k8s-for- beginners
Note
Please replace the image path in the last line of the preceding YAML file with the path to your image that you created in the previous chapter.
- On the host machine, run the following command to create this pod:
kubectl apply -f k8s-for-beginners-pod.yaml
You should see the following output:
pod/k8s-for-beginners created
- Now, we can use the following command to check the pod's status:
kubectl get pod
You should see the following response:
NAME READY STATUS RESTARTS AGE k8s-for-beginners 1/1 Running 0 7s
By default,
kubectl get podwill list all the pods using a table format. In the preceding output, we can see thek8s-for-beginnerspod is running properly and that it has one container that is ready (1/1). Moreover, kubectl provides an additional flag called-oso we can adjust the output format. For example,-o yamlor-o jsonwill return the full output of the pod API object in YAML or JSON format, respectively, as it's stored version in Kubernetes' backend storage (etcd). - You can use the following command to get more information about the pod:
kubectl get pod -o wide
You should see the following output:

Figure 2.9: Getting more information about pods
As you can see, the output is still in the table format and we get additional information such as
IP(the internal pod IP) andNODE(which node the pod is running on). - You can get the list of nodes in our cluster by running the following command:
kubectl get node
You should see the following response:
NAME STATUS ROLES AGE VERSION minikube Ready master 30h v1.16.2
- The IP listed in Figure 2.9 refers to the internal IP Kubernetes assigned for this pod, and it's used for pod-to-pod communication, not for routing external traffic to pods. Hence, if you try to access this IP from outside the cluster, you will get nothing. You can try that using the following command from the host machine, which will fail:
curl 172.17.0.4:8080
Note
Remember to change
172.17.0.4to the value you get for your environment in step 4, as seen in Figure 2.9.The
curlcommand will just hang and return nothing, as shown here:k8suser@ubuntu:~$ curl 172.17.0.4:8080 ^C
You will need to press Ctrl + C to abort it.
- In most cases, end-users don't need to interact with the internal pod IP. However, just for observation purposes, let's SSH into the Minikube VM:
minikube ssh
You will see the following response in the terminal:

Figure 2.10: Accessing the Minikube VM via SSH
- Now, try calling the IP from inside the Minikube VM to verify that it works:
curl 172.17.0.4:8080
You should get a successful response:
Hello Kubernetes Beginners!
With this, we have successfully deployed our application in a pod on the Kubernetes cluster. We can confirm that it is working since we get a response when we call the application from inside the cluster. Now, you may end the Minikube SSH session using the exit command.
Service Specification
The last part of the previous section proves that network communication works great among different components inside the cluster. But in the real world, you would not expect users of your application to gain SSH access into your cluster to use your applications. So, you would want your application to be accessed externally.
To facilitate just that, Kubernetes provides a concept called a Service to abstract the network access to your application's pods. A Service acts as a network proxy to accept network traffic from external users and then distributes it to internal pods. However, there should be a way to describe the association rule between the Service and the corresponding pods. Kubernetes uses labels, which are defined in the pod definitions, and label selectors, which are defined in the Service definition, to describe this relationship.
Note
You will learn more about labels and label selectors in Chapter 6, Labels and Annotations.
Let's consider the following sample spec for a Service:
kind: Service apiVersion: v1 metadata: name: k8s-for-beginners spec: selector: tier: frontend type: NodePort ports: - port: 80 targetPort: 8080
Similar to a pod spec, here, we define kind and apiVersion, while name is defined under the metadata field. Under the spec field, there are several critical fields to take note of:
selectordefines the labels to be selected to match a relationship with the corresponding pods, which, as you will see in the following exercise, are supposed to be labeled properly.typedefines the type of Service. If not specified, the default type isClusterIP, which means it's only used within the cluster, that is, internally. Here, we specify it asNodePort. This means the Service will expose a port in each node of the cluster and associate the port with the corresponding pods. Another well-known type is calledLoadBalancer, which is typically not implemented in a vanilla Kubernetes offering. Instead, Kubernetes delegates the implementation to each cloud provider, such as GKE, EKS, and so on.portsinclude a series ofportfields, each with atargetPortfield. ThetargetPortfield is the actual port that's exposed by the destination pod.Thus, the Service can be accessed internally via
<service ip>:<port>. Now, for example, if you have an NGINX pod running internally and listening on port 8080, then you should definetargetPortas8080. You can specify any arbitrary number for theportfield, such as80in this case. Kubernetes will set up and maintain the mapping between<service IP>:<port>and<pod IP>:<targetPort>. In the following exercise, we will learn how to access the Service from outside the cluster and bring external traffic inside the cluster via the Service.
In the following exercise, we will define Service manifests and create them using kubectl apply commands. You will learn that the common pattern for resolving problems in Kubernetes is to find out the proper API objects, then compose the detailed specs using YAML manifests, and finally create the objects to bring them into effect.
Exercise 2.03: Accessing a Pod via a Service
In the previous exercise, we observed that an internal pod IP doesn't work for anyone outside the cluster. In this exercise, we will create Services that will act as connectors to map the external requests to the destination pods so that we can access the pods externally without entering the cluster. Follow these steps to complete this exercise:
- Firstly, let's tweak the pod spec from Exercise 2.02, Running a Pod in Kubernetes, to apply some labels. Modify the contents of the
k8s-for-beginners-pod1.yamlfile, as follows:kind: Pod apiVersion: v1 metadata: name: k8s-for-beginners labels: tier: frontend spec: containers: - name: k8s-for-beginners image: packtworkshops/the-kubernetes-workshop:k8s-for- beginners
Here, we added a label pair,
tier: frontend, under thelabelsfield. - Because the pod name remains the same, let's rerun the
applycommand so that Kubernetes knows that we're trying to update the pod's spec, instead of creating a new pod:kubectl apply -f k8s-for-beginners-pod1.yaml
You should see the following response:
pod/k8s-for-beginners configured
Behind the scenes, for the
kubectl applycommand, kubectl generates the difference of the specified YAML and the stored version in the Kubernetes server-side storage (that is, etcd). If the request is valid (that is, we have not made any errors in the specification format or the command), kubectl will send an HTTP patch to the Kubernetes API server. Hence, only the delta changes will be applied. If you look at the message that's returned, you'll see it sayspod/k8s-for-beginners configuredinstead ofcreated, so we can be sure it's applying the delta changes and not creating a new pod. - You can use the following command to explicitly display the labels that have been applied to existing pods:
kubectl get pod --show-labels
You should see the following response:
NAME READY STATUS RESTARTS AGE LABELS k8s-for-beginners 1/1 Running 0 16m tier=frontend
Now that the pod has the
tier: frontendattribute, we're ready to create a Service and link it to the pods. - Create a file named
k8s-for-beginners-svc.yamlwith the following content:kind: Service apiVersion: v1 metadata: name: k8s-for-beginners spec: selector: tier: frontend type: NodePort ports: - port: 80 targetPort: 8080
- Now, let's create the Service using the following command:
kubectl apply -f k8s-for-beginners-svc.yaml
You should see the following response:
service/k8s-for-beginners created
- Use the
getcommand to return the list of created Services and confirm whether our Service is online:kubectl get service
You should see the following response:

Figure 2.11: Getting the list of Services
So, you may have noticed that the
PORT(S)column outputs80:32571/TCP. Port32571is an auto-generated port that's exposed on every node, which is done intentionally so that external users can access it. Now, before moving on to the next step, exit the SSH session. - Now, we have the "external port" as
32571, but we still need to find the external IP. Minikube provides a utility we can use to easily access thek8s-for-beginnersService:minikube service k8s-for-beginners
You should see a response that looks similar to the following:

Figure 2.12: Getting the URL and port to access the NodePort Service
Depending on your environment, this may also automatically open a browser web page so you can access the Service. From the URL, you will be able to see that the Service port is
32571. The external IP is actually the IP of the Minikube VM. - You can also access our application from outside the cluster via the command line:
curl http://192.168.99.100:32571
You should see the following response:
Hello Kubernetes Beginners!
As a summary, in this exercise, we created a NodePort Service to enable external users to access the internal pods without entering the cluster. Under the hood, there are several layers of traffic transitions that make this happen:
- The first layer is from the external user to the machine IP at the auto-generated random port (3XXXX).
- The second layer is from the random port (3XXXX) to the Service IP (10.X.X.X) at port
80. - The third layer is from the Service IP (10.X.X.X) ultimately to the pod IP at port
8080.
The following is a diagram illustrating these interactions:
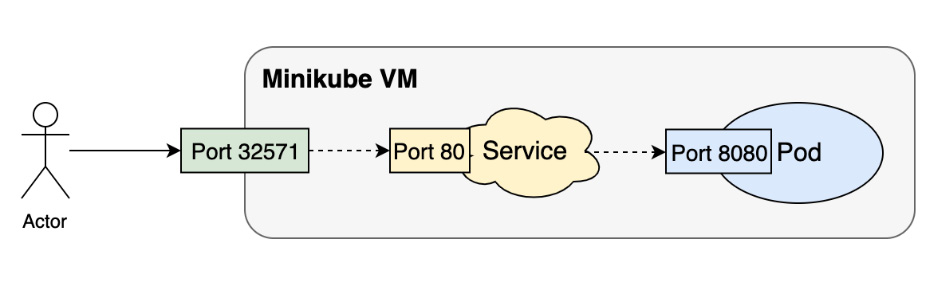
Figure 2.13: Routing traffic from a user outside the cluster to the pod running our application
Services and Pods
In step 3 of the previous exercise, you may have noticed that the Service tries to match pods by labels (the selector field under the spec section) instead of using a fixed pod name or something similar. From a pod's perspective, it doesn't need to know which Service is bringing traffic to it. (In some rare cases, it can even be mapped to multiple Services; that is, multiple Services may be sending traffic to a pod.)
This label-based matching mechanism is widely used in Kubernetes. It enables the API objects to be loosely coupled at runtime. For example, you can specify tier: frontend as the label selector, which will, in turn, be associated with the pods that are labeled as tier: frontend.
Due to this, by the time the Service is created, it doesn't matter if the backing pods exist or not. It's totally acceptable for backing pods to be created later, and after they are created, the Service object will become associated with the correct pods. Internally, the whole mapping logic is implemented by the service controller, which is part of the controller manager component. It's also possible that a Service may have two matching pods at a time, and later a third pod is created with matching labels, or one of the existing pods gets deleted. In either case, the service controller can detect such changes and ensure that users can always access their application via the Service endpoint.
It's a very commonly used pattern in Kubernetes to orchestrate your application using different kinds of API objects and then glue them together by using labels or other loosely coupled conventions. It's also the key part of container orchestration.






















