






















































Kubernetes Components Overview
By completing the previous exercise, you have a single-node Kubernetes cluster up and running. Before playing your first concert, let's hold on a second and pull the curtains aside to take a look backstage to see how Kubernetes is architected behind the scenes, and then check how Minikube glues its various components together inside its VM.
Kubernetes has several core components that make the wheels of the machine turn. They are as follows:
- API server
- etcd
- Controller manager
- Scheduler
- Kubelet
These components are critical for the functioning of a Kubernetes cluster.
Besides these core components, you would deploy your applications in containers, which are bundled together as pods. We will learn more about pods in Chapter 5, Pods. These pods, and several other resources, are defined by something called API objects.
An API object describes how a certain resource should be honored in Kubernetes. We usually define API objects using a human-readable manifest file, and then use a tool (such as kubectl) to parse it and hand it over to a Kubernetes API server. Kubernetes then tries to create the resource specified in the object and match its state to the desired state in the object definition, as mentioned in the manifest file. Next, we will walk you through how these components are organized and behave in a single-node cluster created by Minikube.
Minikube provides a command called minikube ssh that's used to gain SSH access from the host machine (in our machine, it's the physical machine running Ubuntu 20.04) to the minikube virtual machine, which serves as the sole node in our Kubernetes cluster. Let's see how that works:
minikube ssh
You will see the following output:
Figure 2.5: Accessing the Minikube VM via SSH
Note
All the commands that will be shown later in this section are presumed to have been run inside the Minikube VM, after running minikube ssh.
Container technology brings the convenience of encapsulating your application. Minikube is no exception – it leverages containers to glue the Kubernetes components together. In the Minikube VM, Docker is pre-installed so that it can manage the core Kubernetes components. You can take a look at this by running docker ps; however, the result may be overwhelming as it includes all the running containers – both the core Kubernetes components and add-ons, as well as all the columns – which will output a very large table.
To simplify the output and make it easier to read, we will pipe the output from docker ps into two other Bash commands:
grep -v pause: This will filter the results by not displaying the "sandbox" containers.Without
grep -v pause, you would find that each container is "paired" with a "sandbox" container (in Kubernetes, it's implemented as apauseimage). This is because, as mentioned in the previous chapter, Linux containers can be associated (or isolated) by joining the same (or different) Linux namespace. In Kubernetes, a "sandbox" container is used to bootstrap a Linux namespace, and then the containers that run the real application are able to join that namespace. Finer details about how all this works under the hood have been left out of scope for the sake of brevity.Note
If not specified explicitly, the term "namespace" is used interchangeably with "Kubernetes namespace" across this book. In terms of "Linux namespace", "Linux" would not be omitted to avoid confusion.
awk '{print $NF}': This will only print the last column with a container name.Thus, the final command is as follows:
docker ps | grep -v pause | awk '{print $NF}'You should see the following output:

Figure 2.6: Getting the list of containers by running the Minikube VM
The highlighted containers shown in the preceding screenshot are basically the core components of Kubernetes. We'll discuss each of these in detail in the following sections.
etcd
A distributed system may face various kinds of failures (network, storage, and so on) at any moment. To ensure it still works properly when failures arise, critical cluster metadata and state must be stored in a reliable way.
Kubernetes abstracts the cluster metadata and state as a series of API objects. For example, the node API object represents a Kubernetes worker node's specification, as well as its latest status.
Kubernetes uses etcd as the backend key-value database to persist the API objects during the life cycle of a Kubernetes cluster. It is important to note that nothing (internal cluster resources or external clients) is allowed to talk to etcd without going through the API server. Any updates to or requests from etcd are made only via calls to the API server.
In practice, etcd is usually deployed with multiple instances to ensure the data is persisted in a secure and fault-tolerant manner.
API Server
The API server allows standard APIs to access Kubernetes API objects. It is the only component that talks to backend storage (etcd).
Additionally, by leveraging the fact that it is the single point of contact for communicating to etcd, it provides a convenient interface for clients to "watch" any API objects that they may be interested in. Once the API object has been created, updated, or deleted, the client that is "watching" will get instant notifications so they can act upon those changes. The "watching" client is also known as the "controller", which has become a very popular entity that's used in both built-in Kubernetes objects and Kubernetes extensions.
Note
You will learn more about the API server in Chapter 4, How to Communicate with Kubernetes (API Server), and about controllers in Chapter 7, Kubernetes Controllers.
Scheduler
The scheduler is responsible for distributing the incoming workloads to the most suitable node. The decision regarding distribution is made by the scheduler's understanding of the whole cluster, as well as a series of scheduling algorithms.
Note
You will learn more about the scheduler in Chapter 17, Advanced Scheduling in Kubernetes.
Controller Manager
As we mentioned earlier in the API Server subsection, the API server exposes ways to "watch" almost any API object and notify the watchers about the changes in the API objects being watched.
It works pretty much like a Publisher-Subscriber pattern. The controller manager acts as a typical subscriber and watches the only API objects that it is interested in, and then attempts to make appropriate changes to move the current state toward the desired state described in the object.
For example, if it gets an update from the API server saying that an application claims two replicas, but right now there is only one living in the cluster, it will create the second one to make the application adhere to its desired replica number. The reconciliation process keeps running across the controller manager's life cycle to ensure that all applications stay in their expected state.
The controller manager aggregates various kinds of controllers to honor the semantics of API objects, such as Deployments and Services, which we will introduce later in this chapter.
Where Is the kubelet?
Note that etcd, the API server, the scheduler, and the controller manager comprise the control plane of Kubernetes. A machine that runs these components is called a master node. The kubelet, on the other hand, is deployed on each worker machine.
In our single-node Minikube cluster, the kubelet is deployed on the same node that carries the control plane components. However, in most production environments, it is not deployed on any of the master nodes. We will learn more about production environments when we deploy a multi-node cluster in Chapter 11, Build Your Own HA Cluster.
The kubelet primarily aims at talking to the underlying container runtime (for example, Docker, containerd, or cri-o) to bring up the containers and ensure that the containers are running as expected. Also, it's responsible for sending the status update back to the API server.
However, as shown in the preceding screenshot, the docker ps command doesn't show anything named kubelet. To start, stop, or restart any software and make it auto-restart upon failure, usually, we need a tool to manage its life cycle. In Linux, systemd has that responsibility. In Minikube, the kubelet is managed by systemd and runs as a native binary instead of a Docker container. We can run the following command to check its status:
systemctl status kubelet
You should see an output similar to the following:
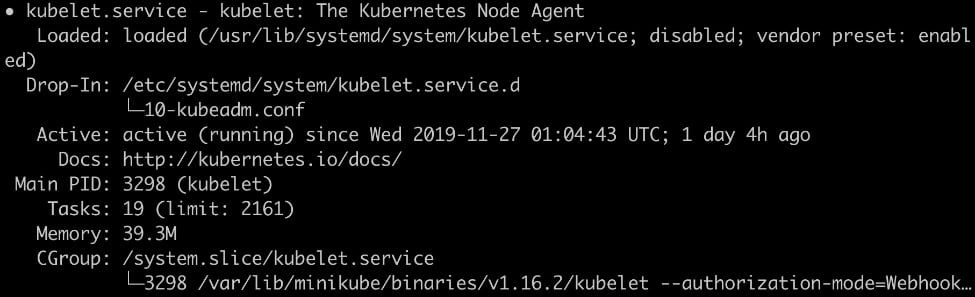
Figure 2.7: Status of kubelet
By default, the kubelet has the configuration for staticPodPath in its config file (which is stored at /var/lib/kubelet/config.yaml). kubelet is instructed to continuously watch the changes in files under that path, and each file under that path represents a Kubernetes component. Let's understand what this means by first finding staticPodPath in the kubelet's config file:
grep "staticPodPath" /var/lib/kubelet/config.yaml
You should see the following output:
staticPodPath: /etc/kubernetes/manifests
Now, let's see the contents of this path:
ls /etc/kubernetes/manifests
You should see the following output:
addon-manager.yaml.tmpl kube-apiserver.yaml kube-scheduler.yaml etcd.yaml kube-controller-manager.yaml
As shown in the list of files, the core components of Kubernetes are defined by objects that have a definition specified in YAML files. In the Minikube environment, in addition to managing the user-created pods, the kubelet also serves as a systemd equivalent in order to manage the life cycle of Kubernetes system-level components, such as the API server, the scheduler, the controller manager, and other add-ons. Once any of these YAML files is changed, the kubelet auto-detects that and updates the state of the cluster so that it matches the desired state defined in the updated YAML configuration.
We will stop here without diving deeper into the design of Minikube. In addition to "static components", the kubelet is also the manager of "regular applications" to ensure that they're running as expected on the node and evicts pods according to the API specification or upon resource shortage.
kube-proxy
kube-proxy appears in the output of the docker ps command, but it was not present at /etc/kubernetes/manifests when we explored that directory in the previous subsection. This implies its role – it's positioned more as an add-on component instead of a core one.
kube-proxy is designed as a distributed network router that runs on every node. Its ultimate goal is to ensure that inbound traffic to a Service (this is an API object that we will introduce later) endpoint can be routed properly. Moreover, if multiple containers are serving one application, it is able to balance the traffic in a round-robin manner by leveraging the underlying Linux iptables/IPVS technology.
There are also some other add-ons such as CoreDNS, though we will skip those so that we can focus on the core components and get a high-level picture.
Note
Sometimes, kube-proxy and CoreDNS are also considered core components of a Kubernetes installation. To some extent, that's technically true as they're mandatory in most cases; otherwise, the Service API object won't work. However, in this book, we're leaning more toward categorizing them as "add-ons" as they focus on the implementation of one particular Kubernetes API resource instead of general workflow. Also, kube-proxy and CoreDNS are defined in addon-manager.yaml.tmpl instead of being portrayed on the same level as the other core Kubernetes components.






















